6세 아동의 읽기 유창성 예측 의사결정나무 모델: 언어 및 초기 문해능력, 말소리능력, 성별, 연령, 사회경제적 지위를 중심으로
Predicting Reading Fluency Groups Using Decision Trees in 6-Year-Old Children: Focusing on Language, Early Literacy, Speech Sound Ability, Gender, Age, and SES
Article information
Abstract
배경 및 목적
본 연구에서는 6세 학령전 아동들의 한글 읽기 유창성 수준과 읽기 관련 개별변수들의 관계를 우선 살펴보고, 개별변수를 적용한 모델이 읽기 유창성 수준을 예측하는 것이 유용한지 살펴보았다.
방법
한국아동패널연구(PSKC, Panel Study on Korean Children) 6세 대상자 1,343명을 대상으로 읽기 유창성 22개 예측 변수를 CHAID (Chi square Automatic Interaction Detector) 알고리즘을 적용한 의사결정나무 분석(Decision Tree Analysis, DTA)을 실시하였다.
결과
일반(성별, 월령), SES (월 평균 가구 소득, 엄마의 학력), 말소리 및 인지언어 측정변수(조음평정치, 모방오류어절지수), 학업능력과 인지(언어 및 문해능력, 주의력결핍) 특성에 대한 개별변수에 대해 살펴본 결과, 월 평균 가구 소득 변수를 제외한 측정변수가 읽기 유창성 집단에 따라 유의미한 차이를 보이는 것으로 나타났다. 그리고 읽기 유창성에 유의미한 영향을 미치는 변수는 7가지 변수(엄마가 평가하였을 때 아동이 혼자서 간단한 책을 스스로 읽는 정도, 월령, 성별, 모방오류어절지수, 말소리 조음평정치 수준, 담임교사가 평가하였을 때 한글 자음과 모음을 쉽고 빠르게 말하는 수준, 담임교사가 평가하였을 때 단어의 운율을 맞추어 말하는 정도)인 것으로 나타났다.
논의 및 결론
읽기 유창성 DTA 모델은 초등학교 입학 예정 대상자들의 읽기 유창성을 구분하여 읽기지도가 추가적으로 필요한 대상자를 선별하는 모델로서 적용할 수 있을 것이다. 그리고 읽기 유창성에는 이미 선행연구로 알려져 있는 아동 개별 및 환경요인인 엄마의 학력과 문해환경, 성별과 연령, 자음과 모음 낱글자에 대한 읽기와 음운인식 이외에 ‘말소리 조음능력과 모방오류어절지수’가 포함됨을 알 수 있었다.
Trans Abstract
Objectives
The purpose of this study was to examine the relationship between the level of Korean reading fluency and individual variables related to reading in children before the age of 6, and whether it is useful for the model to which individual variables are applied to predict the level of reading fluency.
Methods
In this study, 343 6-year-old subjects of PSKC (Panel Study on Korean Children) in this study, DTA was conducted using the CHAID algorithm.
Results
As a result of examining individual variables for general (gender, monthly age), SES, speech, and cognitive language measurement variables (level of speech sound disorder, word error index in sentence repetition), academic and cognitive skill (language and literacy, attention deficit); the measurement variables showed significant differences depending on the reading fluency group. In addition, seven variables significantly affected reading fluency (Reads first-grade books independently when evaluated by a mother, age, gender, word error index in sentence repetition, level of speech sound disorder, and reading all the consonants and vowels of Hangul when evaluated by a homeroom teacher, making rhyme words when evaluated by a homeroom teacher).
Conclusion
The reading fluency DTA model can be applied as a model for selecting subjects who need additional reading guidance by classifying the reading fluency of those who are scheduled to enter elementary school. In addition to reading and phonological recognition of children’s individual and environmental factors already known in previous studies; the maternal educational level, gender, and age, consonants & vowels, reading ability, and word error index in sentence repetition were included.
읽기 교육은 국립읽기위원회 보고서(National Reading Panel Report, NRP Report; National Institute of Child Health and Human Development, 2000)의 영향을 많이 받았다. NRP 보고서에는 읽기 교육을 위해 중요시되는 5가지 인지전략 기술로 ‘음소인식(phonemic awareness), 발음중심교수법(phonics), 읽기 유창성(fluency), 어휘력(vocabulary), 이해(comprehension)’를 제시하고 있다(Chang, 2015). 그리고 NRP 보고서의 종합 결과에는 읽기를 위한 정책, 교육, 평가 방법 이외에 읽기를 잘 하는 대상자와 읽기에 어려움을 보이는 대상자들의 개인차 요인이 있을 수 있음도 제시되어 있다. 하지만 NRP 보고서에서 읽기능력을 평가하는 방법으로 제시한 것은, 문맥 내에서 또는 개별 어휘를 정확하게 읽기, 의미가 없는 비단어 읽기 정확성, 텍스트를 소리 내어 읽거나 조용하게 소리 내지 않고 읽은 후에 내용 이해를 평가하는 것이다. 즉, NRP 보고서에는 읽기에 대한 주요 변수로 언급하고 있는 5가지 인지전략기술 이외의 읽기와 관련된 언어 및 환경적 개인차 변수에 대한 고려가 되어 있지 않다.
NRP 보고서에 언급되어 있지 않은, 읽기와 관련된 다양한 개별 대상자의 인지, 정서, 능동성과 같은, 개인차 요인들은 주로 심리학과 교육학 등에서 연구되어왔다(Corno, 2003; Ho, Tomlinson, & Whipple, 2003; Kyllonen & Gitomer, 2003; Magliano & Perry, 2008). 이러한 개인차 연구는 매우 어린 시기 때부터 나타나는 것으로 아동 및 학생 개인의 인지 및 언어능력과 기질, 환경적인 요인 등이 읽기발달에 영향을 미치고 있음을 제시하고 있다. 그리고 읽기 개인차를 살펴보는 것은 개별화 읽기 교육에 있어 최적의 적합한 교육방법 또는 중재법을 제시해 줄 수 있을 것으로 여겨지고 있다. 이러한 읽기발달 개인차 연구에서 주로 살펴보고 있는 것은 개인차가 주로 대상자의 인지와 읽기능력 결과에 어떠한 영향을 미치고 있는지 그리고 읽기처리를 위해 요구되는 개별 역량과 기술 차이는 어떠한지 등에 대한 것이다(Kyllonen & Gitomer, 2003; Magliano & Perry, 2008).
읽기발달 단계(Chall, 1996)에 의하면, 읽기 유창성은 읽기발달 세 번째 단계에 속한다. 읽기발달 첫 번째 단계는 음소를 조작하고 책에 관심을 가지며, 몇 가지 일견단어(sight words)를 읽는 초기 문해 단계이다. 그리고 두 번째 단계에서는 음소를 문자소와 연결하여 기본 자음과 모음 결합 문자를 해독할 수 있는 단계에 속한다. 일반적으로 아이들은 첫 번째와 두 번째 읽기발달 단계에서 기초적인 읽기기술을 습득하고, 이후 세 번째 단계에서 유창하게 읽기가 발달하게 된다. 그리고 Chall (1996)의 읽기발달 모델에 따르면, 아이들은 대부분의 어휘를 유창하게 읽을 수 있게 되었을 때, 텍스트를 읽으면서 학습하는 것이 가능해진다. 즉, 세 번째 읽기발달 단계까지 읽기를 위한 학습이 이루어지고, 이후 네 번째 읽기발달 단계부터는 읽기가 새로운 세상 지식과 고차원적 사고 학습을 위한 도구가 되는 전환기적 시점이 이루어진다고 보고 있다(Chall & Jacobs, 2003). 하지만 이러한 읽기발달 단계에 대한 구분은 그렇게 명확하고 빠르게 이루어지는 것이 아니라는 비판이 계속되고 있다(Afflerbach, 2016). 읽기를 위한 학습과 학습을 위한 읽기라는 이분법적인 읽기발달 단계 구분이 읽기기술에서 명확하게 나타나는 것은 아니기 때문이다. 왜냐하면 읽기를 위한 학습이 유창하게 읽기 단계에 도달하였다고 멈추는 것은 아니기 때문이다. 그러므로 읽기 유창성을 기준으로 한 읽기발달의 이분법적인 사고에 대한 논쟁은 계속되고 있다.
6세 아동은 언어발달에 있어 중요한 전환점을 맞이하는 시기이다(Bishop & Adams, 1990; Shriberg & Kwiatkowski, 1988). 왜냐하면 초등학교 입학 후 의무교육을 받기 위해 필요한 읽기를 위한 학습을 시작하는 시기이기 때문이다. 문해력에 있어 이 시기의 아동은 일반적으로 글자를 천천히 쓰면서 소리 내어 말하거나, 아는 단어를 반복해서 쓰기도 하고, 같은 유형의 문장에서 단어만 바꾸어 반복해서 쓰기를 즐긴다. 그리고 초등학교 입학 후 본격적으로 문해학습이 이루어지면서, 초등학교 1학년 학생들의 전반적인 읽기 유창성은 발달한다. 읽기 유창성을 정확성 측면에서 살펴보면 한국의 초등학교 1학년 학생들의 자동성(1분 동안 읽기 정확성) 평균은 1학년 초반에는 50어절, 1학기 말경에는 57어절, 2학기 초반에는 59어절, 2학기 말에는 63어절을 읽는 것으로 나타났다(Pang & Yoon, 2021). 미국의 경우에는 50백분위에 해당하는 초등학교 1학년 학생들의 읽기 자동성 단어 평균이 겨울평가에서는 29단어, 다음해 봄 기준 평가에서는 60단어였다(Hasbrouck & Tindal, 2017). 두 연구의 결과에서 한국어 어절을 영어의 단어와 비교하였을 때, 한국의 초등학교 1학년 학생들이 읽기 정확성은 더 빠르게 진행된 것을 알 수 있다.
