2-5세 일반 아동의 어휘 발달: 체언
Substantives in the Vocabulary of Typically Developing Young Children
Article information
Abstract
배경 및 목적:
이 연구의 목적은 학령 전기 일반 아동의 자발화에 나타난 체언의 유형 수와 빈도 수를 살펴보고 품사별로 고빈도 어휘 목록을 제시하는 것이다.
방법:
나사렛 말뭉치 2, 3, 4, 5세 아동 각각 20명씩 총 80명의 발화에서 아동별로 300-400 발화를 선정하여 65,783 어절에 대해 체언의 유형 수와 사용 빈도를 계량화하고 고빈도 어휘를 제시하였다.
결과:
체언의 총 유형수 2,050개로 전체 품사의 유형 수 중 43.8%, 사용 빈도는 26,932회로 전체 사용 빈도 중 25.6%를 차지하였다. 체언 내 품사별 유형 수 비율은 ‘보통명사>고유명사>의존명사>대명사>수사’의 순서이고 사용 빈도 비율은 ‘보통명사>대명사>의존명사>고유명사>수사로 나타났다. 연령에 따른 체언 발달에서 2세는 보통 명사, 의존 명사, 대명사, 수사의 유형 수 및 사용 빈도에서 다른 연령 집단과 뚜렷한 차이를 보였다. 고빈도 보통 명사 60개가 누적 빈도 50.5%, 고빈도 의존 명사 10개가 누적 빈도 92.0%, 고빈도 대명사 10개가 누적 빈도 91.6%, 17개의 수사가 누적 빈도 90.4%를 보였다.
논의 및 결론:
체언의 유형 수와 사용 빈도의 증가에서 2-3세가 중요한 시기였고 고빈도 어휘 분석 결과 이 시기의 아동은 대명사, 의존 명사, 수사를 반복적으로 사용하는 것으로 나타났다.
Trans Abstract
Objectives:
This study is to examine the types and tokens of substantives and provide high frequency substantive word list derived from the spontaneous language of Korean young children. Substantives include common nouns (NN), proper nouns (NR), dependent nouns (NX), pronouns (NP), and numeral nouns (NU).
Methods:
The subjects were 80 children from age 2;0 to 5;11, selected from the Nazarene Spoken Language Corpus. Types and tokens of substantives were analyzed from a total of 27,485 utterances. Each word class of substantives was analyzed according to age group, and high frequency word lists for each word class were made.
Results:
First, the ratio of types and tokens of substantives within the total vocabulary was 43.8% and 25.6%, respectively. The frequency (descending order) of substance types was NN>NR>NX>NP>NU, and the frequency of substance tokens NN>NP>NX>NR>NU. Second, the 2-year-old group’s use of substantives for most word classes differed significantly from the older children. Third, the word lists showed that a limited number of NN, NX, and NP types were used recursively.
Conclusion:
An increase in the types and tokens of substantives was salient between the 2- and 3-year-old groups. The most frequent words used at any age were for human beings or objects. Among NNs, the older the children became, the more time category nouns they used. These results are discussed from a language development and Korean linguistics point of view.
모든 언어는 문장의 산출과 이해에 사용되는 기본적 구성요소인 단어 집합, 즉 어휘를 갖고 있다(Miller, 1991). 어휘 지식이 없다면 언어를 이해하고 산출하는 것이 가능하지 않으므로 어휘 발달은 언어 습득의 가장 본질적인 전제조건이라고 할 수 있다 (Anglin, 1993). 또한 어휘 발달은 인지 발달과 읽기 습득과 관련이 높으며 궁극적으로는 후일 학업성취에도 매우 결정적 역할을 한다 (Anglin, 1993; Owens, 2005).
이러한 어휘는 어원, 품사, 의미 등을 기준으로 분류되는데, 이중 분류 기준이 비교적 명확하며 분류 결과의 활용 가능성이 높은 것은 품사에 의한 분류이다. 품사 분류의 기준은 형태, 기능, 의미로서, 어휘는 형태적 기준에 의해 먼저 변화사와 불변화사로 나뉘고 기능에 의해 다시 체언, 수식언, 독립언, 관계언, 용언으로 나뉘며 의미적 기준에 의해 최종적으로 명사, 의존 명사, 수사, 동사, 형용사, 관형사, 부사, 감탄사, 조사의 9품사로 분류된다 (Shin et al., 2012). 이중 기능에 의한 어휘 분류는 단어가 문장에서 어떤 자격으로 쓰이는지를 보여준다는 점에서 중요한데, 기능에 의한 분류 결과인 체언, 수식언, 독립언, 관계언, 용언 중에서도 특히 체언은 단독으로, 혹은 조사나 다른 품사와 결합하여 문장에서 ‘주어, 목적어, 보어, 관형어, 부사어, 서술어’로 쓰이므로 기능을 고려할 때 가장 중요한 어휘 부류는 명사로 대표되는 체언이다.
