커뮤니케이션의 효율성은 화자가 전달하고자 하는 메시지의 의미와 의도를 청자가 얼마나 쉽고 빠르고 정확하게 이해할 수 있는 지에 달려있다. 이를 위해서는 우선 최대한 정확한 의미를 가지는 어휘가 사용되어야 할 것이며, 해당 어휘들이 적절한 문법적 단서들을 포함하고 있어야 할 뿐 아니라, 문장 속에서 적절한 순서로 배열되어야 한다. 이 중 어휘들이 적절한 순서로 배열되는 것에 해당하는 “어순(word order)”의 문제는 해당 언어의 어순이 얼마나 자유로운지에 따라서 그 위상이 달라질 수 있다. 예를 들어, 영어와 같이 어순(word order)이 문법적 기능을 가지는 언어에서는 단어의 위치를 바꾸는 것 자체로 (1b)와 같이 문장의 문법성이 저해되거나
(1c)와 같이 문장이 전달하는 의미 자체가 달라진다.
(1) (a) A dog bit a man yesterday.
(b) *A dog a man yesterday bit.
(c) A man bit a dog yesterday.
그러나 한국어는 동사가 문장의 마지막에 위치하는 핵어 후치(head-final) 언어로, 술어를 제외한 주어, 논항, 부가어에 문법 기능을 나타내는 격조사 혹은 후치사가 첨가되기 때문에 문장 성분들의 위치에 대한 제약이 비교적 약한, 자유로운 어순을 허용하는 언어로 알려져 있다(Jee, 1994; Lee, Song, Lee, & Cho, 2004; Nam & Ko, 1997; Song, 1993; Song & Cho, 2001) 즉, (2)와 같이 어순이 달라진다고 하더라도 문법적으로 틀린 문장이 되거나 전달하고자 하는 문장의 의미에 심한 훼손이 발생하지 않는다.
(2) (a) 어제 개가 사람을 물었다.
(b) 어제 사람을 개가 물었다.
(c) 물었다 개가 사람을 어제.
하지만 자유로운 어순이 허용된다고 해서 해당 언어 사용자들의 마음속에 규범 어순(canonical word order)이 존재하지 않는 것은 아니다(Comrie, 1981). 한국어에서도 (2b)와 같이 목적어가 주어에 선행하는 문장(OSV)보다는 주어, 목적어, 동사(SOV)로 배열된 어순(2a)이 선호된다(Dennison & Schafer, 2008; Jackson, 2008; Kim, 2019). 즉, 논리적으로는 동일한 의미를 가진다고 할지라도 이것이 상이한 어순으로 실현되는 경우, 이들에 대한 어순 선호의 차원 및 언어 수행(언어 산출 및 이해)의 차원에서는 차이가 있을 수 있다. 따라서 어떤 어순이 실제로 언어 산출 및 이해의 과정에서 커뮤니케이션 당사자에게 유의미한 방식으로 영향을 미치는지를 경험적으로 확인하고, 해당 어순이 선호되는 이유가 무엇인지를 밝혀내는 것은 언어 커뮤니케이션 연구의 핵심적인 과제에 해당한다.
이러한 노력의 일환으로 한국어 사용자의 심리적 실재성(psychological reality)이 확인된 대표적인 어순 선호 현상 중 하나가 바로 간접 목적어(‘∼에게’)를 직접 목적어(‘∼를’) 앞에 두는 선호 현상이다. 이 현상은 산출과 이해의 차원, 그리고 코퍼스를 이용한 연구에서 그 선호가 모두 확인되었다(Choi, 2007; Nam & Hong, 2013, 2017; Nam, Hong & Yun, 2016). Nam과 Hong (2013)에서는 Yamashita와 Chang (1989)의 구 배열 과제를 활용한 산출 실험에서, 간접 목적어를 직접 목적어에 선치 시키는 어순이 선호된다는 것을 확인하였으며. Nam 등(2016)에서는 동일한 문장에 대하여 시선추적기법을 이용한 이해 실험을 진행하였고 그 결과 간접 목적어를 직접 목적어 앞에 두는 어순에 대한 1차 읽기시간이 더 감소한다는 것을 확인하였다.
흥미로운 점은, 간접 목적어를 직접 목적어 앞에 두는 이러한 어순이 길이 요인과 경합하는 경우 그 선호 어순이 역전되는 현상이 나타난다는 점이다. Nam 등(2016)은 한국어에서는 (3a)와 같이 간접 목적어와 직접 목적어 중 하나의 성분이 길어지면, 그 성분의 종류와 관계없이 상대적으로 긴 성분을 짧은 성분 앞에 두는 소위 “Long before Short (LbS)” 어순을 선호하는 현상이 나타나며, 이러한 선호는 2차 읽기시간 및 회귀에 영향을 미친다는 결과를 제시하였다.
(3) (a) Long before Short word order in Korean: Preferred
민수-는 [조교-가 작성-한 메모-를] [친구에게] 남겼다.
Minsu-nun [cokyo-ka caksengha-n meymo-lul] [chinkwu-eykey] namky-ess-ta.
Minsu-TOP [assistant-NOM write-REL memo-ACC] [friend-DAT] leave-PAST-DECL
(b) Short before Long word order in Korean
민수-는 [친구에게] [조교-가 작성-한 메모-를] 남겼다.
Minsu-nun [chinkwu-eykey] [cokyo-ka caksengha-n meymo-lul] namky-ess-ta.