한글은 영어보다 상대적으로 표기심도가 낮기 때문에, 더 어린 시기부터 읽기에 대한 학습이 빠르게 이루어지는 부분이 있다. 그러므로 초등학교를 입학하기 전에 한글을 읽고 쓸 줄 아는 비율이 높다. 한국에서는 입학 초기 아동의 90.8%가 간단한 구절을 읽을 수 있고, 97.4%가 기본 음절 이상을 읽을 수 있다고 평가하며(Park et al., 2006), 교사들의 30.4%가 입학 후 5월 이후부터, 24.8%는 4월부터 받아쓰기를 실시한다(Ahn, 2003). 즉, 유치원에서는 읽기를 직접 가르치는 것을 공식적인 목표로 삼고 있지 않지만 초등학교 입학 6개월 전부터 이미 읽기 교육이 시작되고 초등학교 입학 직전에 대부분의 아동이 글을 읽을 수 있다(Chang, 2015).
한글보다 자소와 음소의 대응관계가 더 불규칙한 영어의 경우 읽기 유창성을 초기 읽기발달의 지표에 포함하지 못하지만(Parrila, Aunola, Leskinen, Nurmi, & Kirby, 2005), 자소-음소의 관계가 비교적 규칙적인 독일어의 경우 단어 읽기의 속도가 잘 읽는 아동과 잘 읽지 못하는 아동을 예측하는 유일한 측정치였다(Landerl & Wimmer, 2008). 이러한 결과로 미루어 볼 때 자소-음소 관계가 규칙적인 편에 속하는 한글의 경우에는 특히 대다수의 아동이 한글 단어 읽기가 가능한 만 5세부터 읽기 유창성이 중요한 읽기발달의 지표가 될 수 있다(Chang, 2015). 그리고 한글의 규칙적인 문자 체계와 더불어 한글 교육에 대한 부모들의 관심과 직접 가르치는 경험도 한글 습득에 중요한 역할을 한다. 우리나라의 읽기 교육은 공식적으로는 만 6세에 초등학교 입학과 함께 시작되는 것으로 되어 있지만, 실제로는 이전에 유치원과 가정의 사교육으로 이미 시작된다(Chang, 2015).
읽기 유창성은 정확하게 읽는 것과는 다른 개념으로 연구자에 따라 그 정의가 다양하다. 즉, 읽기 이해의 과정 없이 빠르고 정확하게 읽는 것으로 정의되기도 하고(Wolf & Katzir-Cohen, 2001), 정확하고 자동화된 단어재인능력을 의미하기도 한다(Hudson, Pullen, Lane, & Torgesen, 2009; Rasinski, Rikli, & Johnston, 2009). 또한 읽기 유창성에서 가장 중요한 것으로 운율을 잘 살려 소리 내어 읽는 것이라 보기도 하고(Samuels, 2006), 텍스트를 정확하게 읽고 동시에 이해하는 것으로 정의하기도 하였다(Samuels, 2006). 위의 연구결과들을 모두 종합하면 읽기 유창성에서 요구되는 요소는 정확성(accuracy)과 자동성(automaticity), 운율감(prosody)과 같은 세 가지로 구분하여 볼 수 있다(Kuhn, Schwanenflugel, & Meisinger, 2010).
읽기 유창성은 읽기 이해 증진과 깊은 관계가 있다(Chang, 2015; Schwanflugel et al., 2009). 초등학생의 경우는 읽기 속도와 운율감 측정결과로 살펴본 읽기 유창성이 읽기 이해와의 상관결과 .50에서 .85사이로 매우 유의미하게 높은 상관이 있는 것으로 나타났다(Reschly, Busch, Betts, Deno, & Long, 2009). 또한 소리 내어 유창하게 읽기가 가능한 대상자들은 이후에 읽기 이해 능력이 유의미하게 높게 나타났다(Kim, Petscher, Schatschneider, & Foorman, 2010). 여기에서의 읽기 유창성은 읽기 속도만을 의미하는 것은 아니고 적절한 속도에 맞게 표현감을 살려 읽는 유창함이 필요하다고 한다. 물론 읽기 유창성이 반드시 읽기 이해를 보장하는 것은 아니다. 몇몇 연구에서는 초등학교 고학년과 중학생의 경우는 읽기 유창성과 이해와의 상관이 .50-.60으로 초등학생의 상관결과보다는 약간 낮은 관계를 보였다(Denton et al., 2011; Silberglitt, Burns, Madyun, & Lail, 2006). 이러한 결과는 연령이 증가하면서 텍스트의 난이도가 변화하였기 때문으로 해석하고 있다. 즉, 연령이 증가할수록 읽기 텍스트는 더 많은 배경지식이 요구되며, 난이도 높은 어휘가 많이 포함되어 있으며, 텍스트 해석을 위해 더 많은 언어추론이 요구되기 때문이다. 즉, 읽기 이해를 위해서는 읽기 유창성 이외에 어휘력, 주제관련 지식, 언어능력, 추론능력 등이 요구되기 때문이다(Kim & Park, 2021).
이중언어 학생의 제2언어에 대한 문해능력 발달 연구는 읽기 이해와 읽기 유창성 관련성 해석에 함의를 가진다. 모국어가 영어가 아니면서 영어를 배우는 학생(English learners, ELs)의 읽기 유창성과 읽기 이해와의 상관도는 .40-.60이었고 non-ELs 학생은 .50-.85이었다(Crosson & Lesaux, 2010; Quirk & Beem, 2012). 연구결과 어휘력과 듣기 이해와 같은 영어능력이 읽기 이해 능력에 조절변수로 작용한 것으로 해석할 수 있었다(Crosson & Lesaux, 2010; Quirk & Beem, 2012). 그러므로 ELs 학생들의 읽기 유창성과 읽기 이해 능력과의 상관관계 연구를 통해서, 우리는 언어능력이 읽기 유창성과 읽기 이해와의 관계에 있어 유의미한 영향을 미치는 변수라는 것을 확인할 수 있다(Quirk & Beem, 2012).
소리 내어 읽기를 잘 하는 아동 중에 읽기 이해가 낮은 대상자들도 있다. 이러한 대상자들은 단어호명자(word callers)라고 지칭되고 있다(Applegate, Applegate, & Modla, 2009). 하지만 여전히 읽기를 어려워하는 대상자와 읽기를 배우기 시작하는 아동에게는 읽기 유창성이 읽기 이해로 진입하기 위한 진입장벽으로 여겨지고 있다(Brasseur-Hock, Hock, Kieffer, Biancarosa, & Deshler, 2011; Rasinski et al., 2009). 읽기를 배우는 학령 초기의 대상자들에게는 소리 내어 유창하게 읽는 것이 읽기발달의 전환기적 단계이다. 그리고 학령 중기까지 유창하게 텍스트를 읽는 기술을 습득하지 못한 아동은 이후 소리 내지 않고 텍스트를 읽는 묵독 단계에서 읽은 내용을 이해하는 것에 어려움을 보이는 것으로 나타났다. 하지만 음독에서 묵독으로 전환하기 위해서는 얼마나 유창하게 잘 소리 내어 읽을 수 있어야 하는지, 그리고 어떻게 음독에서 묵독으로의 전환을 하는 것이 좋은지에 대한 것은 아직 정확하게 정리되지 않았다(Pang & Yoon, 2021; Schwanenflugel & Kuhn, 2016). 하지만 중요한 것은 읽기 유창성이 읽기 이해로의 전환에 있어 중요한 부분이며, 읽기에 대한 개인차와 관련된 변인을 이해하는 것이 읽기를 시작하거나 읽기에 어려움을 보이는 대상자 중재를 위해 필요한 부분이라는 것이다(Pang & Yoon, 2021).
