한국어 컴퓨터 자동언어분석 시스템(K-ALAS) 신뢰도 연구
The Reliability of the Korean-Automatic Language Analysis System (K-ALAS): A Computerized Language Analysis System for Language Assessment
Article information
Abstract
배경 및 목적
언어표본분석은 언어재활사에게 권장되는 필수적인 언어평가방법 중 하나이나 시간적 제약과 분석의 어려움으로 인해 임상 현장에서 많이 활용되어 오지 못하였다. 본 연구는 이를 해결하기 위해 개발된 컴퓨터 자동언어분석 시스템인 K-ALAS의 신뢰도를 확인을 목적으로 하였다.
방법
2-6세 영유아 언어표본 50개를 K-ALAS와 전문가가 분석하고 언어측정의 기본 단위가 되는 어절, 단어, 형태소에 대해 분석 일치도를 측정하였으며, K-ALAS와 전문가가 측정한 구문(MLUe, MLUw, MLUm), 문법형태소(NTJ, NTE, NDJ, NDE), 어휘의미(NTW, NDW, TTR) 측정치에 대해 t-test와 상관분석을 실시하였다.
결과
K-ALAS와 전문가 간 어절, 단어, 형태소 분석 일치도는 97.87-99.88%로 매우 높은 것으로 나타났다. K-ALAS와 전문가가 측정한 구문, 문법형태소, 어휘의미 측정치 모두에 유의한 차이가 없었으며, r=.972-1.000의 매우 높은 상관관계를 보였다.
논의 및 결론
본 연구를 통해 K-ALAS가 매우 정확하게 언어 표본을 분석하고 주요 언어측정치를 측정해 주는 것으로 확인하였다. 연구 결과를 토대로 언어 진단 및 중재와 관련해 K-ALAS의 임상적 활용 시사점에 대해 논의하였다.
Trans Abstract
Objectives
Although language sample analysis is essential for language evaluation, it is not widely conducted due to time constraints and difficulties in analysis. This study was conducted to evaluate the Korean-Automatic Language System (K-ALAS), which was developed to support language sample analysis.
Methods
50 language samples of young children aged 2 to 6 were analyzed by K-ALAS and a language analysis expert. The percentage agreement of the analysis results between K-ALAS and the expert on Eojeol, words, and morpheme, which are the basic units of language measurement, were calculated, and t-test and Pearson correlation analysis were conducted on the main language measures (MLUe, MLUw, MLUm, NTJ, NTE, NDJ, NDE, NTW, NDW, TTR) measured by K-ALAS and the expert.
Results
The percentage agreement of the eogeol, word, and morpheme analysis between K-ALAS and the expert, was found to be very high at 97.87-99.88%, and the t-test results showed that there was no significant difference between all language measures measured by K-ALAS and the expert, and the result of correlation analysis was also very high with r = .972-1.000.
Conclusion
This study confirmed that K-ALAS analyze language samples and measures the main language measures very accurately. We discussed the implications of clinical use of K-ALAS in relation to language diagnosis and intervention.
흔히 자발화 분석으로 알려져 있는 언어표본분석은 표준화된 언어검사와 더불어 언어장애인의 언어능력을 진단하고 평가하는 주요 방법 중 하나이다. 언어표본분석 방법은 화자의 언어능력을 각 발달주기를 대표하는 일부 문항들을 통해 평가하는 표준화된 언어 검사에 비해 화자로부터 수집한 언어표본에서 문법이나 어휘, 화용, 내러티브 또는 대화와 같은 담화 능력까지 전반적인 언어표현능력을 확인할 수 있다는 장점을 갖는다. 또한 화자가 자발적으로 산출한 언어표본을 분석하므로 구조화된 방식을 통해 언어평가를 진행하는 표준화된 언어검사에 비해 화자의 자연스러운 언어사용과 의사소통능력을 확인할 수 있으며(Kim, 2014; Lund & Duchan, 1993; Owens, 2014), 실시 절차에 따른 제약이 상대적으로 크지 않아 아주 어린 아동부터 연령이 아주 높은 노인까지 폭넓게 활용할 수 있다는 점도 큰 장점으로 제안된다(Lee, Choi, Oh, Yoon, & Kim, 2020; Lee, Choi, Yoon, Kim, Min, & Kim, 2017; Yoon, Jeong, Lee, Kim, Choi, & Kim, 2018). 때문에 국내외를 막론하고 언어표본분석은 임상 현장에서 언어장애, 특히 언어발달에 어려움을 갖는 언어발달장애 아동 언어평가에 필수 절차로 권고되고 있으며, 언어치료 또는 언어병리학 학부 및 대학원 교육과정에서도 언어표본분석을 필수 내용으로 포함하고 있다.