Minsu-TOP [friend-DAT] [assistant-NOM write-REL memo-ACC] leave-PAST-DECLL
(4) (a) Short before Long word order in English: Preferred
I gave [Mary] [the antique that was valuable].
(b) Long before Short word order in English
I gave [the antique that was valuable] [to Mary].
LbS 현상은 한국어에 앞서 일본어의 간접 목적어와 직접 목적어 산출 시에 나타나는 것으로 보고된 현상으로(Hawkins, 1994; Yamashita & Chang, 2001), 영어에서 (4a)와 같이 상대적으로 긴 성분을 짧은 성분의 뒤에 위치시키는 “End Weight”혹은 “Short before Long (SbL)” 어순이 선호되는 것과는 완전히 반대의 어순이 선호되는 현상이다. 지금까지 영어를 중심으로 한 어순 연구들은 어순 선호 현상의 근본적인 인지적 메커니즘을 개념적 접근성적인 차원에서 찾으려고 시도하였다. 소위 개념적 접근성 이론(Accessibility account; Bock & Levelt, 1994; Ferreira, 1996)으로 명명되는 이 이론에서는 개념적 접근성이 높은 성분을 먼저 산출/이해하는 것이 즉각적인 문장 산출 및 이해 시 부담이 적다고 본다. 즉, 생물성(animacy)이 있는 개념이 없는 개념보다(Branigan, Pickering, & Tanaka, 2008; Chang, Kondo, & Yamashita, 2000; Dennison & Schafer, 2008; Prat-Sala & Branigan, 2000), 한정성(definiteness)이 있는 개념이 없는 개념보다(Grieve & Wales, 1973), 현저성(saliency)이 있는 개념이 없는 개념보다(Osgood & Bock, 1977), 구체성/이미지화 가능성(concreteness/imageability)이 있는 개념이 없는 개념보다(Bock & Warren, 1985) 개념적 접근성이 높기 때문에 이들을 먼저 산출하는 것이 선호된다. 길이의 측면에 이를 적용한다면, 짧은 성분이 개념적 접근성이 높기 때문에 짧은 성분을 먼저 처리하는 것이 선호되는 것이다(Bock, 1982; Kempen & Hoenkamp, 1987; Levelt, 1989). Yamashita와 Chang (2001)은 이러한 개념적 접근성의 이론적 설명을 바탕으로 LbS 현상을 설명하고자 하였다. 즉, 일본어와 같은 핵어 후치 언어는 긴 성분이 개념적 접근성이 높으므로 이 성분을 먼저 처리하는 것이 유리하다는 것이다. 그러나 개념적 접근성이 언어에 따라 달라지는 것으로 보는 것은 설명에 무리가 있다(Tanaka, Branigan, & Pickering, 2011).
따라서 이후의 설명들은 동사와 보충어들(complements) 간의 종속 거리(Dependency distance or the length of a dependency)를 최소화하면 언어 처리 및 이해가 촉진된다는 언어 보편적인 원칙으로서 LbS 선호 현상을 설명한다(Futrell, Mahowald, & Gibson, 2015; Gibson, 1998; Gildea & Temperley, 2010; Hawkins, 2007; 2014; Temperley & Gildea, 2018). 종속 거리 혹은 종속 길이는 일반적으로 동사와 종속어들 사이에 포함되어 있는 단어의 수로 측정이 된다. 즉, 종속 거리를 최소화한다는 것은 대안적 어순들(예: V-NP-PP vs. VP-PP-NP) 중에서 동사와 종속어들 사이에 더 적은 수의 단어 개입을 포함하는 어순이 처리에 용이하다는 것을 의미한다(Faghiri & Samvelian, 2020). 이에 의하면, 핵어 선치언어에서는 동사가 앞에 위치하기 때문에 (4a)와 같이 긴 성분을 뒤에 두는 것이 논항의 핵어(Mary, antique)와 술어(give)의 거리를 좁히는 것에 유리하지만 핵어 후치 언어에서는 동사가 문말에 위치하기 때문에 (3b)와 같이 길이가 긴 성분을 짧은 성분 앞에 두는 것이 논항의 핵어(친구, 메모)와 술어(남기다) 사이에 끼어드는 부가적 성분의 수를 최소화하여 주요 성분들의 통합 처리 수월성을 최소화할 수 있다.
그러나 종속 거리 최소화 이론들에서는 어떠한 성분이 보충어의 핵어로서 사용되는가, 즉 통합해야 하는 성분이 동사에 필수적인 논항인지 아니면 보충어인지 혹은 부가어인지에 대한 논의는 별도로 진행하지 않는다. Nam 등(2016)은 여기에 동사와 밀접한 성분을 동사에 더욱 가깝게 두려는 전략이 추가적으로 관여한다고 보고, Argument Packing Principle (APP)을 제안하였다. 즉, 어떠한 성분이 길어졌는지, 그리고 어떠한 성분이 동사와 멀리 떨어지게 되었는지가 추가적으로 처리의 효율성에 영향을 미치게 되어 최종적인 선호 어순 및 어순 처리에 영향을 미칠 것이라는 것이다. APP에서는 이에 대한 증거로 Gwon 등(2010)의 연구를 제시하였다.