개인차 변수가 어떻게 읽기발달에 있어 차이를 야기하는 것일까? 읽기발달에 있어 개인차 변수에 대한 개념 모델을 살펴보면 읽기발달은 기본, 확장, 그리고 맥락관련 변수들이 3가지 단계로 이루어져서 변수들 간의 상호작용에 의해 발달한다고 보고 있다(Loughlin & Alexander, 2016) (Figure 1). 기본 1단계(Tier 1) 변수에는 지각(Gibson, 1994; Peirce, 1955), 주의(Wertheimer, 1923), 기억(Baddeley, 2003), 변별(Peirce, 1955), 메타인지(Veenman, 2011), 관계적 사고(Dumas, Alexander, & Grossnickle, 2013)와 같은 인지 신경학적 개별 변수가 포함되어 있으며 읽기발달 이외의 인간발달 전반에 영향을 미치는 변수이다. 그리고 읽기와 관련된 확장 2단계(Tier 2)에는 선행지식(Alexander & Judy, 1988), 고차원적 사고(Schraw & Robinson, 2011), 이해(McNamara & Kintsch, 1996), 어휘력(Nagy, Herman, & Anderson, 1985; Yoon, 2019; Yoon & Park, 2022), 동기(Guthrie & Wigfield, 1997), 자기효용감(Bandura, 1982), 음운인식(Lee, Kim, & Hwang, 2018), 단어재인(Yang, Kim, & Ra, 2017) 등과 같은 변수들이 포함되어 있다. 이러한 확장 2단계는 기본 1단계 변수에 의해 영향을 받는 변수들이다. 그리고 1단계와 2단계는, 마지막으로 사회문화 및 언어, 교육학적 개인차 맥락 변수에 포함된다(Afflerbach, 2016). 사회문화 및 언어, 교육학적 개인차 변수는 성별, 학교, 언어능력과 사용언어, SES, 교육방법, 가정이나 학교 환경과 같이 매우 포괄적인 변수이다(Figure 1).

Conceptual model of individual differences in reading.
Source: Loughlin & Alexander (2016).
사회문화 및 언어, 교육학적 개인차 맥락 변수 중 이번 연구의 측정변수들에 대한 선행연구를 살펴보면 다음과 같다. 우선, 성별에 따른 초등학교 1학년 학생들의 읽기 자동성 결과, 여학생들의 읽기 자동성이 남학생들의 자동성보다 높다. 이것은 읽기와 관련된 다양한 성취, 즉 단어 읽기, 어휘, 읽기 이해에서도 일반적으로 나타나는 현상인데, 대체로 여학생들이 언어능력, 학습 동기, 뇌의 활성화, 학습 전략 등에서 남학생들보다 우수한 것으로 나타났다(Logan & Johnston, 2010). 그리고 학령전기에 말소리지각과 음운인식 문제, 의미와 구문 언어발달 지체를 보였던 아동들은 학령기에 읽기 문제를 동반하는 경향이 있다. 또한 역으로 읽기 문제로 인해 어휘발달, 구문과 문법 구조 발달에 제한을 보일 수 있으며, 이들 대상자들은 학령기에 읽기장애로 진단될 확률이 높았다(Bishop & Adams, 1990; Shriberg & Kwiatkowski, 1988). 음운인식은 언어의 말소리체계 지식을 의미한다. 좀 더 세부적으로 살펴보면 음절, 음소 등을 조작하여 말소리를 만들 수 있는 능력을 의미한다. 그러므로 음운인식은 말소리발달의 척도로 작용하며, 읽기 유창성을 예측하는 주요 변수인 것으로 알려져 있다(Ehri, 1995; Georgiou, Parrila, & Papadopoulos, 2008; Speece, Mills, Ritchey, & Hillman, 2003). 현재 초기 문해학습 단계에서 음운인식 훈련은 해독능력과 학령 초기 읽기 유창성 증진에 도움이 되는 것으로 밝혀졌다(Reading & Van Deuren, 2007).
읽기 유창성은 읽기 개인차 연구에서 매우 중요한 의미를 갖는다. 정확하게 표현감을 살려서 텍스트를 읽는 읽기 유창성은 학령 초기 읽기능력을 측정하는 주요 수단이며, 이후 읽기 이해 능력을 예측할 수 있는 주요 변수이다. 느리고, 정확하지 못하고 표현감 없이 읽는 학생들은 이후에 읽기 이해 평가에서 낮은 점수를 받는 경향이 있고, 유창하게 읽는 대상자들은 이해능력도 높은 편이다. 낮은 읽기 유창성은 텍스트에서 나타나는 사실적 정보에 접근하거나 이해하는 인지적인 처리에 저해가 되어 높은 수준의 읽기 이해가 어렵다. 하지만 ELs 학생의 연구결과에서도 나타났듯이 읽기 유창성이 읽기 이해의 필요 충분조건이 되지는 않는다. 듣고 말하는 언어 이해에 대한 기초가 낮으면 읽기 이해 능력은 낮을 수밖에 없다.
이번 연구의 목적은 읽기 문제가 나타날 경향이 높은 아동을 선별하는데 도움이 될 수 있는 요인들을 구별하여 읽기 예측요인을 알아보는 것이다. 그리고 읽기 이해를 예측하는 초기 변수는 읽기 유창성으로 하여 유창성과 관련된 읽기 이해 개인차 변수를 이용하여 분석하였다. 이번 연구를 통해 읽기 유창성을 예측하는 개인차 모델을 적용하여 읽기관련 변수들의 관계를 통해 초기 읽기 중재가 요구되는 대상자들을 미리 선별할 수 있다면 이후 읽기 문제로 인해 학습지체를 야기할 수 있는 대상자를 예방할 수 있다는 취지에서 진행하였다. 특히 언어치료 영역에서 읽기와 관련된 것으로 보이는 말소리능력과 언어적 오류 측면이 추가되었을 때의 읽기 유창성 개인차가 적용되는 부분을 살펴보고자 하였다. 또한 이번 연구는 의사결정나무 모델 평가를 통해 초기 읽기 대상자들의 읽기 유창성 집단을 구분하는 예측모델을 구상하였다. 구체적인 연구문제는 다음과 같다.
연구문제
학령 전 6세 아동의 읽기관련 개별변수를 적용한 읽기 유창성 수준(일반적, 약간 비유창함, 매우 비유창함, 읽지 못함) 예측 모델은 어떠하며, 모델은 읽기 유창성 집단을 구분하는 데 유용한가?
연구방법
연구대상
한국육아정책연구소(Korea Institute of Child Care and Education, KICCE)는 아동의 성장·발달을 이해하고 이에 영향을 미치는 요인을 파악하기 위해서 2008년 4월에서 7월 사이에 의료기관에서 출생한 전국 신생아 2,000가구를 조사 모집단 표본으로 하여 한국아동패널연구(Panel Study on Korean Children, PSKC)를 진행하고 있다. PSKC는 패널이 성인기에 접어드는 2027년까지 총 20년간 전반적인 아동발달 특성과 부모 특성, 가정 환경 특성, 교육(학교 및 사교육) 특성, 지역사회 특성, 정책 특성 자료를 수집하는 장기 종단연구이다.
본 연구는 한국아동패널연구(PSKC, Panel Study on Korean Children) 7차 2014년 6세 대상자 중 읽기 유창성 검사에 참여한 1,343명의 데이터를 사용하였다. 7차년도 종단 대상자 모두는 2008년에 태어났으며 종단 과제 참여시에 연령은 모두 6세로 동일하였다.
측정변수
인구학적 특성: 성별, 연령, 사회경제적 지위
한국아동패널에서는 매년 대상자에 대한 기본발달 환경에 대한 조사가 진행된다. 조사되는 내용 중 대상자의 언어 및 말소리발달과 관련된 변인으로 대상자의 성별, 연령, 사회경제적 지위(Socio-economic status, SES: 가정 내 연 수입 정도, 엄마의 최종학력)를 측정변수에 포함하였다. 패널 기본 설문과 평가는 면접원이 가정 방문을 하여 지필식 설문 조사(Paper and Pencil Interviewing, PAPI)로 진행하였다.
문장 따라말하기: 모방오류어절, 읽기 유창성, 말소리 조음평정치
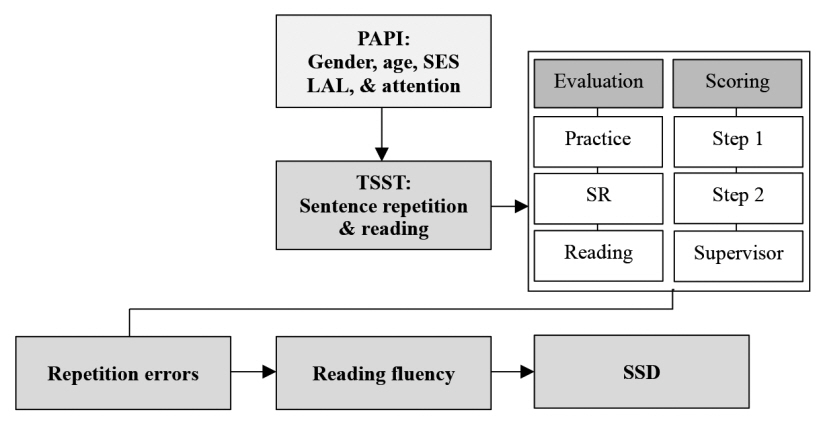
문장 산출 능력인 문장 따라말하기(Sentence Repetition Task) 과제는 읽기능력과의 관련성을 살펴보는 데 종종 사용되었다. 문장 따라말하기 능력은 음운, 어휘, 문법 및 구문 등의 종합적인 언어능력과 관련되며, 그중에서도 문법 및 구문지식의 역할이 큰 것으로 나타났다(Hwang, 2012; Park, Yoon, Han, & Yim, 2014; Polisenska, Chiat, & Roy, 2015). 또한 즉각적으로 문장을 듣고 따라말하는 과제이기 때문에 음운작업기억도 함께 요구된다(Alloway & Gathercole, 2005). 이번 연구에서는 여러 문장 따라말하기 과제 중에서 ‘세 문장 따라말하기 선별검사(TSST, Three-Sentence-Screening Test for Korean speech sound disorders)’를 이용하였다.