체언은 아동 어휘 발달에서도 중요성을 가진다. Nelson (1973)은 아동들의 첫 어휘에서 50개 어휘까지의 발달 과정을 분석한 결과, 명사류가 가장 큰 범주임을 발견하였다. Gentner (1982)는 영어를 포함하여 6개의 언어권 아동들까지 확대하여 살펴본 결과, 아동들의 첫 50개의 어휘 목록에 명사가 압도적으로 많으며 명사롤 먼저 습득한다고 보고하였다. 최근 연구에 의하면,한국어나 중국어(만다린)를 모국어로 사용하는 아동들이 동사보다 명사롤 더 많이 습득하기는 하나 영어를 모국어로 사용하는 아동들보다 명사편향 (noun bias)을 덜 보이는 것으로 나타났다(Kauschke, Lee, & Pae, 2007; Kim, McGregor, & Thompson, 2000; Tardif, Gelman, & Xu, 1999).
이와 같이 명사는 언어발달 초기에서뿐 아니라 언어에서 중요한 위치를 차지한다. 실제로 명사는 내용어의 중요한 부분이고 단어 유형의 많은 부분을 차지하며, 언어학적인 복잡성에 기여한다. 일반적으로 명사는 말이나 글 내용의 흐름과 관련이 있어서 전반적인 담화를 조직하는 데에 중요한 역할을 한다 (Ravid, 2005). 또한 명사는 성인의 언어심리학적인 처리 과정뿐 아니라 아동의 발달에서 학습기제와 관련하여 중요한 위치를 차지한다(Clark, 1993; as cited in Markman, 1989; as cited in Ravid, 2006). 따라서 명사를 포함한 체언의 발달 양상을 살펴보는 일은 매우 의미있는 일이다.
학령전기 언어장애 아동의 평가와 중재는 구어를 기초로 이루어진다. 따라서 언어평가도구와 중재 프로그램의 개발에 가장 필요한 것은 일반아동이 사용하는 구어발달의 이정표이다. 일반아동들이 일상적인 의사소통에서 사용하는 어휘에 대한 수량적인 정보는 언어평가도구와 중재프로그램을 개발하는 데에 매우 중요하다. Kirk, Pisoni와 Osberger (1995)는 청각장애 아동의 평가를 위한 낱말재인검사 개발 시 기존의 검사항목이 일반 아동들의 어휘 빈도를 반영하고 있지 않다는 점을 보완하기 위하여 CHILDES (MacWhinney, 2000)의 자료를 기초로 낱말재인검사를 개발하였다. 따라서 학령전기 일반아동들의 어휘 빈도 정보와 어휘 목록은 조음음운검사를 포함하여 언어 발달 검사 개발 시 매우 유용한 자료가 될 것이다. 또한 언어치료사들의 경우 학령전기 아동들을 위한 언어 중재 목표를 선정하고 자료를 개발할 때 우리나라 일반아동의 연령별 어휘 목록과 어휘빈도 정보는 유용한 가이드를 제공하게 될 것이다.
아동의 언어 습득 과정에서 어휘 발달 과정을 살펴보기 위해서 는 어휘의 수집방법과 관찰 맥락에 대한 고려가 필수적이다. 특히 아동의 언어 발달 지표로 활용하기 위한 어휘 빈도 정보와 어휘 목록은 균형성과 대표성이 확보된 자발화를 기초로 도출되어야 한다(Leadholm & Miller, 1992; Oh, Cha, Yoon, Kim, & Chang, 2014). 말자료의 균형성이 확보되기 위해서는 특정 활동이나 특정 과제가 아닌 일상적 환경에서 수집되어야 하며, 대표성이 확보되기 위해서 는 적정 수 이상의 아동을 대상으로 하여야 한다. 또한 어휘 빈도 정보를 제공하기 위해서는 분석의 대상인 어휘의 기준이 명확해야 하며, 빈도 정보 이상의 다양한 어휘 정보를 제시할 필요가 있다 (Oh et al., 2014). 자료의 균형성과 대표성이 확보된 말뭉치 자료로, 영어권 아동들을 대상으로 하여 수집된 CHILDES (MacWhinney, 2000)와 SALT (Miller, 2003) 등이 있다. 국어에서 사용하는 대규모 말뭉치로는 ‘21세기 세종 말뭉치’와 ‘물결 21’이 있으나 성인의 구어가 아닌 문어를 중심으로 어휘 정보를 제공하고 있는 점이 한계이다.