Gwon 등(2010)에서는 “관념적으로 밀접한 관련을 맺고 있는 문장성분들을 통사적으로 가까이에 두는 것이 최상위의 법칙”이라는 Behaghel (1930)의 제안이 한국어 사용자들의 표층 어순 선택에 영향을 미치는지를 확인하고자 하였다. 이를 위하여 Yamashita와 Chang (2001)에서 사용한 구 배열과제를 이용한 산출 패러다임을 안구운동추적기법과 함께 사용하여 필수적 장소 부가어와 목적어 논항, 수의적 장소 부가어와 목적어 논항, 도구 부가어와 목적어 논항 사이에 존재하는 어순 선호도를 확인하였다. 산출 실험 결과, 필수적 장소 부가어와 목적어를 제시한 경우에는 둘 중 어떠한 성분이 먼저 산출되는 선호가 두드러지지 않았고, 수의적 장소 부가어와 목적어를 제시하는 경우 수의적 장소 부가어가 논항인 목적어 보다 먼저 산출되는 비율이 월등하게 높았다. 이러한 결과는 필수적 장소 부가어와 목적어 논항은 동사와의 의미적 긴밀성이 동등하고 수의적 장소 부가어는 목적어 논항에 비하여 동사와의 의미적 긴밀성이 떨어지기 때문에 수의적 장소 부가어와 목적어 논항을 산출하는 경우에만 동사와 의미적 긴밀성이 높은 문장성분인 목적어 논항을 보다 동사에 가깝게 두려고 하는 언어처리 경향이 반영되는 모습을 보여주므로 APP의 주장을 잘 뒷받침한다고 볼 수 있다.
한편, 도구 부가어와 목적어 논항의 배열에 있어서는 산출 비율상으로는 필수적 장소 부가어의 경우와 동일하게 어떤 어휘가 먼저 인식되었는지에 따라서 먼저 인식된 어휘가 먼저 산출되는 결과가 나타났다. 그러나 필수적 장소 부가어 조건에서는 논항-부가어의 순서로 어휘가 인식되었을 경우 부가어-논항의 순서로 문장이 산출될 확률이 22.11%였지만 도구 부가어가 사용된 조건에서는 동일한 경우 부가어-논항의 산출 확률이 28.07%로 높아졌기 때문에 도구 부가어를 논항인 목적어에 선치 시키려는 시도가 필수적 장소 부가어에 비하여 다소 강하게 나타났다고 볼 수도 있다. 따라서 저자들은 필수적 장소 부가어와 논항은 동사와의 의미적 긴밀성이 동일하게 높지만 도구 부가어는 필수적 장소 부가어에 비해서는 동사와의 의미적 긴밀성이 약하다고 해석하였다. 그러나 이에 대한 통계적 검증은 이루어지지 않았다.
이상에서와 같이, Gwon 등(2010)에서는 동사와의 친밀도가 서로 다른 부가어들을 이용하여 이것이 선호 어순에 영향을 준다는 견해를 피력하였지만, 이는 산출 실험의 결과에 국한되었고, 이 연구에서 활용한 시선추적기법은 이해 실험을 위해서가 아닌, 화면에 문장 구성 성분을 제시하는 경우 피험자들이 어떤 성분에 먼저 시선이 고정되는지를 확인하기 위한 부차적 용도였기 때문에 이러한 선호가 이해의 차원에서도 동일하게 나타나는지에 대한 검증은 불가능했다. 그리고 이 연구는 둘 중 한 성분이 상대적으로 긴 성분으로 조작되지는 않았기 때문에 이러한 어순 선호가 LbS와 경합하는 경우 어순 선호가 어떻게 달라질 것인지에 대한 추가적인 증거를 확보할 수 없었다.
본 연구에서는 도구 부가어와 목적어 논항의 어순 선호에 대한 보다 명확한 증거를 확보함으로써 어순 선호 현상의 저변에 깔려있는 언어 사용자의 인지적 메커니즘에 대한 이해도를 높이고 LbS 어순 선호에 관한 보다 보편적인 설명 방식을 채택하는데 기여하기 위하여 한국어 어순 선호 현상에 관한 시선추적실험을 진행하였다. 시선추적실험은 텍스트를 읽을 동안 발생하는 안구 움직임을 밀리 세컨드(ms)의 단위로 측정하는 기법으로, 독자의 실시간적인 텍스트 처리 과정을 파악할 수 있는 실험 기법이다(Just & Carpenter, 1980; Rayner, 1978). 특히, 시선추적실험은 실험의 구성 성분들이 한 화면에 하나씩 제시되는 방식을 주로 따르는 자기 조절 읽기 실험이나 뇌파 실험과는 달리 텍스트 전체를 피험자에게 제시한 후 피험자가 그를 자유롭게 읽을 때의 안구 움직임을 측정한다는 점에서 자연스러운 읽기 과정을 잘 반영한다는 이점이 있다(Keating, 2013). 또한, 시선추적기법을 이용하면 각 구성 성분을 읽을 때의 읽기시간을 관찰할 수 있을 뿐 아니라, 해당 구성 성분을 읽고 다시 그 성분을 처리하는 것을 일컫는 회귀(regression) 등을 측정할 수 있다는 점에서 문장의 초기 처리 과정과 후기 처리 과정에서의 정보 처리 과정을 살펴볼 수 있다는 장점이 있다(Clifton, Staub, & Rayner, 2007). 이에 본 논문에서는 시선추적기법을 적극 활용하여 도구 부가어를 목적어에 선치 시키려는 규범 어순에 대한 선호 원리와 길이가 긴 성분을 짧은 성분에 선치 시키려는 선호 원리가 상충할 때 특정 선호의 원리가 문장 처리의 어느 단계에서 나타나는지를 검증함으로써 어떠한 인지적 메커니즘이 어순 처리에 영향을 미치는지 그리고 두 어순 선호의 원리의 상대적 강도가 어떠한지를 파악하고자 하였다.