TSST는 말소리와 언어발달 선별평가를 위하여 개발되었다(Kim, 2016). TSST는 3개 문장, 18개의 어절, 64개의 자음을 포함하고 있다. 측정법은 ‘연습문항’->’세 문장 따라말하기’->’세 문장 읽기’의 순으로 컴퓨터를 이용하여 녹음하는 방식으로, 소요시간은 연습문항을 포함하여 3분 정도이다(Kim & Han, 2015) (Figure 1).
TSST를 통해 살펴본 이번 연구의 측정변수는 다음의 세 가지이다. 첫째, 모방오류어절지수는 따라 말하기에서 아동이 어절을 전체 혹은 부분적으로 생략하거나 다른 말로 대치하거나 순서를 바꾸어 말하는 등 언어적으로 모방에 실패한 어절의 수를 전체 어절 수로 나누어 측정하였다. 모방오류어절지수의 범위는 0-1점으로 점수가 높을수록 언어적 오류가 많은 것이다. 둘째, 읽기 유창성은 TSST 문장을 읽게 하여 대상자가 문장을 읽는 속도가 지나치게 늦거나 자연스럽지 않은지를 4점 척도(유창함[0점, Fluent]-약간 비유창함[1점, Somewhat]-매우 비유창함[2점, Rarely]-읽지 못함[3점, Not at all])로 측정하였다. 읽기 유창성은 정확성과 빠르기, 운율감을 전체적으로 평가하는 부분이 있기에 주관적인 평가로 진행되었다. 셋째, 말소리 조음평정치의 경우는 검사목표 18개 어절 발화 중 조음에서 오류를 보이는 어절 수를 측정하였다. 그리고 산출된 전체 점수 분포의 -1 SD를 기준으로 정상군과 의심군을 먼저 선정하고, 채점자의 판단에 의해 4점 척도(일반수준[0점, General]-약간 오류[1점, Slightly]-심화검사 권유[2점, Recommendation]-조음장애 의심[3점, Articulation disorder])로 말소리 집단을 구분하였다. 하지만 이번 연구에서는 원자료와는 다르게 심화검사 권유와 조음 장애 의심 두 집단을 ‘심화검사 및 조음장애 의심’ 하나의 집단으로 구분하였다. 그래서 결과적으로 3점 척도(일반수준[0점, General]-약간 오류[1점, Slightly]-심화검사 및 조음장애 의심[2점, Articulation disorder]를 적용하였다.
학업능력: 언어 및 문해능력
언어 및 문해능력(Language and literacy, LAL)은 한국아동패널에서 진행한 학업능력(Academic Skills) 검사의 일부로 총 14개 문항으로 구성되어 있다. 검사는 동일한 내용을 패널 대상자의 보호자와 교사 모두가 각각 응답하도록 하였다. 보호자용 응답은 패널 대상자의 보호자가 행동발달 질문지에 응답하는 것이었고, 교사용 질문지는 종단 연구 대상자들이 소속되어 있는 육아지원기관의 담임교사가 web 설문지를 통해 응답하게 하였다. 문항에 대한 점수화는 5점 척도(아직 하지 않음[1점, Not Yet], 하기 시작함[2점, Beginning], 어느 정도 해냄[3점, In Progress], 잘하는 편임[4점, Intermediate], 능숙함[5점, Proficient])’를 이용하여 측정하는 것으로 개별 문항 점수가 높을수록 언어 및 문해능력이 좋은 편이다(Lee, 2021).
주의집중력
유아행동평가척도(Child Behavior Checklist, CBCL 1.5-5)는 총 100문항으로 구성되어 있으며, 18개월부터 만 5세까지 유아들의 행동문제를 내재화 문제(정서적 반응성, 불안/우울, 신체증상, 위축)와 외현화 문제(주의집중 문제, 공격행동)로 나누어 측정한다(Oh & Kim, 2009). 한국아동패널 7차 패널 연구에 사용된 CBCL 1.5-5는 보호자가 대상 아동의 행동을 3점 척도(전혀 해당하지 않는다[0점, None]-가끔 그렇거나 그런 편이다[1점, A Few or Some]-자주 그런 일이 있거나 많이 그렇다[2점, Many or Nearly all])로 측정한 결과 중에서, 주의력 문제행동증후군 척도 5문항 총점 결과만을 이용하였다. 총점이 높을수록 주의력 문제가 심각하다고 해석할 수 있다.
연구절차
패널 기본 설문과 평가는 면접원이 가정 방문을 하여 지필식 설문 조사(Paper and Pencil Interviewing, PAPI)로 진행하였다. 그리고 TSST 선별검사는 면접원이 컴퓨터 프로그램을 이용하여 아동 발화를 녹음하는 방식으로, 검사 단계는 ‘연습, 따라말하기, 읽기’의 3가지 순서로 진행하였다.
TSST 검사 진행에 대해 구체적으로 살펴보면 다음과 같다. 우선, 훈련받은 면접원이 아동집에 방문하여 먼저 핀마이크를 아동에게 장착하여 주고, 아동과 따라말하기를 연습해 본 후에, 본 검사의 문장을 하나씩 제시하여 아동이 따라말하게 하고 녹음하였다. 이때 아동이 다른 말을 하거나 따라하지 못하면, 다시 들려주면서 그대로 따라 해보라고 격려한 후에 녹음을 진행하였다. 마지막으로 읽기 유창성 검사는 문장을 보여주고 아동 스스로 읽도록 지시하고 그 내용을 녹음하였다(Figure 2).
Comparing text comprehension ability on question types and groups.
LAL =Language and literacy; PAPI =Paper and pencil interviewing; SES =Socioeconomic status (Monthly household income, Maternal education level); SR=Sentence repetition; SSD=Speech sound disorder; TSST=Three-Sentence-Screening Test for Korean speech sound disorders.
그리고 TSST 검사의 채점은 2단계로 구분되었다. 채점의 1단계는 언어치료 실습 훈련을 받은 언어치료학과 4학년 학생 20명이 아동 발화를 발음 그대로 전사하고 언어와 조음 오류가 있는 어절의 수를 따로 구분하여 오류점수로 기록하였다. 언어적 오류점수는 언어적 오류가 있는 어절의 수로 오류가 전혀 없는 경우 0점이고 모든 어절에 오류가 있는 경우는 18점이다. 모방오류어절지수는 총 18개 어절 중 따라말하기에서 언어적 오류를 보인 어절 수의 비율(언어적 오류 어절 수/18)로 계산하였다. 그리고 조음평정치는 말소리에서 조음(articulation)에서만 오류를 보인 것을 구분하여 조음 오류가 전혀 없는 경우 0점이고 모든 어절에 조음 오류가 있는 경우는 18점이다.
2단계는 2년 이상의 말 언어진단 및 치료경력이 있는 언어치료사로 대학원에서 조음음운장애 수업을 수강한 평정자가 아동 발화를 듣고 읽기의 속도와 자연스러움을 ‘문장 읽기 유창성’ 정도로 하여 4점 척도(유창함0-약간비유창함1-매우비유창함2-읽지 못함3)로 측정하였다. 그리고 말소리(조음) 정확도 정도는 문장을 읽는 말소리가 정확한지에 따라 4점 척도(일반적임0-약간 오류가 있으나 일반적임1-심화검사 권유2-조음음운장애 의심3)로 측정하였다.
2단계 채점에 있어 슈퍼바이저가 읽기 유창성과 조음평정치 채점의 10%를 점검하여 90% 이상의 일치도를 보이는 경우 산출된 점수를 반영하였고, 일치도가 90% 미만인 경우는 다른 채점자가 100% 재점검하여 다시 검토하여 점수를 산출하였다. 말소리 조음 정확도 측정에 있어, 이번 연구에서는 원자료와는 다르게 심화검사 권유와 조음장애 의심 두 집단을 ‘심화검사 및 조음장애 의심’ 하나의 집단으로 구분하였다. 그래서 결과적으로 3점 척도(일반수준0-약간 오류1-심화검사 및 조음장애 의심2)를 적용하였다.
통계분석
수집된 자료는 IBM SPSS 25.0 프로그램을 사용하여 분석하였다. 먼저 각 측정 변수들에 대한 평균과 표준편차를 제시하고, 명목 변수에 대해서는 교차분석 또는 분산분석을 실시하였다. 이후 읽기 유창성 집단에 대한 의사결정나무 분석(Decision Tree Analysis, DTA)을 실시하였다. 22개 예측 변수를 (Chi square Automatic Interaction Detector, CHAID) 알고리즘 하에 DTA를 적용하였다. CHAID는 χ2 검정 또는 F-검정을 이용하여 분리(split)와 병합(merge)을 반복하면서 부모마디에서 자식마디를 2개 이상 다지분리(multiway split)를 수행하는 알고리즘이다(Lee, 2021). 이번 연구에서는 DTA 과적합(overfitting)을 막기위해 최소케이스 수는 부모 노드는 100, 자식 노드는 50으로 제한을 두었다.