학령전기 아동의 자발화를 기반으로 한, 80년대 중반 이후(언어학적으로 보통 한 세대를 30년으로 설정하므로 80년대 중반 이후의 연구로 한정하였다) 국내의 주요 어휘 연구로는 Choi, Kim 과 Shin (2004)의 연구와 Park과 Rhee (2011)의 연구가 있다. Choi 등 (2004)은 표준어를 사용하는 3-8세의 정상 발달 아동 총 60명을 대상으로 소꿉놀이와 그림책 보며 말하기에서의 나타난 자발화 500개를 기초로 어휘를 분석하였다. 이 연구에서는 내용어인 보통 명사, 부사, 관형사를 원어 정보별로 분석하고 고빈도 어휘를 구체적으로 제시하였다. 연구 결과, 명사의 사용 빈도는 전 연령에서 고유어가 한자어에 비해 우세하고, 고빈도 어휘는 3세에 출현하기 시작하여 전체 연령에서 높은 비중을 차지하였다. 이 연구는 표준어 사용 아동을 대상으로 하였고, 비교적 대규모의 언어 자료를 대상으로 하였으며, 품사별 연구에서 벗어나 어원에 초점을 맞추었다는 점에서 기존 연구와 차별성을 가진다. 그러나 특정한 그림책과 특정 활동을 중심으로 발화가 유도되어 특정한 어휘들이 산출되었고, 내용어라는 공통성 외에는 분포나 기능면에서 관련이 적은 품사인 명사, 부사, 관형사를 함께 묶어 분석하였으며 어종에 따른 어휘 빈도의 중요도가 품사 중심의 어휘 빈도에 비해 아동 언어 발달에서 상대적으로 높지 않다는 것이 연구의 제한점이다.
경남과 부산 지역의 3-5세 일반 발달 아동 18명을 대상으로 한 Park과 Rhee (2011) 는 일상적 이야기, 사진 보고 대화하기 등 5가지 공통 활동 중심의 자발화를 30-40분씩 수집한 후 2인의 연구자가 전체 전사를 수행한 발화자료를 분석하였다 이 연구에서 (1) 3-5세 일반 발달 아동의 어휘 수는 지속적으로 증가하며, (2) 3-4세보다 4-5세에서 새롭게 출현하는 어휘 수가 많으며, (3) 고빈도 어휘 중 3세는 명사나 동사, 4세는 특정 조사, 5세는 특정 관형사의 증가가 상대적으로 두드러진다고 보고하고 있다. 이 연구는 경남과 부산 지역 아동의 어휘 발달을 보여주는 자료라는 점에서 의미가 있으나 자료의 정확한 규모를 제시하지 않았고 형용사와 관형사를 같은 품사로 묶어 제시하였으며 제한된 수의 아동을 대상으로 특정한 맥락에서 자발화 자료를 수집한 것이 연구의 한계점이라고 할 것이다. 뿐만 아니라 ‘우리 집’과 같은 명사구가 고빈도 명사(14위)에 포함되어 있고 특정활동 중심의 어휘를 수집한 결과 ‘늑대, 빨간 모자, 사냥꾼’ 등과 같은 비일상적인 어휘가 고빈도 명사 목록에 포함되는 문제점을 가진다.
아동의 자발화에 기반한 선행 연구를 볼 때 아동의 어휘 빈도 정보는 특정 과제나 활동에 치우치지 않으면서 적정 수 이상의 아동을 대상으로 수집된 자발화에서 추출될 필요가 있음을 알 수 있다. 이와 같이 대표성과 균형성을 확보한 말뭉치를 기 반으로 분석된 자료는 일반 아동의 언어 발달을 타당하고 신뢰성 있게 보여줄 뿐 아니라 언어장애 아동들의 평가와 중재를 위한 기초자료로 사용될 수 있다. 본 연구에서는 대표성과 균형성을 확보한 아동의 자발화를 기초로,문장에서 여러 성분으로 기능하는 체언의 어휘 발달을 살펴보기 위하여 체언의 세부 품사별 유형 수와 사용 빈도를 분석하고 각 품사별 고빈도 어휘 목록을 제시하고자 한다.
연구 방법
연구 대상
이 연구는 서울과 경기 및 충청 지역에 거주하는 일반아동 만 2세부터 5세까지의 일반 아동으로 각 연령별로 남녀 각 10명씩 20명, 총 80명을 대상으로 하였다. 대상아동들은 (1) 부모가 정상발달하고 있다고 보고하고, (2) K M-B CDI (Pae & Kwak, 2011)나 수용•표현어휘력검사 (REVT; Kim, Hong, Kim, Jang, & Lee, 2009)에서 정상 발달 범주 내에 있으며, (3) Ling test (Ling, 1976)로 청력에 이상이 없는 아동으로 선정하였다.