이를 위하여 우선 두 성분이 모두 짧으면서 도구-목적어의 순서, 목적어-도구의 순서로 구성된 문장을 읽는 동안의 시선을 추적하여 두 성분 사이에 존재하는 기본적인 선호 어순을 파악하고자 하였고, LbS 선호 현상이 도구 부가어와 목적어 논항 배열에서도 처리 및 선호 어순에 영향을 미치는지, 그리고 이때 동사와의 밀접성이 높은 목적어 논항을 동사에 더욱 가깝게 두려는 처리의 노력이 관여되는지를 검증하기 위하여 기존 선행연구들과 같이 둘 중 한 성분을 길게 조작하는 방식으로 추가적인 실험 문장을 구성하였다. 이를 통하여 본 논문에서는 Gwon 등(2010)에서 나타났던 한국어 산출 실험에서의 i) 도구 부가어를 목적어에 선치 시키려는 어순 선호 경향이 문장 이해 과정에서도 동일하게 나타나는지를 검증하고 ii) 만약 도구 부가어와 목적어에 대한 선호 어순이 존재한다면, LbS 선호 원리와 상충하였을 때 어떤 선호 원리가 더 우세하게 작용하는지 iii) 각 선호 원리의 어순이 문장 이해 과정에서 어떠한 단계에서 나타나는지 혹은 나타나지 않는지를 검증하고자 하였다. 이러한 작업은 한국어 사용자의 마음속에 존재하는 규범 및 선호 어순의 심리적 실제성을 확인함으로써 모국어 및 제2언어 학습자들의 커뮤니케이션 효율성을 달성할 수 있는 한국어 어순의 문체적(stylistic) 가이드라인을 구성하는데도 기여할 수 있을 것이다.
뿐만 아니라, 한국어 어순 선호에 대한 이러한 연구는 실어증 환자들의 언어 처리 및 인지 처리의 메커니즘을 밝히기 위한 연구의 기반이 될 수 있다는 점에서도 그 가치를 찾을 수 있다. 지금까지 실어증 환자들을 대상으로 그들이 규범 어순과 비 규범 어순을 어떻게 처리하는지를 검증하였던 연구들은 실어증 환자들의 언어 처리 메커니즘을 밝히는 데 기여하는 데에 있어 중요한 역할을 해 왔다(Mavis, Arslan, & Aydin, 2020). 일례로, O’Grady, Lee와 Choo (2005)는 한국어 실어증 환자들을 대상으로 목표(goal)와 주제(theme)의 어순에 따른 문장 이해도를 검증한 바 있다. 그 결과, 한국인 실어증 환자들의 경우 사건의 구조에 따라 명사구가 배열된 어순인 주제-목표 어순에 비하여 규범 어순이나 trace-less인 어순에 해당하는 목표-주제(goal-theme) 어순의 경우 문장 이해도가 매우 낮았다. 이를 통해 저자들은 실어증 환자들에게서 나타나는 문장 이해의 결함은 문장을 해석하는 과정에서의 결함이 아닌 문장의 통사적 구조와 해당 사건의 표상을 연결하는 과정에서 발생하는 부조화(misalignment)로 인한 것이라 주장하였다. 이러한 맥락에서 우선적으로 한국어를 모국어로 하는 정상인 집단에서 특정 어순 선호의 경향이 존재하는지 그리고 어순 선호의 경향이 어떠한 양상으로 문장 이해 과정에서 나타나는지를 밝혀내는 것은 언어 및 커뮤니케이션 장애 연구의 기초를 제공할 수 있을 것으로 기대할 수 있다.
연구방법
참가자
건국대학교에 재학 중인 20대 남녀 대학생 36명(남성 22명, 여성 14명, 평균나이 24세)이 시선추적실험에 참여하였다. 실험에는 5세 이전에 해외 체류 경험이 없으며, 1년 이상의 장기 해외 체류 경험이 없는 한국어 모국어 화자들만 참여하였다. 이들 중 초점이 제대로 맞지 않은 한 명의 피험자를 제외한 35명의 결과가 분석에 포함되었다. 실험 참가자들은 모두 정상시력을 보유하고 있었다. 모든 참가자들은 실험 시작 전 실험 방법에 대한 안내를 받았고, 실험 동의서에 서명하였다. 실험이 끝난 후 정상적으로 데이터 수집이 모두 완료된 경우에만 참가자에게 소정의 사례비를 지급하였다.
실험 문장
문장 구성 및 실험 패러다임은 시선추적기법을 이용하여 어순 선호 현상을 밝혀 낸 기존의 읽기 연구(Nam et al., 2016)와 동일하게 유지하였다. 우선 도구-목적어 사이에 존재하는 규범 어순 선호를 확인하기 위하여 두 성분 모두 짧으면서 어순만 조정된 조건(SISD, SDSI)을 구성하였고, 여기에 도구 부가어가 길어지거나(LISD, SDLI) 목적어가 길어지는 조건(LDSI, SILD)의 문장들을 추가적으로 구성하여 실험 조건으로 포함하였다. 결국, 짧은 성분만이 사용된 조건에서는 규범 어순 요인(INST-DO vs. DO-INST)이, 둘 중 하나의 성분이 길어지는 조건에서는 규범 어순과 더불어 길어진 성분의 위치(Long-Short vs. Short-Long)가 주요 요인으로 사용되었다. 실험에 사용된 조건과 예문은 Table 1과 같다.