연구결과
기술분석: 유창성 수준 및 관련 변수 특성
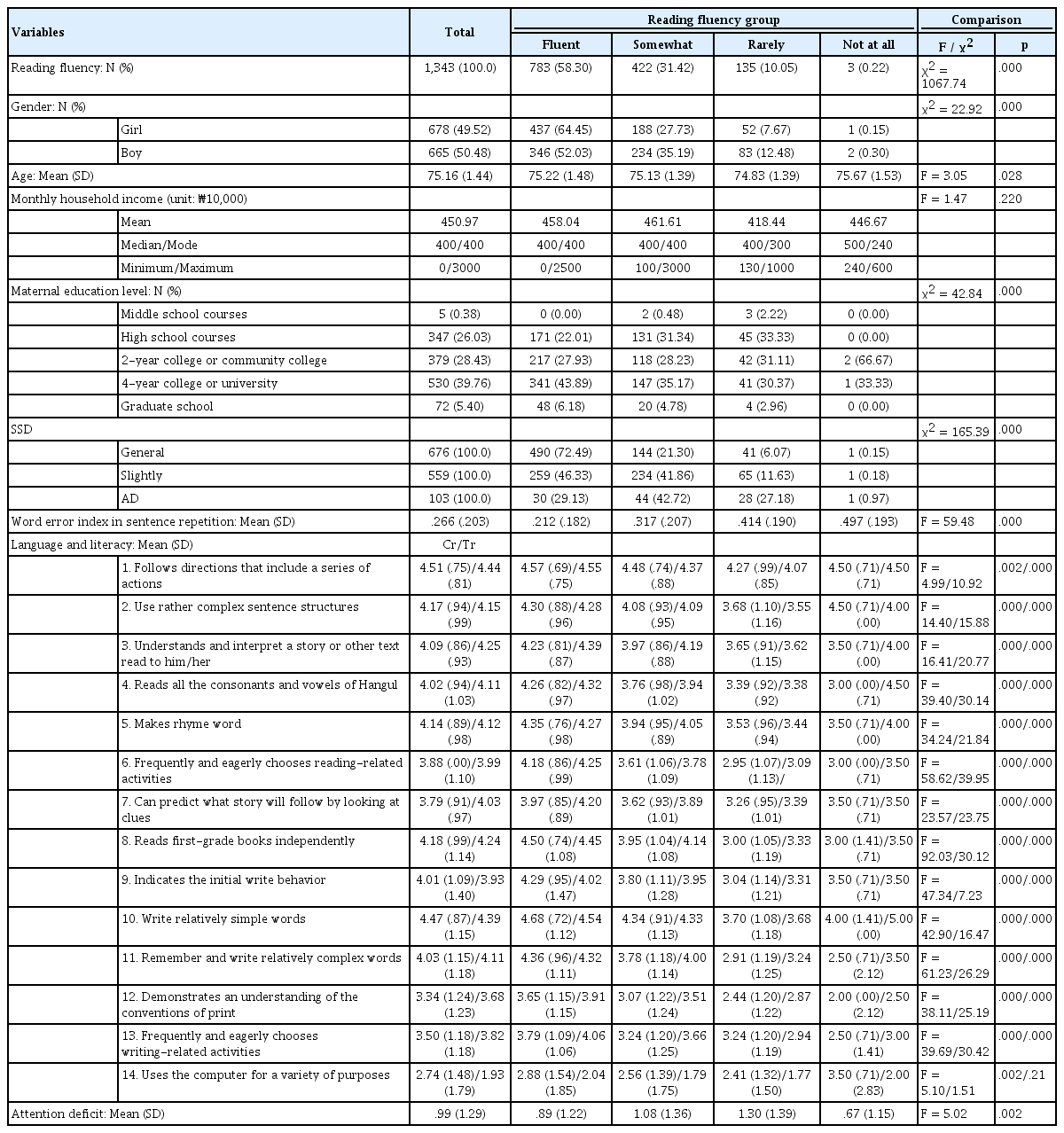
초등학교 입학을 앞둔 학령 전 6세 아동 패널 1,343명의 읽기 유창성 수준을 ‘유창함, 약간 비유창함, 매우 비유창함, 읽지 못함’과 같이 구분하였다. 그리고 ‘아동 성별과 연령, 가정 내 연 수입, 양육자 엄마의 학력, 아동의 언어 및 문해능력 14개 문항, 조음평정치, 모방오류어절지수, 주의력’ 등 21개 측정값이 아동의 읽기 유창성 수준에 유의미한 영향을 미치는지를 살펴보았다. 패널의 읽기 유창성 수준을 ‘유창함, 약간 비유창함, 매우 비유창함, 읽지 못함’과 같이 구분하였을 때, 783명(58.30%)은 유창한 수준이었으며, 422명(31.42%)은 약간 비유창하였고, 135명(10.05%)은 매우 비유창하였고, 3명(0.22%)은 전혀 읽지 못하였다. 즉, 6세 아동 전체 중 89.72%가 유창하게 읽거나 약간 비유창한 수준으로 읽기를 할 수 있음을 확인하였다(Table 1).
Characteristics of the study panel (N= 1,343)
6세 패널 대상자의 읽기 유창성과 관련된 일반(성별, 월령), SES(월 평균 가구 소득, 엄마의 학력), 말소리 및 인지언어 측정변수(조음평정치, 모방오류어절지수), 학업능력과 인지(언어 및 문해능력, 주의력결핍) 특성에 대한 개별 8가지 변수에 대해 살펴본 결과는 다음과 같다.
첫째, 참여 대상자들의 성별 비율을 살펴보면 여아동은 678명(49.52%), 남아동은 665명(50.48%)으로, 대상자 성별 간의 유의미한 차이는 없었다(χ2(1, 1,343) =.13, p=.72). 하지만 성별에 따라 읽기 유창성 수준은 유의미한 차이를 보였다(χ2(3, 1,339) = 22.92, p< .001). 읽기가 유창하거나 약간 비유창한 대상자가 여아동의 경우는 92.18%에 달하였지만 남아동의 경우는 87.22%였다. 둘째, 대상자들은 모두 6세 아동으로 원령으로 살펴보았을 때는 평균 75개월(표준편차 =1.44)이었다. 읽기 유창성 집단에 따른 월령을 살펴보았을 때, 읽기가 유창한 대상자들의 월령은 75.22개월(표준편차 =1.48), 약간 비유창한 대상자의 월령은 75.13개월(표준편차 =1.39), 매우 비유창한 대상자의 월령은 74.83(표준편차 =1.39), 전혀 읽지 못하는 대상자의 월령은 75.67(표준편차 =1.53)개월이었다. 즉, 전혀 읽기 못하는 대상자를 제외하고는, 읽기 유창성이 높을수록 유의미하게 월령이 높은 것으로 나타났다(F(3, 1,339) = 3.05, p< .05).
셋째, 2014년 패널의 월 평균 가구 소득 중앙값과 최빈값은 400만원이었고, 읽기 유창성 수준 집단별로 월 평균 소득은 유의미한 차이가 없었다. 넷째, 엄마의 최종학력과 읽기 유창성 수준 집단 간의 관계에 있어 읽기가 유창한 패널 대상자는 엄마가 2년제 전문대학 이상의 학력을 가진 경우가 유의미하게 많았다(χ2(12, 1,333) = 42.84,p< .001). 다섯째, 읽기 유창성과 조음평정치 집단 간 교차분석 결과 조음의 문제가 있는 아동은 읽기 유창성이 낮은 대상자인 경우 가 유의미하게 많았다(χ2(12, 1,333) = 165.39, p<.001).
여섯째, 읽기가 비유창한 집단일수록 언어적 모방오류어절지수는 유의미하게 높은 것으로 나타났다(F(3, 1,339) = 59.48, p< .001). 즉, 문장 따라말하기에서 읽기가 비유창한 집단은 어절을 전체 혹은 부분적으로 생략하거나 다른 말로 대치하거나 순서를 바꾸어 말하는 등 언어적으로 문장을 모방하는 것에 실패한 어절의 수가 유창하게 읽는 아동에 비하여 유의미하게 높은 것을 확인하였다.
일곱째, 14가지 언어 및 문해능력 변수 중 양육자 엄마 또는 담임 교사가 평가한 14번(컴퓨터를 통해 다양한 활동을 한다) 문항을 제외한 13개 언어 및 문해능력 변수는 모두 읽기가 유창한 집단일수록 더 유의미하게 높은 능력을 보이는 것으로 나타났다. 언어 및 문해능력 14번은 아동이 컴퓨터를 통해 다양한 활동을 하는지를 평가한 문항으로 양육자 엄마의 평가에 따르면 전혀 읽지 못하는 대상자들이 컴퓨터를 활용하여 유의미하게 가장 많은 활동을 하고 다음으로는 읽기를 유창하게 하는 대상자들이 유의미한 활동을 한다고 응답하였다. 하지만 동일한 문항에 대해 담임교사는 읽기 유창성 집단에 따라 컴퓨터를 통한 활동에 유의미한 차이가 없는 것으로 평가하였다. 여덟째, 읽기가 유창한 집단은 읽기가 약간 비유창하거나 매우 비유창한 집단보다 주의력이 유의미하게 높은 것으로 나타났다(F(3, 1,339) = 5.02, p< .01).