자료 수집 및 분석
이 연구의 자료는 나사렛말뭉치의 일부로 나사렛말뭉치는 자연스러운 맥락에서의 발화를 확보하기 위하여 부모의 동의를 얻어 녹음기를 장착할 수 있도록 제작된 앞치마와 녹음기(Click Voice S300)를 지급한 뒤 일주일 동안 가정에서 일상적인 생활, 놀이시간에 자연스럽게 발화한 것을 10시간 이상녹음하고 이를 수거하여 전사 도구를 활용하여 전사한 자료이다. 나사렛 말뭉치에 관한 전사 및 발화 구분 원칙은 Kim, Yoon, Kim, Chang과 Cha (2012), Yoon, Kim, Kim, Chang과 Cha (2013)에 제시되어 있다. 분석에 이용된 자료는 2차 전사가 완료된 나사렛 말뭉치 중 아동 1인당 300-400여의 연속 발화를 무작위로 추출한, 80명 분 총 27,486 발화를 국어학박사 3인이 3차 검토를 실시한 65,783어절이다.
형태소 분석은 KSTARS (Kwak & Chang, 2014)에 내장된 형태소 분석기를 이용하여 1차로 자동 태깅을 하고, 웹의 표준국어대사전(http://stdweb2.korean.go.kr/main.jsp)을 기준으로 2차로 수동 태깅한 후 최종 자료를 얻어 분석하였다. 체언의 품사별 하위 분류는 국어 정보학 분야에서 이용되는 형태소 분석기(21세기 세종 계획 지능형 형태소 분석기 등)에서 보편적으로 설정하는 태그인 ‘보통명사, 고유명사, 의존명사, 대명사, 수사’를 최종 분석 요소로 하였다.
구어 말뭉치에서 어휘 정보를 추출한 후 이를 언어 발달 지표로 활용하고자 할 때에는 적정 수 이상의 아동을 대상으로 자료를 수집함으로써 말뭉치의 대표성을 담보해야 한다. 문어를 기준으로 5만 어절 규모의 말뭉치일 경우 규모의 대표성이 인정되는데 본고의 말뭉치는 총 80명 아동 65,783어절 규모이므로 대표성을 갖추고 있다. 또한 말뭉치의 균형성을 확보하기 위해서는 특정한 활동에 한정되지 않은 구어 자료에 기초해야 하는데, 본 연구는 아동의 일상적 환경에서 수집된 자발화 말뭉치를 기반으로 하였으므로 말뭉치의 균형성도 확보하고 있다.
통계
수동 태깅이 완료된 자료를 대상으로 전체 품사에서 체언의 품사별 유형 수와 사용 빈도의 비율 및 연령별 체언의 세부 품사 구성의 비율을 분석하였다. 또한 각 품사별로 유형 수와 사용 빈도의 연령 간 차이를 검증하기 위하여 SPSS 12.0으로 일원분산분석을 하였으며 집단 간 차이의 사후검증은 Scheffé를 사용하였다.
연구 결과
체언의 유형 수와 사용 빈도
전체 품사 중 체언의 유형 수와 사용 빈도
이 연구에서 2-5세 아동의 품사 전체의 유형 수는 4,679개, 사용 빈도는 105,284회이다(조사, 어미, 사전에 없는 미등재어 등이 포함된 것이다). 이중 2-5세의 체언 총 유형 수는 2,050개로 전체 유형 수 중 43.8%, 사용 빈도는 26,932회로 전체 사용 빈도 중 25.6%를 차지하였다(Table 1). 연령별 유형 수는 2세 554개, 3세 842개, 4세 921개, 5세 1,135개로 연령이 증가할수록 유형 수가 증가하였다. 연령별 사용 빈도는 2세 5,369회, 3세 7,106회, 4세 6,956회, 5세 7,501회로 연령이 높아질수록 사용 빈도도 증가하였다. 연령별 유형 수 비율은 2세 35.9%, 3세 40.0%, 4세 40.3%, 5세는 43.0%로 연령이 증가함에 따라 체언의 비중도 점차 증가하였는데, 특히 2세에서 3세 사이에 변화의 폭이 크게 나타났다. 연령별 사용 빈도 비율은 2세 27.2%, 3세 26.7%, 4세 24.6%, 5세 24.4%로 연령이 높아질수록 낮아지고 있다. 즉, 체언의 유형 수, 사용 빈도, 유형 수 비율은 연령이 높아질수록 증가하였으나, 사용 빈도 비율은 연령이 높아질수록 낮아졌다.
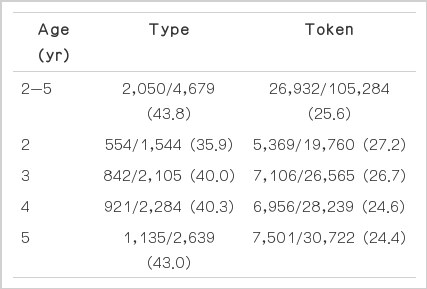
Type and token ratio of substantives in total vocabularies
체언의 품사별 유형 수와 사용 빈도
체언의 품사별 유형 수와 사용 빈도를 분석한 결과, 2-5세 말뭉치에 나타난 체언의 유형 수 중 보통 명사는 1,505개(73.4%), 고유 명사는 437개(21.3%), 의존 명사는 45개(2.2%), 대명사는 33개(1.6%), 수사는 30개(1.5%)로 나타났다(Table 2). 보통 명사와 고유 명사의 유형 수는 체언 유형 수의 94.7%를 차지하였으며 체언 내 유형 수 비율은 ‘보통 명사>고유 명사>의존 명사>대명사>수사’의 순으로 나타났다. 체언의 사용 빈도 중 보통 명사는 14,504회(53.9%), 고유 명사는 1,650회(6.1%), 의존 명사는 2,797회(10.4%), 대명사는 7,504회(27.9%), 수사는 477회(1.8%)로, 체언 내 사용 빈도 비율은 ‘보통 명사>대명사>의존 명사>고유명사>수사’의 순으로 나타났다.