언어표본분석의 임상적 가치와 언어재활사 교육과정에서의 중요성이 강조되고 있음에도 불구하고 실제 임상현장에서 언어표본분석이 활용되는 수준은 높지 않은 것으로 보고되고 있다. Lee 등(2020)은 우리나라 언어재활사 1,351명을 대상으로 언어임상 현장에서의 언어표본분석 활용 실태를 조사하였는데, 전체 응답자 중 언어표본분석을 실시한다고 응답한 언어재활사가 절반에 불과하였으며, 언어표본분석을 실시한다고 보고한 응답자 내에서도 연간 분석 사례가 10사례 미만으로 보고되어 소수의 사례에 대해서만 언어표본분석을 실시하는 것으로 나타났다. 언어표본분석을 실시하지 않거나 제한적으로 실시하는 이유에 대해 분석을 실시할 시간이 없다는 시간적 제약이 가장 주된 이유로 보고되었으며, 그 다음 순으로 결과 활용의 제한, 자료수집 및 언어표본분석에 대한 훈련 및 전문성 부족, 언어표본분석에 활용할 자료 제한 등의 이유들이 보고되었다.
언어표본분석의 제한된 활용은 비단 우리나라에서만 보고된 것이 아니다. Lee 등(2020)의 연구보다 더 먼저 미국(Kemp & Klee, 1997; Pavelko, Owens, Ireland, & Hahs-Vaughn, 2016)이나 오스트레일리아(Westerveld & Claessen, 2014)에서 언어재활사들을 대상으로 언어표본분석 실태를 조사한 연구들을 보면 임상현장에서 언어표본분석을 실시한다고 보고한 비율이 약 66%에서 90% 정도로 우리나라에서 조사된 것보다 높았으나, 실제 담당하고 있는 언어치료 대상자 중 일부에게만 언어표본분석을 실시하고 있으며, 훈련 받은 방식대로 체계적인 절차로 실시하기보다는 소수의 발화를 통해 확인하는 약식 절차로 실시하는 경우가 절반 이상이라고 보고하였다. 그리고 우리나라 언어재활사들에게서 보고된 것과 마찬가지로 언어표본분석에 시간이 너무 많이 소요된다는 것을 언어표본분석을 실시하지 않거나 약식으로 실시하는 주된 이유로 제시하였다.
시간적 부담과 더불어 언어표본분석 자체의 어려움, 분석 결과의 정확성 확보 문제, 결과 해석 및 활용의 어려움 등도 언어표본분석 실시의 주요 제약으로 고려된다. 아동언어장애와 성인언어장애 분야 언어재활사를 대상으로 질적연구 방법을 통해 각각의 언어표본분석에 대한 경험과 요구를 살펴본 Oh, Yoon과 Lee (2020), Yoon, Oh와 Lee (2020)도 언어표본분석의 전문성 부족과 정확한 분석의 어려움, 언어표본분석에 활용할 수 있는 자료 부족, 결과 해석의 어려움 등과 더불어 시간이 많이 소요된다는 점을 언어표본 분석과 관련된 주된 문제점으로 제시하였다. 그리고 전문가의 언어 표본분석 역량을 증진시키거나 언어표본분석에 활용할 수 있는 여러 프로토콜을 개발하는 것 등과 함께 언어표본분석에 컴퓨터를 활용하는 것이 이러한 여러 문제점들을 해결하는 주요 대안이 될 수 있다고 제안하였다.
컴퓨터를 활용한 언어표본분석은 언어표본분석의 가장 큰 제약으로 보고되고 있는 시간적 부담을 경감시켜줄 뿐 아니라, 비교적 일관되고 정확하게 언어표본분석을 실시하고, 분석 결과를 빠르고 쉽게 요약하여 제공해 준다(Long & Channell, 2001; Long & Masterson, 1993; Miller, Andriacchi, & Nockerts, 2016; Owens, 2014; Pezold, Imgrund, & Storkel, 2020). 이처럼 컴퓨터 언어표본분석은 언어표본분석이 갖는 어려움을 상당히 해결해 줄 수 있어 영어권에서는 비교적 일찍부터 언어발달이나 장애를 확인하기 위한 목적으로 Automated LARSP (Bishop, 1985), Computerized Profiling (Long & Fey, 1989), DSS Computer Program (Hixson, 1983), Parrot Easy Language Sample Analysis (PELSA; Weiner, 1988), Pye Analysis of Language (PAIL; Pye, 1987), Computerized Language Analysis (CLAN; MacWhinney, 2000), Systematic Analysis of Language Transcripts (SALT; Miller & Chapman, 2003), Sampling Utterances and Grammatical Analysis Revised (SUGAR; Pavelko & Owens, 2017) 등 다양한 언어분석 프로그램이 개발되어 왔으며, 지속적으로 발전되어 왔다. 초기에 개발된 프로그램들은 컴퓨터를 활용하나 실제 분석은 사용자에 의존하는 형식이어서 언어표본분석이 갖는 제한점들을 많이 해결하지 못하였으나 CLAN, SALT를 발전시킨 SALT-2 (Miller, Andriacchi, & Nockerts, 2016), SUGAR 등은 자연어처리(Natural Language Processing, NLP) 기술을 활용하여 언어 분석의 자동화를 상당히 실현하고 있다. 그중에서도 SALT-2는 언어발달장애를 평가하기 위한 목적으로 개발된 프로그램으로, 사용자가 컴퓨터를 활용하여 직접 분석을 실시해야 했던 SALT (Miller & Chapman, 2003)를 개선하여 자동 분석을 실현하였으며, 언어발달을 확인할 수 있는 여러 측정치들을 자동으로 측정하고 자체적으로 구축한 데이터베이스와의 비교를 통해 분석 결과에 대한 상대적인 비교 결과까지 제공하여 언어임상 활용도를 확장하였다(Hammett Price, Hendricks, & Cook, 2010; Miller, Andriacchi, & Nockerts, 2011).