의사결정나무분석(DTA)
DTA 결과
일반 6세 아동의 읽기 유창성을 예측하는 변수 간의 관계에 대한 DTA 모델을 Figure 2에 제시하였다. DTA의 최종모델은 3층 깊이(Layers)의 14개 마디(Node)였다. 다양한 측정변수 중 읽기 유창성에 가장 유의미하게 영향을 미치는 변수는 엄마가 판단하였을 때 아동이 혼자서 간단한 책을 스스로 읽을 수 있는지(언어 및 문해능력 8번)를 확인한 수준 측정값이었다. 그리고 이외 읽기 유창성 집단을 구분하는데 있어 유의미한 영향을 미친 변수는 문장 따라말하기 과제를 통해 살펴본 언어적 모방오류어절지수, 아동 월령, 말소리 조음평정치 수준, 한글의 모든 자음과 모음을 쉽고 빠르게 말할 수 있는 정도(언어 및 문해능력 4번)와 말소리 중 음조가 비슷한 단어의 운율을 맞추어 말할 수 있는지(언어 및 문해능력 5번)와, 성별 이렇게 7가지 변수였다(Figure 3).

Decision tree for predicting reading fluency classes.
AD=Articulation disorders; Reads independently: Cr=Reads simple books independently: Caregiver response; EQNA: Tr=Easily and quickly names all consonants and vowels letters of the Korean alphabet: Teacher response; PRW: Tr=Produces rhyming words: Teacher response; Slightly=A little bit of an articulation error; Sr: Ie=Sentence repetition: Imitation error; SSD=Speech sound disorder; Language and literacy=Not Yet - Beginning - In Progress - Intermediate - Proficient; Speech sound disorder=AD - Slightly – General.
DTA 모델에 의한 읽기 유창성 위험 수준 분리규칙
읽기 유창성 관련 변수 7가지(혼자서 간단한 책을 스스로 읽는 정도, 월령, 성별, 모방오류어절지수, 말소리 조음평정치 수준, 한글 자음과 모음을 쉽고 빠르게 말하기, 단어의 운율을 맞추어 말하기)가 적용된 CHAID 알고리즘 분석결과는 Figure 3과 Table 2에 제시하였다. 그리고 최적의 CHAID 모델은 G1부터 G6까지 총 6개의 읽기 유창성 위험 수준 분리 규칙을 제시하였다(Table 2). 이러한 규칙은 읽기 유창성 지수(Fluency index, FI)를 이용하여 집단을 구분한 것으로 FI 계산식과 값은 Table 2에 제시하였다. FI는 읽기를 비유창하게 하는 대상자들이 전체 대상자 중 어느 정도 비율로 포함되어 있는지를 지수로 표현한 것으로 그 값이 클수록 읽기가 비유창한 편이다. 그리고 FI 값에 의해 구분한 규칙 6가지 중, 규칙 G1이 가장 읽기가 비유창한 집단이고 규칙 G6이 가장 읽기를 유창하게 하는 집단이다.

Classification rules for the risk group of the decision tree model
이러한 읽기 유창성 위험 수준 분리규칙을 간략하게 소개하면 다음과 같다.
• Rule G1: FI가 50보다 큰 6번 마디(Node 6)는 가장 FI 값이 크며, 읽기가 비유창한 대상자들이 가장 많이 마디에 속해 있다. 6번 마디는 엄마가 평가하였을 때 독립적으로 읽는 것을 하기 시작하거나 아직 읽지 못하는 대상자들이면서, 또한 모방오류어절지수가 .28보다 큰 대상자들이다.
• Rule G2: FI가 20-40에 속하는 마디는 총 4개로 17번, 5번, 7번, 14번 마디(Node 17, Node 5, Node 7, Node 14)이다. 규칙 G1 다음으로 읽기가 비유창한 대상자들이 많이 속한 마디들이 포함되어 있다. 17번 마디는 독립적으로 읽는 것을 어느 정도 해내기 시작하고 있거나 하기 시작하는 대상자이면서 모방오류어절지수가 .35보다 크고, 운율이 비슷한 단어를 어느 정도 말하기 시작하는 대상자이다. 5번 마디는 독립적으로 읽는 것을 하기 시작하는 단계이거나 전혀 읽지 못하는 대상자이면서 모방오류어절지수가 .28보다 작은 대상자이다. 7번 마디는 독립적으로 읽는 것을 하기 시작하고 또한 어느 정도 하는 대상자이면서 월령이 74개월보다 적은 대상자이다. 14번 마디는 독립적으로 읽는 것을 하기 시작하고 또한 어느 정도 하는 대상자이면서 월령이 74개월보다 많으며 말소리 조음 문제가 약간 있거나 조음장애로 의심되는 대상이다.
• Rule G3: FI가 11-20에 속하는 마디는 총 3개로 18번, 15번, 23번 마디(Node 18, Node 15, Node 23)이다. 규칙 G2 다음으로 읽기가 비유창한 대상자들이 있는 마디들이 포함되어 있다. 18번 마디는 독립적으로 읽는 것을 어느 정도 해내기 시작하고 있거나 잘하는 대상자이면서 모방오류어절지수가 .35보다 크고, 운율이 비슷한 단어를 어느 정도 말하기 시작하는 대상자이다. 15번 마디는 독립적으로 읽는 것을 어느 정도 해내기 시작하고 있거나 잘하는 대상자이면서 모방오류어절지수가 .35 이하이며 쉽고 빠르게 한글의 자음과 모음을 말하는 것을 어느 정도 해내는 대상자이다. 23번 마디는 독립적으로 읽는 것을 잘 하는 편이지만 말소리 조음 문제가 약간 있거나 조음장애로 의심되는 남아동이다.
• Rule G4: FI가 6-10에 속하는 마디는 총 4개로 13번, 22번, 21번, 16번 마디(Node 13, Node 22, Node 21, Node 16)이다. 규칙 G3 다음으로 읽기가 비유창한 대상자들이 있는 마디들이 포함되어 있다. 13번 마디는 독립적으로 읽는 것을 시작하거나 어느 정도 해내기 시작하고 있으며 월령이 74개월보다 많고 말소리 조음문제가 없는 대상자들이다. 22번 마디는 독립적으로 읽는 것이 능숙한 대상자이면서 말소리 조음장애가 약간 있거나 조음장애가 있는 여아동이다. 21번 마디는 독립적으로 읽는 것이 능숙하고 말소리 조음의 문제가 없지만, 모방오류어절지수가 .17 보다 높은 대상자이다. 16번 마디는 독립적으로 읽는 것을 어느 정도 해내거나 잘하는 편이며, 모방오류어절지수가 .35 이하이고, 쉽고 빠르게 한글의 자음과 모음을 능숙하게 말하는 대상자이다.
• Rule G5: FI가 1-5로, 여기에 속하는 마디는 20번 마디(Node 20) 하나이다. 규칙 G4 다음으로 읽기가 비유창한 대상자들이 있는 마디들이 포함되어 있다. 20번 마디는 독립적으로 읽는 것을 능숙하게 하고, 말소리 조음 문제가 없으며, 모방오류어절지수가 .17 이하인 대상자이다.
• Rule G6: FI가 1보다 작은 마디는 19번 마디(Node 19) 하나로, 읽기가 유창한 대상자들만 포함되어 있는 마디이다. 19번 마디는 독립적으로 읽는 것을 능숙하게 하는 대상자들이며, 말소리 조음 문제가 없으며 모방오류어절지수가 .0으로 모방오류가 나타나지 않는 대상자이다.
모형평가
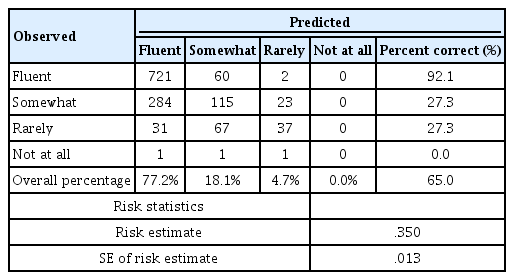
의사결정나무를 이용하여 읽기 유창성 집단 예측 판별 정확도 평가는 분류행렬 위험도표를 이용하였다(Table 3). 목표범주로 분류된 관찰치는 원래의 목표범주와 일치할 수도 있고 그렇지 않을 수도 있다. 일치도가 높을수록 모형구축이 성공적이었다고 할 수 있다. 그리고 분류행렬 위험도표는 실제 목표변수의 범주와 분류된 것을 하나의 표로 제시하여 모형구축의 성패를 가시적으로 표현해주는 도표이다. 이때 제시되는 예측위험(risk estimate)은 도표 대각에 존재하는 원래 범주가 제대로 분류된 것 이외의 비대각(off-diagonal)에 존재하는 값들을 의미한다. 이러한 수치는 작을수록 더 선호되는 것으로 구축된 모형이 하나의 관찰치를 오분류(misclassification)할 확률이다. 다양한 변수를 이용한 데이터 마이닝 연구에서 모형 설명치가 60% 이상인 경우는 모형의 설명력이 어느 정도(Moderate) 있는 것으로 평가하고 있다(Li et al., 2019). 이번 DTA 모형은 관찰치를 정확하게 분류할 확률이 65%로 평균 이상의 수준이었으며, 오분류 확률은 35%이었다. 그리고 위험추정치의 표준오차는 위험추정치가 이항분포의 성공확률을 나타내는 모수로 간주될 경우 추정치에 계산되는 표준오차 값이라고 할 수 있다(Table 3).