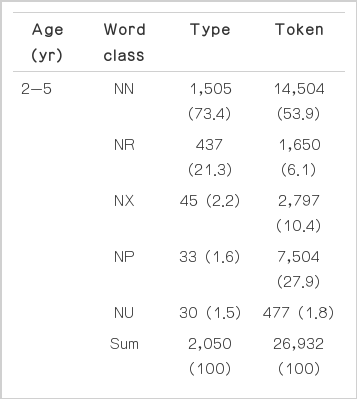
Type and token ratio of word classes in total substantives
품사별 유형 수와 사용 빈도의 연령 간 차이
보통 명사
각 연령 집단의 보통 명사 유형 수와 사용 빈도의 평균과 표준편차 및 일원분산분석 결과는 Table 3과같다. 보통 명사의 연령별 유형 수 평균과 표준편차는 2세 42.05 (±9.82)개, 3세 63.95 (±14.63)개, 4세 72.15 (±14.07)개, 5세 85.45 (±17.71)개로 나타났으며 보통 명사 유형 수의 연령 간 차이는 통계적으로 유의하였다(F(3,76)=32.24, p<.01). 연령별 보통 명사의 사용 빈도 평균과 표준편차는 2세 142.35 (±34.32)회, 3세 190.20 (±40.10)회, 4세 197.10 (±39.37)회, 5세 195.70 (±40.40)회로 나타났으며 보통 명사 사용 빈도의 연령 집단 간 평균은 통계적으로 유의하였다(F(3,76)=9.18, p<.01). Scheffé 사후 검정 결과, 유형 수에서는 2세가 다른 연령 집단과 유의한 차이를 보였으며, 3세는 5세와, 4세도 5세와 유의한 차이를 보였다. 사용 빈도에서도 2세는 다른 연령 집단과 유의한 차이를 보였다.
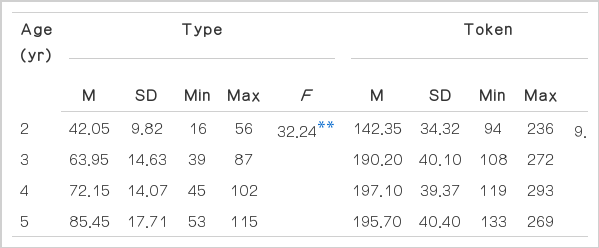
Descriptive statistics and ANOVA results of types and tokens of common nouns
고유 명사
각 연령 집단의 고유 명사의 유형 수와 사용 빈도의 평균과 표준 편차 및 일원분산분석 결과는 Table 4와 같다. 연령별 유형 수 평균과 표준편차는 2세는 5.40 (±3.69)개, 3세는 8.05 (±4.29)개, 4세는 7.00 (±3.77)개, 5세는 8.65 (±5.38)개였으며 연령 간 차이는 유의미하지 않았다. 각 연령 집단의 고유 명사 사용 빈도 평균과 표준편차는 2세 22.35 (±14.05)회, 3세 22.45 (±16.13)회, 4세 17.00 (±12.34)회, 5세 20.75 (±13.47)회로 나타났으며 연령 간 차이는 유의미하지 않았다.

Descriptive statistics and ANOVA results of types and tokens of proper nouns
의존 명사
각 연령 집단별 의존 명사의 유형 수와 사용 빈도의 평균과 표준 편차 및 일원분산분석 결과는 Table 5와 같다. 의존 명사의 유형 수 평균과 표준편차는 2세 3.60 (±1.67)개, 3세 5.30 (±2.18)개, 4세 6.70 (±2.06)개, 5세 9.20 (±1.99)개이며 연령 간 차이는 통계적으로 유의하였다(F(3,76)=28.56, p<.01). 각 연령 집단의 의존 명사 사용 빈도 평균과 표준편차는 2세 20.15 (±10.79)회, 3세 31.35 (±11.45)회, 4세 38.40 (±13.97)회, 5세 49.95 (±18.24)회로 나타났으며 연령 간 차이는 통계적으로 유의하였다(F(3,76)=16.12, p<.01). Scheffé 사후검증 결과 의존 명사의 유형 수에서 2세는 4, 5세와 3, 4세는 5세와 유의한 차이를 보였고 사용 빈도에서 2세는 4, 5세와, 3세는 5세와 유의한 차이를 보였다.