우리나라에서도 제한적이긴 하나 언어재활사를 위한 컴퓨터 언어 분석 프로그램 개발이 시도되어 왔다. Korean Computerized Language Analysis (KCLA; Pae, 2000)는 가장 초기에 소개된 언어분석 프로그램으로 영어권에서 초기에 소개된 프로그램들과 마찬가지로 컴퓨터를 활용하여 분석자가 직접 분석을 실시해야 하였다. 최근에 KCLA를 보완하여 Korean Language Analysis (KLA; Pae, 2018)를 다시 소개하였으나 분석자가 직접 분석하는 방식은 그대로 유지되고 있다. 연구를 통해 소개된 Korean Spoken language Transcription, Analysis and Reporting System (KSTARS; Kim, Chang, Yoon, & Kim, 2013)는 KLA와 다르게 자동화된 형태소 분석을 실시하고 있으나, 연구목적으로 개발된 시스템이라 형태소를 분석하고 태깅한 결과만을 제공하며, 분석 결과를 요약해 주는 기능은 포함하고 있지 않다.
최근 자연어처리(NLP) 기술의 발전으로 국내에서도 네이버 클로바를 비롯하여 KoNLPy, KACTEIL-KMA, U-Tagger, Khaiii 등과 같은 크고 작은 컴퓨터 관련 회사들이 형태소분석기를 개발하여 공개하고 있다. 이러한 형태소분석기도 언어표본분석에 활용할 수는 있으나 분석에 활용하고 있는 형태소 체계가 각 시스템마다 다양하여 분석의 일관성을 확보하기 어렵고, 어휘나 문법 등의 언어능력을 확인하기 위한 언어 측정치들은 분석된 결과를 활용하여 직접 측정해야 하므로 언어 임상에 직접적으로 활용하는 것에는 제한이 있다.
이러한 배경 하에 본 연구자들은 언어재활사들의 언어표본분석을 지원하기 위한 목적으로 한국어 자동언어분석 시스템인 Hallym Systematic Analyzer of Korean (H-SAK; Hwang, Oh, Lee, & Kim, 2019)을 개발한 바 있으나 실제 사용을 위해서는 분석의 정확도나 결과로 제공하는 언어 측정 부분에서의 미흡함, 사용 편의성 등에서 보완이 필요하였다. 연구자들은 H-SAK에서 해결하지 못한 분석의 정확도 부분을 보완하고 언어평가에서 주요하게 측정하는 여러 측정치들의 자동 측정 기능을 추가하였으며, 사용 편의성 부분을 보완하여 Korean-Automatic Language Analysis System (K-ALAS)를 개발하게 되었다. 본 연구는 이러한 과정을 통해 개발된 K-ALAS의 신뢰도를 다음과 같은 두 가지 절차로 확인하고자 하였다. 첫째, K-ALAS에서 분석 단위로 활용하는 어절, 단어, 형태소 분석 정확도를 언어표본분석 전문가 검토 결과와의 일치도를 통해 확인하고자 하였다. 둘째, 어절, 단어, 형태소 단위로 K-ALAS가 자동으로 측정한 주요 언어 측정치들의 정확도를 언어표본분석 전문가가 측정한 언어 측정치들과의 차이검정 및 상관관계 분석을 통해 확인하고자 하였다.