도구 부가어와 직접 목적어로 사용되는 어휘는 모두 생물성이 없는 사물 명사(inanimate noun)를 사용하였고, 어휘의 길이도 도구격 조사인 “∼로/으로”, 목적격 조사인 “∼을/를”을 포함하여 4±1음절로 통제하였다.
성분 길이의 확장은 관계절을 부착하는 방식으로 진행하였다. 예를 들어, Table 1에 제시된 예문의 경우, 목적어 “종이를” 앞에 “선생님이 버린”을 부착하여 목적어 길이를 길게 하였고, 도구 부가어 “가위로” 앞에는 “선생님이 빌려준”을 부착하여 길이를 확장하였다. 어휘적 차이를 최대한 통제하기 위하여 대부분의 문장에서 관계절을 이루는 주어는 동일한 명사를 사용하였으나, 의미상 해당 명사의 사용이 어색한 경우 동일한 음절 수를 가지는 적절한 명사를 사용하여 수식 관계절의 문장 역시 큰 차이가 나지 않도록 통제하였다. 관계절에 사용된 동사의 경우 동일한 동사로 목적어와 도구 부가어를 모두 수식하기는 어렵기 때문에 동일한 동사를 사용할 수는 없었지만 어휘 수는 동일하게 통제하거나 1음절 내외 정도의 차이만 허용하였다.
조건 별로 24개의 실험 문장이 실험 재료로 사용되었고, 모든 문장은 라틴 방형설계(Latin square design)에 의해 6세트로 분할되었다. 하나의 세트에는 6개의 조건, 조건 별 4개의 문장이 할당되었다. 24개의 실험문장 외에 72개의 채움 문장(Filler sentence)이 세트 별로 포함되었는데, 채움 문장으로는 장소 부사어와 시간 부사어를 사용하여 동일한 방식으로 구성된 문장들 24개와 다양한 수식 관계절을 포함하고 있는 문장들 48개가 사용되었다. 한 명의 피험자는 하나의 세트에만 노출되었고 총 96개의 문장에 대한 읽기를 진행하였다.
실험절차
시선추적실험은 SMI社의 RED500시선추적기로 진행하였다. 실험자극의 제시를 위해서는 SMI Experiment Center 프로그램을 사용하였고 안구 움직임의 기록을 위해서는 SMI IViewX 프로그램을 사용하였다. 자극별로 기록된 안구 운동은 SMI BeGaze 프로그램을 이용하여 분석되었다.
참가자들은 19인치 모니터 앞에 앉아서 실험을 진행하였고 참가자들의 눈과 모니터 사이의 거리는 70 cm로 유지하여 중심와(fovea)에 2개 내외의 음절이 포함될 수 있도록 시야각을 유지하였다. 참가자들의 안구 움직임은 500 Hz의 빈도(sampling rate)로 기록되었다.
참가자들은 실험 시작 전 화면으로 제시되는 지시 사항을 충분히 숙지하였으며, 중앙 하단에 제시되는 ‘다음’이라는 글자에 2초 동안 안구를 고정하면 다음 화면이 제시되었다. 모든 문장은 모니터의 왼쪽 상단에서 1/5지점에서 시작하여 한 줄에 표시되도록 하였고, 문장이 제시되기 전 문장 시작 위치에 (+) 표시를 제시하여 읽기 시작 시점의 위치를 고정하였다. 실험 시작 전과 10개의 문장 사이에 초점 교정(calibration)을 진행하였고, 수직과 수평의 정확도가 0.5°미만의 오차를 보이는 경우에만 실험을 계속 진행하였다. 문장에 대한 이해도를 확인하기 위하여 문장 제시 직후 앞서 제시된 문장의 일부 내용에 대하여 “그렇다/아니다”로 답하는 이해 판단 과제를 진행하였고 모든 피험자들이 95% 이상의 높은 정확도를 보였으므로(평균 94.8%) 별로도 피험자나 아이템을 분석에서 제외하지는 않았다.
결과분석
참가자들의 시선은 전체 문장에 대해서 기록되었지만 Nam 등(2016)에서 어순과 길이 요인의 효과가 충분히 반영되는 것으로 검증된 영역인 [(짧은 혹은 길어진) 도구 부가어 + (짧은 혹은 길어진) 목적어] 영역을 주요 분석 영역(critical ROI)으로 설정하였다. 읽기 실험인 것을 감안하여 단일 안구고정(single fixation)이 100 ms 이하이거나 3,000 ms 이상인 경우에는 분석에서 제외하였고, 피험자 별, 조건 별 평균에서 ±2.5 표준편차를 넘어서는 데이터들은 이상치(outlier)로 판단하여 분석에서 제외하였다.