Classification table and risk estimate
논의 및 결론
일반적으로 읽기를 배우는 시기는 6세 전· 후이다(Chang, 2015). 우리나라의 경우 대부분의 아동은 초등학교에 입학하기 전에 한글 읽기가 가능하므로, 초등학교 저학년 시기에 한글을 읽는 수준에서 유창하게 읽는 수준으로의 읽기발달 변화가 빠르게 이루어진다. 그리고 이러한 일반적 읽기발달 경향을 따라가지 못하는 학생들은 학교에서 전반적인 학습문제에 봉착하게 된다(Jung, 2015). 그러므로 전문가들은 조기에 읽기발달에 문제가 있는 대상자들을 선별하여 추가적 읽기 중재가 진행되어야 한다고 보고 있다. 이에 본 연구에서는 초등학교 입학 예정인 6세 학령전 아동들의 한글 읽기 유창성 수준과 읽기관련 개별변수들의 관계를 우선 살펴보고, 의사결정나무(DTA) 모델을 적용하여 읽기관련 개별 변수들이 읽기 유창성 수준을 예측하여 읽기 문제 조기 선별이 가능한지에 대해 분석하였다.
DTA 모델에 변수를 적용하기 전에 6세 패널 대상자의 읽기 유창성과 관련된 일반(성별, 월령), SES(월 평균 가구 소득, 엄마의 학력), 말소리 및 인지언어 측정변수(조음평정치, 모방오류어절지수), 학업능력과 인지(언어 및 문해능력, 주의력결핍) 특성에 대한 개별변수에 대해 살펴본 결과, 월 평균 가구 소득 변수를 제외한 측정변수가 읽기 유창성 집단에 따라 유의미한 차이를 보이는 것으로 나타났다. 그리고 읽기 유창성 수준을 판별하는 DTA 모델에는 총 21가지 변수(아동 성별과 연령, 가정 내 연 수입, 양육자 엄마의 학력, 아동의 언어 및 문해능력 14문항, 조음평정치, 모방오류어절지수, 주의력)를 분석에 적용되었을 때는 읽기 유창성에 유의미한 영향을 미치는 변수는 7가지 변수(엄마가 평가하였을 때 아동이 혼자서 간단한 책을 스스로 읽는 정도, 월령, 성별, 모방오류어절지수, 말소리 조음평정치 수준, 담임교사가 평가하였을 때 한글 자음과 모음을 쉽고 빠르게 말하는 수준, 담임교사가 평가하였을 때 단어의 운율을 맞추어 말하는 정도)인 것으로 나타났다. 읽기 유창성에 유의미한 영향을 미치는 것으로 나타난 7가지 변수는 DTA CHAID 분석에 의해서 분리(split)와 병합(merge)을 반복하면서 다지분리(multiway split)를 수행하는 알고리즘이다. 그러므로 집단 분류조건에 따라서 동일한 변수가 다르게 영향을 미치게 되는 조건함수를 가지게 된다. 이러한 조건함수를 바탕으로 주요 연구결과들을 중심으로 논의하면 다음과 같다.
첫째, 아동 개인 요인 중에서는 ‘성별과 월령’, 그리고 가정환경 SES 변인 중에서는 ‘엄마의 학력수준’, 말소리 및 언어인지 요인 중에서는 ‘말소리 조음평정치 수준과 모방오류어절지수’, 언어 및 문해능력에서는 담임교사가 평가한 ‘14번 문항(컴퓨터를 통해 다양한 활동을 한다)을 제외한 모든 문항’, 인지적 측면에서는 ‘주의력 결핍 정도’ 변수 등이 읽기 유창성과 유의미한 관계가 있는 것으로 나타났다. 이러한 연구결과는 선행연구들과 일치하는 내용이었다(Fox & Maggioni, 2016).
둘째, DTA 분석 결과 읽기 유창성 예측 모델에서 가장 큰 영향을 미치는 변수는 아동이 혼자서 간단한 책을 스스로 읽을 수 있는지(언어 및 문해능력 8번) 엄마가 판단한 내용에서였다. 학령 전 유치원에서 담임교사가 바라본 아동의 문해능력은 매우 제한적일 수 있다. 하지만 양육자 엄마는 자녀의 다양한 활동을 관찰할 수 있고 아동의 문해학습을 주도하고 있기 때문에, 엄마가 평가한 아동의 독립적 읽기 변수가 읽기 유창성의 가장 예민한 예측인자로 작용한 것으로 보인다. 독립적 읽기에 있어 능숙한 대상자들의 74.1%가 읽기가 유창한 것으로 나타났다. 하지만 혼자서 책을 읽는다는 것은 아동이 문자를 읽을 수 있다는 것을 의미하므로 이것은 아동의 읽기 유창성에 가장 큰 영향을 미치는 변수로 작용한 것으로 보인다.
셋째, 읽기 유창성 집단 분류에 다음으로 영향을 미치는 변수는 모방오류어절지수였다. 좀 더 구체적으로 살펴보면, 엄마가 평가하였을 때 혼자서 책을 스스로 읽을 수 없는 대상자들은 모방오류어절지수가 .28을 기준으로 하였을 때, .28보다 오류율이 많은 아동이 읽기 유창성이 낮은 집단이 될 가능성이 유의수준 .01에서 더 많았다. 그리고 혼자서 책을 스스로 어느 정도 읽거나 잘 읽는 아동은 모방오류어절지수 .35를 기준으로 하였을 때, .35보다 오류율이 많은 아동이 읽기 유창성이 낮은 집단이 될 가능성이 유의수준 .01에서 더 많았다. 혼자서 책을 스스로 읽는 것이 능숙한 아동 중 조음 오류가 보이지 않는 대상자들은 모방오류어절지수 .17를 기준으로 하였을 때, .17보다 오류율이 많은 아동은 읽기 유창성이 낮은 집단이 될 가능성이 유의수준 .001에서 더 많았다. 즉, 읽기 유창성 수준을 구분할 때, 혼자서 책을 스스로 읽는 수준의 능숙도에 따라서 읽기 유창성 집단을 구분하는 모방오류어절지수의 적용 점수가 달라졌다. 문장 따라말하기 과제로 측정한 모방오류어절지수는 언어능력과 기억이 모두 작용하는 측정치이다. 그러므로 모방오류어절지수가 읽기 유창성에 영향을 미치는 주요 변수로 작용한 것은 언어와 기억능력 개인차가 읽기 유창성에 영향을 미치고 있다는 것을 제시하는 결과로 해석할 수 있다. 그리고 이러한 연구결과는 구어의 어려움이 읽기발달에 부정적인 영향을 미치고 있다고 제시한 Yoon과 Park (2022)의 연구결과와도 일치하는 내용이다.
넷째, 읽기 유창성 집단 분류에 다음으로 영향을 미치는 변수는 연령 변수였다. 엄마가 평가하였을 때 혼자서 책을 스스로 읽기 시작하거나 어느 정도 읽기가 가능한 아동은 74개월을 기준으로, 74개월(6세 2개월) 이하의 아동은 읽기 유창성이 낮은 집단이 될 가능성이 유의수준 .01에서 더 많았다. 그러므로 초등학교 입학할 때 스스로 읽기를 시작하거나 어느 정도 하는 아동에게는 월령이 읽기 유창성에 유의미한 영향을 미치는 변수임을 확인할 수 있었다. 하지만 읽기를 전혀 못하거나 잘하고 또는 유창하게 읽는 대상자들에게는 월령이 유의미한 읽기 유창성 변수로 작용하지는 않았다. 읽기를 배우기 시작하는 연령은 6세 전후이다. 일반적으로는 6세 이전에 자모지식을 배우고 단어 읽기를 배울 수는 있지만 그 진전이 매우 느리므로 읽기를 배우는 적합한 연령이 있는 것으로 알려져 있다(Chall, 1996; Chang, 2015). 이러한 선행 연구결과를 역으로 생각하면, 6세를 기준으로 읽기 학습 진전이 매우 더디다면 이것은 읽기 문제가 있음을 의미하는 것이다.
다섯째, 읽기 유창성 집단 분류에 다음으로 영향을 미치는 변수는 말소리 조음평정치 결과(조음의 문제가 전혀 없는 대상자, 약간이라도 조음 문제가 있는 대상자) 변수였다. 좀 더 구체적으로 살펴보면, 엄마가 평가하였을 때 혼자서 책을 스스로 능숙하게 읽는 아동은 조음 문제가 약간이라도 있다면 읽기 유창성이 낮은 집단이 될 가능성이 유의수준 .001에서 더 많았다. 그리고 혼자서 책을 스스로 읽기 시작하거나 어느 정도 읽게 된 아동 중 월령이 74개월 보다 많은 대상자들은 조음 문제가 약간이라도 있다면 읽기 유창성이 낮은 집단이 될 가능성이 유의수준 .01에서 더 많았다. 즉, 혼자서 책을 읽는 것의 능숙도에 따라서 조음 문제가 읽기 유창성에 영향을 미치는 것에 차이를 보일 수 있었다. Lee 등(2018) 연구결과에 따르면 조음장애가 있는 아동은 일반적으로 음운인식능력과 언어능력이 일반 아동에 비하여 낮은 것으로 나타났다. 그러므로 조음 문제는 읽기발달에 부정적인 영향을 미치는 것으로 해석할 수 있다(Lee, 2023). 그리고 이번 연구를 통해서 말소리 조음의 문제는 특히 읽기 유창성에 영향을 미치는 변수임을 확인할 수 있었다.