연구방법
한국어 자동언어분석 시스템(K-ALAS)
K-ALAS는 한국어 자동언어분석 프로그램인 H-SAK (Hwang et al., 2019)을 수정 보완하여 개발된 웹 제공 형태의 한국어 자동 언어분석 시스템이다. 모태가 된 H-SAK ver.1은 Open-Source인 KoNLPy (Park & Cho, 2014)의 형태소분석기 중 kkma를 활용하여 자동으로 언어분석을 실행하도록 개발되었다. 초기에 개발된 H-SAK ver.1은 훈련된 언어표본분석 전문가와 분석 일치도를 측정하였을 때 약 71% 수준으로 정확도가 높지 않아 이를 해결하기 위해 본 연구자들이 언어분석의 기반으로 하는 표준국어문법 체계에 보다 적합하다고 판단된 U-Tagger (Shin & Ock, 2012)로 형태소 분석기를 교체하여 H-SAK ver.2를 개발하였다. 수정된 H-SAK ver.2의 정확도를 H-SAK ver.1과 같은 방식으로 측정한 결과 약 86%로 많이 향상되었으나 여전히 자동 형태소분석으로 해결하지 못하는 몇몇 오류들이 확인되었다. 이 문제를 해결하기 위해 몇몇 입력 코드를 만들었으며 사용자가 해당 코드를 쉽게 입력할 수 있도록 사용자 인터페이스(User Interface, UI) 방식을 추가하여 최종적으로 K-ALAS를 개발하였다.
K-ALAS의 웹 기반 서비스 체계는 자바 컴퓨터 프로그래밍 언어를 사용하여 설계하였다. K-ALAS는 언어표본분석 절차에 따라 언어표본 및 화자 정보 입력, 전사파일 입력, 분석 실행의 절차로 언어 분석을 진행하도록 설계하였으며, 미리 정의된 방식으로 전사 파일을 작성하여 언어표본을 입력하면 약 1, 2분 내에 분석 결과가 결과 요약지로 제공되도록 완성되었다. 앞에서도 설명하였듯이, K-ALAS는 표준국어문법(Nam & Go, 2014) 체계를 기반으로 형태소를 분석(parsing)하고 태깅(tagging)하며, 이를 토대로 언어병리학에서 주요 언어분석 측정치로 보고되고 있는 총단어사용빈도(Number of Total Word, NTW; Token), 단어유형수(Number of Different Word, NDW; type), 어휘다양도(Type-Token Ratio, TTR), 각각 어절, 단어, 형태소를 기준으로 측정한 평균발화길이(Mean Length of Utterance, MLU), 문법형태소인 조사와 어미, 품사별 단어의 사용빈도와 유형수 등을 자동으로 측정해서 측정치를 제공한다. 그 외 대화 담화나 화자가 보이는 오류는 사용자 인터페이스 방식으로 분석하여 그 결과를 자동 측정하도록 설계하였다.
언어표본
연구자가 구축한 자발화 데이터베이스 중 언어습득기에 있는 2세에서 6세 영유아의 언어표본을 무작위로 선택하여 연령별 10개 표본, 총 50개 표본을 신뢰도 분석에 사용하였다. 언어표본은 전형적 언어발달을 보이는 아동들을 대상으로 수집된 것으로, 주양육자나 유아교사 또는 보육교사에 의해 발달에 문제가 없다고 보고되고, 수용·표현 어휘력 검사(REVT; Kim, Hong, Kim, Chang, & Lee, 2009) 또는 영유아 언어발달검사(SELSI; Kim, Kim, Yoon, & Kim, 2003) 결과가 -1 표준편차 이상에 해당하는 아동 자료만이 포함되었다. 언어표본은 반구조화된 대화 절차를 통해 수집되었으며 각 아동별로 50발화씩, 동일하게 포함하였다. 신뢰도 분석에 활용된 발화는 연령별 500발화(50발화×10명), 전체 2,500발화(50발화×50명)였다(Table 1).

Language sample and participation information
분석 신뢰도
신뢰도 분석은 분석 단위인 어절, 단어, 형태소 분석 결과에 대한 K-ALAS와 언어표본분석 전문가 간의 일치도와 이를 기반으로 측정한 언어측정치들에 대한 독립표본 t-test 및 상관분석을 통해 실시하였다. 언어표본분석 전문가로는 언어표본분석 실시 경험이 많은 언어병리학 박사과정생이 참여하였다. 언어표본분석 전문가는 대학원 교과목과 여러 관련 워크숍을 통해 언어표본분석과 국어학에 대한 교육을 받았으며, K-ALAS 개발 과정 중 H-SAK ver.2와 K-ALAS로 분석한 형태소 태깅 결과에 대해 약 500사례 이상 후처리(post-editing) 작업을 실시한 등 언어표본분석 경험이 매우 많았다. 언어표본분석 전문가는 K-ALAS가 분석하고 태깅한 형태소를 검토하여 오류를 확인하였으며, 오류가 확인된 경우에는 2차로 국립국어원 표준국어대사전(https://stdict.korean.go.kr)을 통해 확인하는 절차를 거쳤다.