시선추적의 결과는 전체 읽기시간(Total reading time), 1차 읽기 시간(First pass reading time), 2차 읽기시간(Second pass reading time), 회귀를 반영하는 읽기시간(Go-past, 혹은 regression path time)의 4가지 지표로 분석하였다. 1차 읽기시간은 보통 읽기의 초기 단계에 발생하는 어려움을 반영하는 지표로 알려져 있다(Straub & Rayner, 2007). 반면 2차 읽기시간과 전체 읽기시간은 후기 처리를 반영하는 지표로, 문장 전체의 재분석 및 의미적 통합에서 발생하는 어려움을 잘 반영하는 것으로 여겨진다(HyÖna, Lorch, & Rinck, 2003; Rayner, Sereno, Morris, Schmauder, & Clifton, 1989). 한 편, 본 논문에서는 초기와 후기 처리의 중간 단계의 처리를 반영하면서 독자가 새로운 정보를 수신할 준비가 되기 전에 텍스트를 처리하는 데 걸리는 시간을 반영하는 것으로 알려져 있는 회귀를 반영한 읽기시간도 추가로 보고하였다(Pickering, Frisson, McElree, & Traxler, 2004).
통계적 검증을 위해서는 R 통계 프로그램 (R Development Core Team, 2014)을 이용하여 선형 혼합효과 회귀모델 분석(linear mixedeffect regression)을 진행하였다. R 프로그램에 포함된 lme4 (version 0.999375-33; Bates, Mächler, Bolker, & Walker, 2014), language R libraries (version 1.0; Baayen, 2013)를 이용하였고, p값은 lmerTest 패키지(Kuznetsova, Brockhoff, & Christense, 2015)를 활용하여 도출하였다. 회귀모델에는 ROI에 포함되는 어휘들에서 측정된 4가지 종류의 읽기시간이 종속변인(dependent variable)으로, 어순(도구-목적어 vs. 목적어-도구)과 길어진 성분의 위치변인(LbS vs. SbL), 그리고 두 변인의 상호작용이 고정변인(fixed variables)으로 포함되었다. 단, 목적어와 부가어가 모두 짧은 경우에 대해서는 고정변인에 어순변인만을 포함하여 별도로 분석을 진행하였다. 모든 고정 변수는 더미 코딩되었다. 길이변인은 길어진 성분이 앞에 오는 LbS 조건을 0으로, 짧은 성분이 앞에 오는 SbL 조건을 1로 부호화하였다. 어순변인은 도구-직접 목적어를 0으로, 직접 목적어-도구를 1로 부호화하였다. 참가자와 아이템을 랜덤변인(random variable)으로, 랜덤변인과 고정변인 사이의 상호작용도 랜덤변인으로 모델에 포함하였고, 이러한 랜덤변인은 모델이 수렴될 때까지 감소되었다.
연구결과
우선 모든 성분이 짧은 경우 어순에 따라 읽기시간이 어떻게 달라지는지 확인하고, 각 어순 별로 길어진 성분이 앞에 위치하는 경우와 뒤에 위치하는 경우 읽기시간이 어떻게 달라지는지를 검증하였다.
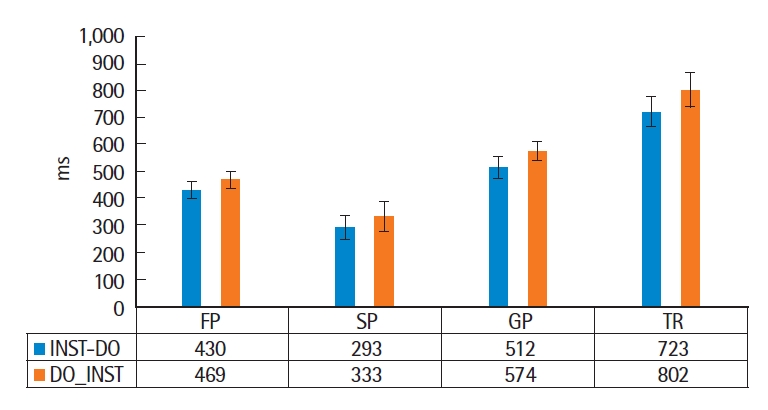
우선, 두 성분이 모두 짧은 경우에 대한 분석 결과, 모든 시선추적 지표에서 도구-직접 목적어 어순(INST-DO)에 비하여 직접 목적어-도구(DO-INST)의 어순에서 평균 읽기시간이 약간 증가하는 듯했으나(FP: 39 ms 증가, SP: 40 ms 증가, GP: 62 ms 증가, TR: 79 ms 증가)(Table 2, Figure 1), 통계적으로 그 차이가 유의미하지는 않았다(FP: Estimate=38.16, S.E.=39.42, t-value=.968, n.s.; SP: Estimate=36.82, S.E.=56.99, t-value=.646, n.s.; GP: Estimate=54.37, S.E.=42.99, t-value=1.265, n.s; TR: Estimate=73.04, S.E.=66.12, t-value=1.105, n.s.). 이는 도구 부가어와 직접 목적어 중 어떠한 성분을 앞에 혹은 뒤에 위치시키더라도 모국어 화자들의 처리 부담이 증가하지 않는다는 것을 의미한다. 즉, 한국어 모국어 화자들의 실시간 문장 처리 상황에서는 도구-목적어 배열에 있어 비교적 자유로운 어순이 허용된다는 것을 확인할 수 있었다.