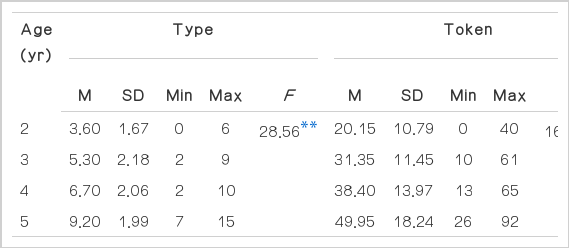
Descriptive statistics and ANOVA results of types and tokens of dependent nouns
대명사
각 연령 집단의 대명사의 유형 수와 사용 빈도의 평균과 표준편차 및 일원분산분석 결과는 Table 6과 같다. 대명사의 유형 수 평균과 표준편차는 2세 9.20 (±2.33)개, 3세 11.65 (±3.00)개, 4세 11.95 (±1.73)개, 5세 13.55 (±2.61)개로 나타났으며 연령 간 차이는 통계적으로 유의하였다(F(3,76)=10.68, p<.01). 대명사의 사용 빈도 평균과 표준편차는 2세 81.6 (±35.18)회, 3세 104.70 (±27.68)회, 4세 91.05 (±26.12)회, 5세 98.10 (±23.49)회이며 연령 간 차이는 유의하지 않았다. Scheffé 사후검증 결과 대명사의 유형 수는 2세가 3, 4, 5세 집단 모두와 유의한 차이를 보였다.
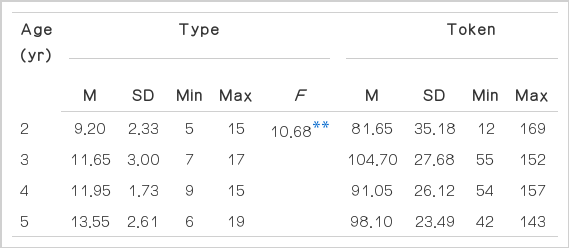
Descriptive statistics and ANOVA results of types and tokens of pronouns
수사
각 연령 집단의 수사의 유형 수와 사용 빈도의 평균과 표준편차 및 일원분산분석 결과는 Table 7과 같다. 수사의 유형 수 평균과 표준편차는 2세 1.35 (±1.42)개, 3세 2.45 (±2.70)개, 4세 2.20 (±1.99)개, 5세 5.25 (± 6.29)개로 나타났으며 연령 간 차이는 통계적으로 유의하였다(F(3,76)=4.33, p<.01). Scheffé 사후검증 결과 유형수의 연령 집단 간 차이는 2세가 5세 집단에서 유의한 것으로 나타났다. 수사의 사용 빈도 평균과 표준편차는 2세 2.10 (±2.38)회, 3세 6.75 (±10.15)회, 4세 4.30 (±4.58)회, 5세 10.05 (±15.00)회이며 연령 간 차이는 유의하지 않은 것으로 나타났다.
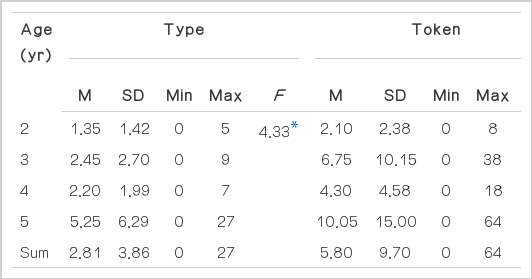
Descriptive statistics and ANOVA results of types and tokens of numeral nouns
빈도에 따른 체언 목록
보통 명사, 고유명사, 의존 명사, 대명사, 수사를 대상으로 2-5세 전체와 각 연령별 사용 빈도 순 어휘 목록을 제시하였다. 2-5세 전체의 고빈도 보통 명사 목록은 지면상 누적 비율 50%인 60위까지 제시하였으며 각 연령별 보통 명사 목록은 누적 비율을 고려하지 않고 60위까지 제시하였다. 출현 빈도가 동일한 보통 명사(2-5세에서 각각 107회 출현한 밥, 선생님)는 원칙상 동일 순위로 제시하여야 하나 지면상 연령별 목록에서 순위를 별도로 밝히지 못하므로 2-5세 및 연령별 목록에서 가나다 순에 따라 순위에 차등을 두었다 (Appendix 1). 빈도 확인의 의의가 상대적으로 적고 연령별로 유의한 차이가 나타나지 않는 고유 명사는 2-5세 통합 목록만 제시하되 만화 등의 캐릭터 이름인지 아니면 아동 이름인지를 구분하여 아동 이름인 경우는 두 번째 글자를 ○로 표시하여 제시하였다(Appendix 2). 마지막으로 상대적으로 유형 수가 적은 의존명사, 대명사, 수사는 누적 비율 90% 내외 10위까지 보여주었다(Appendixes 3-5).