언어표본분석 전문가가 점검한 전체 언어표본의 20%를 무작위로 선정한 뒤 제1 연구자가 분석 정확도를 재점검하여 분석 일치도로 신뢰도를 확인한 결과, 분석 신뢰도는 99.07%로 측정되었다. 오류가 있었던 것은 대부분 동형이형태소(예: 감탄사와 부사의 “아니”, 대명사와 감탄사의 “어디”)로 문맥에 따라 형태소의 유형을 결정해야 하는 것이었으며 언어표본분석 전문가가 오류를 보인 것은 매우 소수였다.
어절, 단어, 형태소 분석 정확도
K-ALAS의 분석 정확도는 K-ALAS로 분석한 어절, 단어, 형태소를 언어표본분석 전문가가 재검토한 후 전체 어절, 단어, 형태소 분석 결과에서 분석이 일치한 어절, 단어, 형태소가 차지하는 일치도로 측정하였다. 어절은 분석(parsing)만, 단어와 형태소는 분석과 태깅이 정확히 이루어진 경우를 일치된 것으로 보았으며, 단어의 경우 표준국어문법의 9품사를 기준으로 한 경우(단어1)와 표준국어 문법의 9품사에서 자립형태소가 아닌 조사를 제외한 경우(단어2)로 구분하여 측정하였다. 어절, 단어, 형태소별 정확도 산출식은 다음과 같다.
(1) 어절일치도: 일치한 어절/(일치한 어절+불일치한 어절)×100
(2) 단어(단어1, 단어2)일치도: 일치한 단어/(일치한 단어+불일치한 단어)×100
(3) 형태소일치도: 일치한 형태소/(일치한 형태소+불일치한 형태소)×100
언어측정치 t-test 및 상관분석
K-ALAS와 언어표본분석 전문가가 독립적으로 측정한 언어측정치에 대해 독립표본 t-test를 실시하여 차이를 검정하고, 피어슨 적률상관분석을 통해 측정치 간의 상관관계를 확인하였다. 언어측정치는 K-ALAS가 제공하는 여러 언어측정치 중에서 사용자 인터페이스 방식으로 분석하지 않고, 형태소 자동분석을 기반으로 구문, 문법형태소, 어휘의미 영역에서 측정된 대표적인 언어 측정치만을 포함하였다. 분석에 포함된 언어측정치는 다음과 같다.
(1) 구문 영역: 어절, 단어, 형태소를 기반으로 측정한 평균발화길이(MLUe, MLUw, MLUm)를 포함하였다. 아동별로 전체어절(또는 단어, 형태소)빈도를 발화수로 나누어 측정하였다.
(2) 문법형태소 영역: 문법형태소 중 조사와 어미의 전체빈도(token)와 유형수(type)로 측정하였다.
(3) 어휘의미 영역: 전체 언어표본에서 측정된 전체단어빈도(NTW, token), 단어유형수(NDW, type), 어휘다양도(TTR)를 포함하였다. 어휘다양도(TTR)는 단어유형수(NDW)를 전체단어빈도(NTW)로 나누어 측정하였다.
연구결과
K-ALAS와 전문가 간 어절, 단어, 형태소 분석 정확도
영유아 50명의 언어표본에서 K-ALAS로 어절, 단어1 (표준국어 문법의 9품사, 조사포함), 단어2 (표준국어문법의 9품사 중 조사 제외), 형태소를 분석한 후 언어표본분석 전문가가 일치도를 통해 정확도를 확인하였다(Table 2).
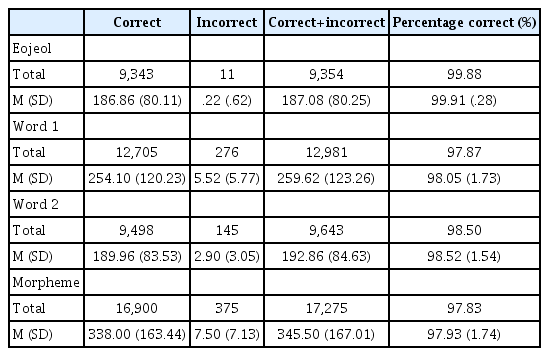
The agreement percent of language analysis between the K-ALAS and the experts
먼저, 어절은 전체 9,354어절 중에서 9,343어절이 일치하여 99.88%의 정확도를 보였다. 아동별로 측정된 정확도의 평균으로 측정하였을 때도 99.91%로, 전체 어절로 정확도를 측정한 것과 비슷하게 측정되었다. 단어1은 표준국어문법의 9품사 기준에 따라 단어를 측정한 결과로 전체 12,981개 단어 중 12,705개 단어가 일치하여 97.87%의 정확도를 보였으며(아동별 정확도의 평균 98.05%), 표준국어문법 9품사 중 조사를 제외하고 측정한 단어2는 전체 9,643 단어 중 9,498개가 일치하여 98.50%의 정확도를 보였다(아동별 정확도의 평균 98.52%). 마지막으로 형태소는 총 17,275 형태소 중 16,900개가 일치하여 97.83%의 정확도를 보였다(아동별 정확도 평균 97.93%). 정확도는 어절에서 가장 높고 형태소에서 가장 낮아 언어적 단위가 클수록 높았으며, 단위가 낮을수록 약간 낮아졌으나 거의 모두 97% 이상으로 매우 높은 정확도를 보였다(Figure 1).