그러나 두 성분 중 하나의 성분이 길어진 경우에 대한 분석 결과, 전체 읽기시간에서 어순의 효과가 (INST-DO mean 1,394 ms [SD 645 ms] vs. DO-INST mean 1,609 ms [SD 780 ms]), 1차 읽기시간(LbS mean 724 ms [SD 318 ms] vs. SbL 959 ms [SD 396 ms])과 회귀를 반영한 읽기시간(LbS mean 918 ms [SD 387 ms] vs. SbL mean 1,103 ms [SD 437 ms])에서 LbS 효과가유의미하게나타났다(Table 3, Figure 2). 이러한 결과는 도구 부가어와 직접 목적어 중 하나의 성분이 길어지는 경우, 도구 부가어를 직접 목적어 앞에 두는 어순이 전체 읽기시간을 감소시키고, 선행 연구에서와는 달리 길어진 성분을 앞에 두는 Long before Short 어순이 읽기의 초기 과정에서부터 처리에 영향을 미쳤다는 것을 보여준다.
논의 및 결론
본 연구에서 확인하고자 했던 연구문제는 크게 세 가지로 요약된다. 첫째, 성분의 길이에 차이가 없는 경우, 문장 산출 시에 확인되었던 도구-목적어 어순에 대한 불명확한 선호가 이해 실험에서는 어떠한 방식으로 확인될 것인가? 둘째, 하나의 성분이라도 길어지는 경우, 길어진 성분을 짧은 성분 앞에 두는 LbS 선호가 도구 부가어와 직접 목적어를 나열하는 경우에도 동일하게 나타날 것인가? 셋째, 실시간 이해 과정을 반영하는 시선추적실험의 결과에 어순 선호가 어떠한 식으로 반영될 것인가? 즉, 기존에 시선추적기법을 이용하여 진행된 어순 연구들과 동일한 지표에 어순 효과 및 길이 요인의 효과가 반영될 것인가?
우선 첫 번째 문제부터 짚어보기로 하자. 문장 산출 실험을 이용하여 도구 부가어와 직접 목적어의 규범 어순을 찾고자 했던 Gwon 등(2010)에서는 도구 부가어와 직접 목적어 중 먼저 입력된 성분을 먼저 산출하려는 경향성을 확인하였다. 따라서 도구 부가어와 직접 목적어 중 하나의 성분이 동사와 더 밀접한 의미적 관련성을 가진다고 결론 내릴 수는 없으나, 수의적 장소 부가어에 비해서는 동사와 가깝고 필수적 장소 부가어만큼 동사와 밀접하지는 않다고 해석하였다. 산출 실험의 경우 산출된 문장들의 비율만으로 선호에 대한 판단을 내려야 하므로 어떠한 어순이 얼마나 선호되는지 정확하게 유추할 수 없는 한계가 있었다. 본 연구에서 진행한 시선 추적실험의 결과, 도구 부가어와 직접 목적어의 나열에 있어, 도구 부가어를 직접 목적어 앞에 두려는, 혹은 반대로 직접 목적어를 동사에 더 가까이 위치시키려는 어순 선호가 기술통계(평균값의 차이)상으로는 나타났지만, LMER을 이용한 통계적 검증에서는 유의미하지 않게 나타났다. 이는 도구 부가어를 직접 목적어 앞에 두려는 규범 어순 혹은 선호어순 효과가 매우 미미하다는 것을 의미하며, 이러한 미미한 선호가 산출에서는 특정 어순에 대한 선호보다는 먼저 입력된 성분을 먼저 산출하는 전략에 의하여 상쇄되었을 가능성이 있다.
그러나 흥미로운 점은, 두 성분 중 하나의 성분이 길어지는 경우에는 도구 부가어-직접 목적어 어순에 대한 선호가 전체 읽기시간 지표에 반영된다는 점이다. 결국, 이는 도구 부가어를 직접 목적어 앞에 두려는 혹은 직접 목적어를 동사에 더욱 가깝게 두려는 노력이 두 성분 중 하나의 성분이 길어지는, 즉, 문장의 구조가 복잡해지거나 처리해야 하는 성분이 많아지는 경우에는 더욱 크게 발현된다는 것을 의미하므로, 어순의 효과 역시 문장 처리 시의 부담이나 처리자의 인지적 용량의 정도에 따라서 그 크기가 달라질 수 있다는 것을 시사한다.
한편, 길어진 성분을 상대적으로 짧은 성분의 앞에 두는 LbS 선호는 규범 어순의 여부와 상관없이 읽기의 수월성에 영향을 미치는 것으로 확인되었다. 추가적으로 주목해야 할 사항은 전체 읽기시간에서 규범 어순의 주효과가 있었고, 길어진 도구를 짧은 목적어 뒤에 둠으로써 목적어와 동사의 사이가 가장 멀어지는 조건에서 1차 읽기시간(937 ms), 회귀를 포함한 읽기시간(1,172 ms), 전체 읽기시간(1,665 ms)이 다른 조건들에 비하여 길게 나타났다는 점이다(Figure 2). 이러한 결과는 직접 목적어를 술어에서 멀리 두면 둘 수록 문장 처리 부담이 증가한다는 것을 의미하므로, 어순 배열의 대상이 되는 주요 성분들 중 동사와 의미/개념적으로 더 가까운 성분에 대한 고려가 반영될 수 있다고 보는 APP의 주장을 뒷받침한다고 볼 수 있다.