여섯째, 읽기 유창성 집단 분류에 다음으로 영향을 미치는 변수는 한글의 모든 자음과 모음을 쉽고 빠르게 말할 수 있는 정도(잘 하는 편임, 능숙함)와 음조가 비슷한 단어(운율 맞추기)를 만들 수 있는 정도(어느 정도 가능함, 잘 하는 편임) 두 가지 변수였다. 엄마가 평가하였을 때 혼자서 책을 스스로 어느 정도 읽거나 또는 잘 읽는 아동 중, 모방오류어절지수가 .35 이하의 대상자가 한글의 모든 자음과 모음을 쉽고 빠르게 말할 수 있는 정도가 능숙하지 못하다면 읽기 유창성이 낮은 집단이 될 가능성이 유의수준 .001에서 더 많았다. 그리고 모방오류어절지수가 .35보다 높은 대상자가 음조가 비슷한 단어(운율 맞추기)를 만드는 것을 어느 정도도 해내지 못하는 대상자들은 읽기 유창성이 낮은 집단이 될 가능성이 유의수준 .01에서 더 많았다. 그러므로 혼자서 책을 스스로 어느 정도 읽거나 잘 읽는 아동은 모방오류어절지수가 .35 이하로 낮다면 한글 자음과 모음을 빠르게 말할 수 있어야 하고 모방오류어절지수가 .35보다 높다면 음조가 비슷한 단어(운율 맞추기)를 만들 수 있어야 읽기가 유창한 집단이 될 가능성이 높은 것으로 나타났다. Jung(2015)의 연구에서 초등학교 1학년 학생들의 자모 지식은 읽기 유창성에 유의미한 영향을 미치는 변수인 것으로 나타났다. 이번 연구에서는 초등학교 입학을 앞둔 아동으로 Jung (2015) 연구 대상자와 비슷하게 읽기를 배우기 시작하는 단계의 대상자들이다. 그러므로 읽기를 배우는 초기 단계 아동들의 자모지식의 정도는 읽기에 유의미한 영향을 미치는 것으로 보인다(Yang et al., 2017). 특히 스스로 읽기가 어느 정도 가능한 대상자들에게 유의미한 영향을 미치는 변수인 것으로 나타났다. 그리고 음운인식은 매우 포괄적인 말소리에 대한 구조화 규칙에 대한 이해를 의미하는 것으로 말소리의 운율을 인식하거나 자소와 음소를 대응하는 것을 모두 의미한다. 즉, 자음과 모음의 소리를 쉽게 말할 수 있거나 음조가 비슷한 단어를 만들 수 있는 능력 모두를 포함한다. 그러므로 음운인식능력 정도가 읽기 유창성을 구분한다는 것은 읽기 개별 변수 중 단계 2에 속하는 음운인식이 읽기에 유의미한 영향을 미치는 변수로 작용하였음을 확인하여 주는 것으로 해석할 수 있다.
일곱째, 최적의 DTA CHAID 모델에 의한 읽기 유창성 위험 수준 분리규칙은 G1부터 G6까지 총 6개의 읽기 유창성 위험 수준 분리 규칙을 제시하였다. 규칙 G1이 가장 읽기가 비유창한 집단이고 규칙 G6가 가장 읽기를 유창하게 하는 집단이다. 이러한 읽기 유창성 위험 수준 분리규칙은 언어재활사 또는 관련 임사가들이 읽기 유창성 문제 대상자를 예측하는데 있어 매우 간편하고 쉽게 적용할 수 있는 진단 기준이 될 수 있다.
이상의 연구결과를 통해, 본 연구에서 시사하는 바는 다음과 같다.
첫째, 6세 학령전 아동의 읽기와 관련된 변수를 이용하여 DTA 분석 결과, 읽기 유창성 집단을 구분할 수 있는 매우 쉽게 적용 가능한 예측모델이 가능하였다. 이러한 예측모델에는 7가지 변수(엄마가 평가하였을 때 아동이 혼자서 간단한 책을 스스로 읽는 정도, 월령, 성별, 모방오류어절지수, 말소리 조음평정치 수준, 담임교사가 평가하였을 때 한글 자음과 모음을 쉽고 빠르게 말하는 수준, 담임교사가 평가하였을 때 단어의 운율을 맞추어 말하는 정도)가 포함되었으며, 모든 변수가 쉽게 측정 가능하여 모델을 적용하는 데 용이하였다. 둘째, 읽기 유창성은 읽기가 이해로 진행하는 중간 단계로 해석된다. 그러므로 이번 DTA 모델은 단순히 한글을 읽는 정도에 대한 평가가 아니라 읽고 이해하는 과정으로의 발달을 예측할 수 있는 읽기발달 모델로서의 의미가 있다. 이번 읽기 유창성 DTA 모델은 초등학교 입학 예정 대상자들의 읽기 유창성을 구분하여 읽기지도가 추가적으로 필요한 대상자를 선별하는 모델로서 적용할 수 있을 것이다. 셋째, 읽기 유창성에는 이미 선행연구로 알려져 있는 아동 개별 및 환경요인인 엄마의 학력과 문해 환경, 성별과 연령, 자음과 모음 낱 글자에 대한 읽기와 음운인식 이외에 ‘말소리 조음능력과 모방오류어절지수’가 포함됨을 알 수 있었다. 이러한 말소리 측정변수는 언어재활사에게는 익숙한 측정 및 진단영역이다. 그러므로 읽기를 교수하고 읽기진단 모델을 구성하는 데 있어 언어재활사의 말소리와 언어지식 역할이 매우 중요함을 이번 연구를 통해 알 수 있었다. 넷째, DTA CHAID 모델에 의한 읽기 유창성 위험 수준 분리규칙은, 읽기진단 및 교수와 관련된 언어재활사 및 임상가들이 좀 더 쉽고 빠르게 읽기 유창성을 예측하여, 읽기 중재 대상자 선정에 유용한 모델을 제시하였다.
다음으로 연구결과를 토대로 본 연구가 갖는 제한점을 밝히며 후속연구에 대한 제언을 제시하면 다음과 같다. 본 연구는 패널데이터를 이용하여 분석한 연구이다. 그러므로 6세 말소리장애 집단을 구분하는데 있어 여러 평가자가 평정한 데이터에 대한 신뢰도를 제시할 수 없었음에 아쉬움이 있다. 그리고 읽기 유창성은 일반적으로 읽기의 정확성, 자동성, 운율감 등의 요소로 구분하고 있다(Kuhn et al., 2010). 이번 연구에서 읽기 유창성은 평가자가 녹음된 파일을 들었을 때 문장을 읽는 속도가 지나치게 늦거나 자연스럽지 않은지 즉, 자동성과 운율감 측면에서 주로 살펴보고 읽기 유창성 집단을 구분하였다. 물론 훈련된 언어재활사들이 평가를 진행하였지만 그 기준이 명확하게 제시되지는 않았다. 그리고 따라말하기 과제를 적용한 이후에 동일한 문장을 읽기 평가한 것에는 학습효과가 작용하였을 수도 있다. 이러한 부분이 이후 연구에서는 보완되기를 바라며 좀 더 세부적인 읽기 유창성 평가 기준을 제시할 수 있었다면 하는 아쉬움이 있다. 그러므로 이후 연구에서는 읽기 유창성을 평가하는 좀 더 세부적인 평가안이 제시되어야 할 것이다. 이번 연구에 적용된 변수 이외에 읽기 유창성에 영향을 미치는 요인에는 ‘아동의 읽기에 대한 동기와 관심, 어휘능력, 선행지식, 책을 읽어주는 가정 내 환경, 시지각능력, 기억력’ 등도 포함된다(Afflerbach, Pearson, & Paris, 2008). 그리고 이러한 변수들은 개인이 처한 환경에 따라 다르게 영향을 미치는 것으로 고정적인 변수로 작용하지는 않는다. 그러므로 이후 연구에서는 다각적 변수관계를 통해 읽기 문제를 해석해 보아야 할 것이다. 또한 전통적인 방식에 의하면 읽기는 언어와 깊은 관련이 있고, 해독능력을 바탕으로 이해능력을 측정하는 것으로 해석한다. 하지만 현재 읽기는 다양한 언어적 그리고 비언어적 상징체계를 포함하는 것으로 확장하고 있다. 이제 초등학생들은 미디어를 통해 텍스트를 읽으며 그림과 동영상을 이용한 상징해석능력이 읽기에 있어 중요하다(Flood, Heath, & Lapp, 2008; Loughlin, 2013). 그러므로 확장된 읽기의 개념을 적용한 연구가 진행되어야 할 것이다.