The agreement percentage of language analysis between the K-ALAS and the experts.
K-ALAS와 전문가 간 언어측정치 측정 차이 및 상관관계
언어표본분석 결과를 토대로 K-ALAS가 자동으로 측정해서 제공하는 언어측정치와 전문가가 독립적으로 측정한 언어측정치 간의 차이와 상관관계를 확인하기 위하여 독립표본 t-test와 피어슨 적률상관분석을 실시하였다(Table 3).
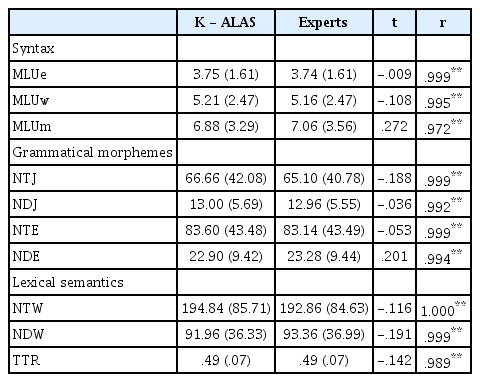
The results of t-test and correlation of the measures of the K-ALAS and the experts
먼저 구문 영역에서 K-ALAS가 자동으로 측정하여 제공한 평균 발화길이(MLUe, MLUw, MLUm)는 모두 전문가가 측정한 결과와 유의한 차이가 없었으며, K-ALAS와 전문가 간 상관관계분석 결과는 r=.972-.999로 모두 유의한 수준에서 매우 높은 상관을 보였다. 문법형태소 영역에서도 K-ALAS가 측정한 조사와 어미의 총사용 빈도(NTJ, NTE)와 유형수(NDJ, NDE)가 모두 전문가가 측정한 결과와 유의한 차이가 없었으며, K-ALAS와 전문가 간 상관관계분석 결과도 r=.992-.999로 모두 유의한 수준에서 매우 높은 상관을 보였다. 마지막으로 어휘의미 영역에서도 K-ALAS가 측정한 낱말 총 사용빈도(NTW)와 낱말유형수(NDW), 어휘다양도(TTR)도 모두 전문가가 측정한 결과와 유의한 차이가 없었으며, K-ALAS와 전문가 간 상관관계분석 결과도 r=.989-1.000으로 모두 유의한 수준에서 매우 높은 상관을 보였다(Table 3에서 각 언어 측정치의 표준편차가 높게 나타난 것은 아동별로 측정된 값이 다양하기 때문이며 측정 오차를 반영하는 것은 아님).
논의 및 결론
본 연구는 언어임상 활용을 목적으로 개발된 언어표본분석 시스템인 한국어 자동언어분석 시스템(K-ALAS)의 신뢰도 확인을 목적으로 하였으며, K-ALAS의 분석 단위로 활용하는 어절, 단어, 형태소의 분석 정확도와 K-ALAS가 자동으로 측정한 주요 언어측정치의 신뢰도 두 가지를 중심으로 확인하였다.
K-ALAS의 어절, 단위, 형태소 분석 정확도
먼저 K-ALAS의 분석 단위인 어절, 단어, 형태소를 얼마나 정확하게 분석하는가는 K-ALAS가 분석한 결과와 언어표본분석 전문가가 분석한 결과 간의 일치도로 측정하였다. 컴퓨터가 분석한 결과를 전문가가 검토하여 일치도를 측정한 Hewitt, Hammer, Yont와 Tomblin (2005)의 연구를 참조하여 본 연구에서도 K-ALAS가 형태소별로 분석하고 태깅하여 제공한 결과를 언어표본분석 전문가가 검토하여 서로 간에 정확한 것(일치)과 정확하지 않은 것(불일치)을 확인한 후 일치도를 측정하는 절차를 따랐다. 정확한 것은 분석(parsing)과 태깅(tagging)이 모두 정확히 이루어진 것만을 포함하였으며, 분석이나 태깅 둘 중 하나라도 정확하지 않은 경우는 부정확한 것으로 분류하여 측정하였다.