본 연구에서는 어순 효과와 LbS 효과가 어떠한 안구운동 지표에 반영되는지를 확인함으로써 문장 처리 과정 중 언제 어순이나 LbS 효과가 반영되는지, 그리고 이러한 결과가 선행연구와는 얼마나 정합하는지를 확인하고자 하였다. 결론적으로 본 연구에서는 규범/선호어순 효과는 전체 읽기시간에, 길어진 성분을 앞에 두는 효과는 1차 읽기시간 및 회귀를 포함한 읽기시간에 반영된다는 결과를 확인할 수 있었다. 그러나 이러한 결과는 동일하게 시선추적기법을 활용하여 규범 어순 및 LbS 선호의 효과를 확인한 Nam 등(2016)과는 다소 차이가 있다. Na 등(2016)에서는 간접 목적어-직접 목적어 어순과 길어진 성분의 위치 요인을 조작하여 시선추적 실험을 진행하였고, 간접 목적어를 직접 목적어 앞에 두는 어순 선호의 효과는 1차 읽기시간에서, 길어진 성분을 앞에 두려는 LbS 선호의 효과는 2차 읽기시간 및 전체 읽기시간, 회귀 비율에서 유의미하게 나타났다. Nam 등(2016)은 이러한 결과를 바탕으로 규범 어순의 배열은 문장의 초기에 진행되고, LbS 선호에 의한 필수 성분과 술어의 결속 과정은 문장처리의 후기에 진행된다고 판단하였다. 그러나 본 연구의 결과는 이러한 해석을 뒷받침하지는 않았다. 한 가지 가능성은 간접 목적어와 직접 목적어의 경우 둘 다 짧은 조건에서도 간접 목적어를 직접 목적어 앞에 두는 어순이 선호된다는 것이 산출 및 이해 모두에서 명확하게 검증되었다. 즉, 두 성분 중 직접 목적어가 동사에 더욱 필수적인 성분이며 이러한 성분을 동사에 가까이 위치시킨 문장에 대한 선호가 문장 초기에서부터 명확하게 나타날 수 있는 조건이었다는 것이다. 하지만 본 연구에서 사용한 실험 재료는 성분의 길이가 동일한 경우 그 선호가 명확하지 않은 도구 부가어-직접 목적어 구문이었기 때문에, 문장의 초기부터 두 성분의 배열이나 선호 어순이 문장 이해 과정에 영향을 미칠 필요가 없었을 가능성이 있다. 이는 곧 LbS 선호가 먼저 고려될 수 있는 인지적 자원이 문장 처리의 초기 단계부터 확보될 수 있다는 것을 의미하므로, 긴 성분을 짧은 성분 앞에 두어 통합 처리를 수월하게 할 수 있도록 구성된 문장에 대한 처리가 1차 읽기시간에서부터 더 수월하게 진행되었을 여지가 있다는 것을 시사한다. 즉, 규범 어순의 효과와 길어진 성분의 위치 효과는 어떠한 효과가 어떠한 처리 단계에 영향을 미친다고 단정할 수 있는 것이 아니라, 두 성분에 대한 규범 어순 효과가 얼마나 강력한지에 따라 달라질 수 있다. 그러나 이에 대한 명확한 결론에 도달하기 위해서는 여전히 더 많은 어순 및 어순 결정 요인들에 대한 추가적인 연구가 필요하다고 하겠다.
한편, 한국어를 모국어로 하는 정상인 화자 집단에서 도구 부가어-직접 목적어 중 길어진 문장 성분을 짧은 성분 앞에 두는 것을 선호하는 경향이 1차 읽기시간과 회귀를 포함한 읽기시간에서 나타난다는 이러한 결과는 실어증 및 언어 장애 연구에 또 다른 차원에서 중요한 함의를 제공할 수 있다. 1차 읽기시간은 안구 운동의 지표 중에서도 통사적 이례성(anomaly)에 따른 처리의 어려움을 가장 잘 반영하는 지표에 해당하며, 회귀를 포함한 읽기시간 또한 문장의 즉각적인 이례성 탐지를 반영하는 대표적인 안구 운동 지표에 해당한다(Dussias, 2010). 이는 비선호 어순에 대한 처리가 통사적 어려움이 있는 문장에 대한 처리와 비슷한 인지 기제에 기반한다는 것을 시사하는 것이므로, 이러한 측면에 초점을 맞춘다면, 실어증 환자의 어순 선호 현상이나 어순 처리의 매커니즘을 설명하기 위한 추가 연구를 진행하는데 좋은 기초 자료로써 활용될 수 있을 것이다.
본 연구에서는 한국어 모국어 화자를 대상으로 도구 부가어와 직접 목적어 사이에 존재하는 어순 선호 현상에 대한 시선추적실험을 진행하였다. 연구의 다음 단계는 이러한 모국어 화자에게서 나타나는 규범 어순 효과 및 LbS 선호가 한국어를 제2언어로 습득하는 학습자에게도 동일한 방식으로 나타나는지, LbS 선호는 언어 습득의 과정에서 점차 습득되어 가는 것인지 아니면 필수적인 성분을 동사에 가깝게 두는 것을 선호하는 언어 보편적 선호가 반영되는 것으로 보아야 하는 것인지, 어순 습득에 있어서도 모국어 전이 효과가 나타나는지 등을 밝히는 것이다. 이러한 시도는 어순 선호 현상에 대한 전반적인 이해도를 높이고, 어순 선호에 대한 보편적 설명력을 가지는 이론을 확정하는 데 도움이 될 수 있을 뿐만 아니라, 제2언어 학습자들을 대상으로 하는 한국어 교습의 수월성을 높이는 데도 기여할 수 있을 것이다.