보통 명사
사용 빈도 1순위인 보통 명사는 ‘엄마’로 2,691회, 18.6%의 비율 을나타냈다. 2순위는‘아빠’로서 544회, 3.8%로 1위와 큰 격차를 보인다. 3순위인 ‘언니’는 313회, 2.2%의 비율로, 이 세 명사의 누적 사용 빈도가 24.5%에 해당한다. 이외에 누적 빈도 상위 50%에 해당하는 명사는 ‘아이, 때, 집, 책, 물, 차 밥’ 등이다. 보통 명사의 사용 빈도 순위에 따른 어휘 목록은 상위 60개로 한정하여 Appendix 1에 수록하였다.
고유 명사
사용 빈도 1순위인 고유 명사는 ‘뽀로로’로 52회, 3.2%의 비율을 보인다. 2순위는 ‘폴리’로서 51회, 3.1%로 1위와 큰 차이가 없다. 이외에 아동의 인명이 아닌 확실한 캐릭터 이름으로는 ‘스노우맨, 짱구, 크롱, 코코몽, 엠버, 파워레인저’가 있으며 이들 캐릭터의 출현 빈도 비율이 전체의 14.5%에 이른다. 고유 명사의 사용 빈도 순위에 따른 어휘 목록은 상위 20개로 한정하여 Appendix 2에 수록하였다.
의존 명사
가장 높은 사용 빈도를 보인 의존 명사는 1,850회 사용된 {것}으로 (이 연구에서는 ‘것’의 구어인 ‘거’를 ‘것’에 통합하여 빈도를 추출하였으므로 형태소를 표시하는 { } 기호를 사용하였다) 전체 의존 명사 중 66.1%에 해당한다. 2순위는 수량을 세는 의존 명사인 ‘개’로 215회, 7.7%의 비율이며, 3순위는 ‘수’로 120회, 4.3%의 비율이다. 이 세 의존 명사와 ‘번, 살, 데, 씨(‘씨’는 아동 발화에서 등장하기 어려운 형태이나 ‘엄마’를 ‘엄마씨’로 부르는 발화 습관을 가진 아동으로 인해 고빈도 어휘로 등장하게 되었다), 원, 분’이 누적 비율 90.8%를 차지한다. 의존 명사의 사용 빈도 순위에 따른 어휘 목록은 상위 10위로 한정하여 Appendix 3에 제시하였다.
대명사
대명사 중 사용 빈도 1순위는 2,218회 사용, 29.6%의 비율을 보 인 지시 대명사 {이것}이며 2순위는 1,662회 사용, 22.1%의 비율을 차지한 1인칭 대명사 ‘나’이다. 3위는 장소를 지시하는 {여기}로 844 회 출현, 11.2%의 비율로 나타났다. 상위 3개의 대명사인 ‘이것, 나, 여기’가 누적 비율 63.0%를 차지한다. 대명사의 사용 빈도 순위에 따른 어휘 목록은 상위 10위로한정하여 Appendix 4에 제시하였다.
수사
수사 중 사용 빈도 1순위는 122회사용, 25.6%의 비율을 보인 ‘하나’이며, 2순위는 58회, 12.2%의 비율을 보인 ‘둘’이고 3순위는 40회 사용, 8.4%의 비율인 ‘셋’으로 나타났다. 이와 같이 고유어계 수사 ‘하나, 둘, 셋’의 누적 빈도가 46.1%에 해당한다. 누적 빈도 90%에 포함되는 수사는 모두 17개이며 수사의 사용 빈도 순위에 따른 어휘 목록은 상위 17위까지 Appendix 5에 제시하였다.
논의 및 결론
본 연구는 학령 전기 아동의 자발화 말뭉치에서 나타나는 체언의 어휘 빈도 양상을 고찰하여 언어장애아동의 언어 평가 및 중재에 활용할 수 있는 기초 자료를 제공하는 것을 목적으로 하였다. 이를 위하여 나사렛 말뭉치 중에서 2세-5세 아동의 일상 자발화를 대상으로 체언 전체의 유형 수 및 사용 빈도, 체언의 품사별 유형 수와 사용 빈도의 연령 간 차이를 밝히고 사용 빈도가 높은 보통 명사, 고유 명사, 의존 명사, 대명사, 수사의 목록을 제시하였다.