분석 단위에 대한 K-ALAS와 전문가의 일치도를 측정한 결과, 어절은 99.88%, 표준국어문법의 9품사 기준에 따라 분석한 단어1은 97.87%, 표준국어문법 9품사 중 조사를 제외하고 분석한 단어2는 전 98.50%, 마지막으로 형태소는 97.83%의 정확도를 보여 거의 모두 97% 이상의 정확도로 매우 높은 정확도를 보였다. SALT-2는 분석 정확도가 보고되어 있지 않으며, 정확도가 보고된 CLAN (Mac-Whinney, 2000)의 경우 형태소를 기준으로 하였을 때 평균적으로 94%의 정확도(Pezold et al., 2020)가 나타나, K-ALAS의 분석 정확도는 상당히 높은 것으로 고려된다. 국내에 공개되어 있는 한국어 형태소분석기들은 약 50% 내외(kkma의 명사 정확률, Kang & Yang, 2018)의 정확도를 보고하고 있다. 그러나 정확도가 어떠한 방식으로 측정되었는지 밝히고 있지 않은 경우가 대부분이며, 각 형태소분석기마다 자체적인 형태소 분석 체계로 분석하고 있으므로 각각의 정확도를 상대적으로 비교하기 어렵다. 본 연구자들은 10문장으로 구성된 언어표본을 각각의 형태소분석기로 분석하여 K-ALAS와 동일한 방식으로 정확도를 측정하여 약식 비교해 보았는데 75%에서 92.47%의 정확도가 측정되었다. 이는 K-ALAS가 표준국어문법 체계를 기반으로 분석할 때 현재 공개되어 있는 형태소분석기들과 비교해서도 우수한 정확도를 보이는 것으로 확인되었다.
K-ALAS의 정확도는 가장 큰 단위인 어절에서는 99.88%로 거의 오류가 없었으나 조사 포함 단어(단어1)는 97.87%, 조사 제외 단어(단어2)는 98.50%, 형태소는 97.83%으로 약간의 오류가 관찰되었다. 단어에서는 수관형사와 수사에서의 태깅 오류(예, “여섯 살”의 ‘여섯’을 수관형사가 아닌 수사로 태깅), 문법형태소에서는 부사격 조사와 접속조사에서의 태깅 오류(예, “아빠하고 엄마랑 밥 먹었어요”의 ‘-하고’를 부사격조사로 태깅하거나 ‘-랑’을 접속조사로 태깅), 어미 분석 및 태깅 오류(예, “중학생이에요”와 같이 체언에 어미가 연결된 문장의 어미 분석 및 태깅 오류)가 주로 확인되었다. KALAS로 분석한 결과를 활용할 때 참조하도록 권장되며, 추후 이 부분을 해결하기 위한 방안 모색이 요구된다.
Lee 등(2020)이 언어재활사를 대상으로 언어표본분석 실태에 대해 조사한 자료에서 언어재활사들은 언어표본분석을 실시하지 못하는 이유로 언어분석의 전문성이 부족하다는 것을 응답하였다. 실제 언어표본분석은 언어병리학 또는 언어치료학 전공 교육 및 훈련에서 많은 시간을 할애하는 부분이지만 학생은 물론 훈련된 언어재활사나 언어표본분석 전문가들도 100% 정확한 분석은 거의 불가능하다. Ratner와 MacWhinney (2016)도 아무리 훈련된 전문가라 할지라도 100% 정확하게 언어표본분석을 실시하는 건 가능하지 않다고 서술한 바 있다. 본 연구를 통해 확인된 K-ALAS의 정확도는 거의 100%에 가까운 분석 정확도를 보여 언어재활사들을 대체하여 활용하는 데 충분하다고 판단되며, 언어표본분석 절차를 활용한 다양한 연구에서도 유용하게 활용될 수 있음을 시사한다.
K-ALAS의 언어측정치 측정 신뢰도
분석된 어절, 단어, 형태소를 기반으로 K-ALAS가 자동으로 측정한 주요 언어측정치의 정확도를 확인하기 위해 언어표본분석 전문가가 측정한 언어측정치들과의 차이검정 및 상관관계 분석을 실시하였다. 구문, 문법형태소, 어휘의미 세 영역으로 나누어, 구문 영역에서 어절, 단어, 형태소를 기반으로 측정한 평균발화길이(MLUe, MLUw, MLUm), 문법형태소 영역에서 조사와 어미의 전체빈도(token)와 유형수(type), 그리고 어휘의미 영역에서 전체단어빈도(NTW, token), 단어유형수(NDW, type), 어휘다양도(TTR)에 대해 측정 신뢰도를 확인하였다.
먼저 구문 영역에서 K-ALAS가 측정한 평균발화길이(MLUe, MLUw, MLUm)는 모두 전문가가 측정한 결과와 유의한 차이가 없었으며, K-ALAS와 언어표본분석 전문가 간 상관분석 결과도 r=.972-.999로 매우 높은 상관을 보였다. 실제 K-ALAS와 언어표본분석 전문가가 측정한 MLUe는 각각 3.75와 3.74, MLUw는 5.21과 5.16, MLUm은 6.88과 7.06으로 0.01-0.18 정도의 매우 낮은 차이를 보였다. 이러한 차이는 K-ALAS가 분석의 단위로 삼고 있는 어절, 단어, 형태소 분석 정확도와 관련된 것으로 가장 높은 분석 정확도를 보인 어절로 측정한 MLUe에서 K-ALAS와 언어표본분석 전문가 간의 차이가 가장 적었고, 분석 정확도가 상대적으로 약간 낮았던 형태소로 측정한 MLUm에서 비교적 차이가 컸다.
문법형태소 영역에서도 K-ALAS가 측정한 조사와 어미의 총사용빈도(NTJ, NTE)와 유형수(NDJ, NDE)가 모두 전문가가 측정한 결과와 유의한 차이가 없었으며, K-ALAS와 언어표본분석 전문가 간 상관분석 결과도 r=.992-.999로 상관계수가 거의 1에 가까운 매우 높은 상관을 보였다. 앞에서 언급하였듯이 K-ALAS는 부사격 조사와 접속조사 태깅 오류와 같이 형태가 같은 조사를 구분하는 것에서의 문제, 불규칙한 형태로 사용된 어미의 분석 및 태깅에서의 오류를 여전히 보이고 있었다. 많은 경우 문맥적 정보에 따라 정확하게 분석하나 간혹 문맥 정보가 충분하지 않을 때에는 오류가 나타날 수 있으므로 해당 형태소로 태깅된 결과는 후처리(post-editing)를 통해 오류를 수정하여 결과를 측정하여야 할 것이며, 추후 K-ALAS에서도 이러한 오류를 해결하기 위한 노력이 있어야 할 것이다.
마지막으로 어휘의미 영역에서도 K-ALAS가 측정한 낱말 총사용빈도(NTW)와 낱말유형수(NDW), 어휘다양도(TTR)가 모두 전문가가 측정한 결과와 유의한 차이가 없었으며, K-ALAS와 전문가 간 상관분석 결과도 r=.989-1.000으로 매우 높은 상관을 보였다. 이는 K-ALAS가 보이는 단어 분석에서 수관형사와 수사 태깅에서의 오류와 관련되는 것으로 일부 조사 또는 어미 오류와 마찬가가지로 해당 분석 결과는 후처리(post-editing)를 통해 오류를 수정한 후 결과를 측정하도록 제안하며, 추후 K-ALAS에서 이러한 오류를 해결하기 위한 노력이 있어야 할 것이다.
언어표본분석 전문가가 측정한 언어측정치 결과와의 차이 비교와 상관관계 분석 결과는 K-ALAS가 구문, 문법형태소, 어휘의미 영역의 주요 측정치들을 신뢰롭게 측정하고 있음을 보여 준다. 언어표본분석 결과 중 평균발화길이(MLU)와 낱말 총사용빈도(NTW)나 낱말유형수(NDW), 어휘다양도(TTR)는 언어발달 정도를 나타내는 주요 지표로 받아들여지고 있으며(Owens, 2014; Paul & Norbury, 2012), 실제 어린 연령에서는 아동언어장애를 결정하는 기준으로 제안되기도 한다(Rice et al., 2010; Sandbank & Yoder, 2016; Watkins, Kelly, Harbers, & Hollis, 1995). K-ALAS는 이러한 주요 언어측정치를 비교적 정확하게 측정하여 K-ALAS 결과를 화자들의 언어 사용 정보를 확인하는 데에는 물론 언어장애 진단적 목적으로도 활용 가능할 수 있음을 시사한다.
이상을 통해 K-ALAS의 언어표본분석 정확도와 언어측정치 측정 신뢰도를 확인하였다. 이미 앞에서 서술하였듯이 K-ALAS는 전사된 자료를 업로드하면 발화량과 상관없이 1, 2분 내에 한국어 표준국어문법의 형태소 체계를 기반으로 형태소를 분석하고 태깅한 결과를 제공한다. 또한 언어표본분석의 주요 측정치들에 대한 결과를 표로 요약해서 제공한다. K-ALAS는 여러 이유로 언어표본분석이 어려운 언어재활사들의 시간과 노력을 경감시켜 주면서 신뢰로운 결과를 제공해서 언어 진단이나 언어치료를 목적으로 한 평가와 중재 효과를 모니터링하는데 포괄적으로 사용될 수 있을 것으로 기대된다.