체언의 유형 수와 사용 빈도
나사렛 말뭉치 2-5세 아동의 자발화를 분석한 결과, 체언의 유형 수 비율은 43.8%, 사용 빈도 비율은 25.6%로 나타났다. 연령별 유형 수와 사용 빈도 비율은 2세 35.9%와 27.2%, 3세 40.0%와 26.7%, 4세 40.3%와 24.6%, 5세 43.0%와 24.4%로 나타났는데 이를 자발화 기반의 최근 선행 연구와 비교하면 본 연구의 비율이 현저히 낮다. 공통 활동 등이 포함된 말뭉치에 기반한 Park과 Rhee (2011)의 연구 결과에 따르면 명사(본 연구의 체언에 해당)의 유형 수는 3세 42.6%, 4세 41.5%, 5세 42.8%로 본 연구보다 높게 나타났다. 이는 본 연구의 품사 목록 속에 발화 요소인 간투사(감탄사), 표준국어대사전에 없는 미등재어, 조사나 어미와 같은 문법소가 포함되어 있기 때문이다. 간투사나 미등재어, 문법소 등을 제외하면 체언의 비율이 높아질 것이나 이 요소들 또한 발화를 구성하는 요소이므로 있는 그대로의 자료에 기반한 결과 선행 연구에 비해 유형 수와 사용 빈도가 낮게 나타났다.
체언 내 품사별 유형 수 비율은 3.1.2에 제시하였듯이‘보통 명사 (73.4%) >고유 명사(21.3%) > 의존 명사(2.2%) > 대명사(1.6%) > 수사(1.5%)’의 순서이나 사용 빈도 비율은 ‘보통 명사(53.9%)>대명사 (27.9%) > 의존 명사(10.4%) >고유 명사(6.1%) > 수사(1.8%)’로 나타났다. 체언 중 보통 명사의 유형 빈도와 사용 빈도가 가장 높은 것은 개방 집합인 보통 명사의 어휘적 특징을 보여주는 것이며 고유 명사의 유형 빈도 비율이 높고 사용 빈도 비율이 낮은 것은 ‘유일성에 기초한 다양성’정도로 기술될 수 있는 고유 명사의 의미적 특징을 보여주는 것이다. 한편, 대명사의 유형 수 비율은 2.2%이지만 사용 빈도 비율은 27.9%, 의존 명사의 유형 수 비율은 1.6%이지만 사용 빈도 비율은 10.4%로 이 두 품사의 사용 빈도 비율이 38.3%나 된다. 이는 빈도의 관점에서 보면 대명사와 의존 명사는 조사나 어미와 같은 문법소들과 유사한 특징을 가진다는 것을 보여준다. 유형 수는 적지만 발화에서 반복적으로 사용된다는 점에서 폐쇄 집합인 문법소와 분포적으로 유사한 것이다.
연령별 체언 발달 양상
보통 명사는 유형 수와 사용 빈도에서 2세가 다른 모든 집단과 유의한 차이를 보였다. 이는 어휘 폭발기를 지나 급격히 증가하는 어휘의 수와 함께 증가하는 구문 능력과 관련 있어 보인다. Oh 등 (2014)의 연구에서도 용언의 유형 수와 사용 빈도 수가 2세에서 3세 시기에 걸쳐 유의하게 증가하였다. 많은 연구들은 어휘의 양과 구문발달이 밀접한 관계가 있다는 것을 보여준다. Bates, Bretherton과 Snyder (1988)는 비록 초기 언어발달의 자료를 근거로 하였으나, 어휘 양과 후일 MLU가 높은 상관(.83)이있다고보고하였다 (as cited as McGregor, Sheng, & Smith, 2005). McGregor 등(2005) 또한 2세 아동의 문법 발달이 어휘의 양과 밀접한 관계가 있다는 것을 보여주었다. 우리나라 아동들은 2-3세가 기본 문법을 탐색하는 시기로 2세 후반이 되면 언어의 표현을 한국어의 문법특성에 맞추게 되어 명사구나 동사구가 자주 사용하며, ‘거’를 중심으로 관형절의 사용이 활발해진다(Pae, 2010). 구문 발달은 문장의 필수 성분인 주어, 목적어 외에 수식 성분인 부사어, 관형어의 발달을 의미하는데 체언은 문장에서 이 모든 성분으로 기능할 수 있다. 2세에서 3세 간 명사의 유의한 증가는 다양한 구문의 발달과의 관련성을 뒷받침한다.
고유 명사는 유형 수와 사용 빈도에서 연령 간 차이를 보이지 않았다. 이는 개별 인명을 제외하면 2-5세 아동이 산출하는 고유 명사가 대체로 동질적이거나 획일적임을 의미한다. 실제로 본고에서 제시한 고빈도 고유 명사(Appendix 2)목록은 ‘생활 어휘’가 아닌 ‘문화 어휘’를 반영하는데 이중 고빈도 만화 캐릭터 이름 8개(뽀로로, 폴리, 짱구 등)가 전체 고유 명사 빈도의 14.5%를 차지하고 있다. 이는 현재 유행하는 문화 상품과 아동들의 관심사를 반영하는 흥미로운 결과이기도 하나 한편으로는 아동들이 획일적인 문화 상품의 영향 아래 놓여 있다는 것을 보여준다.
3.2.3의결과, 의존 명사 유형 수에서 2세는 4, 5세와, 3, 4세는 5세와 유의한 차이를 보이고 사용 빈도에서 2세는 4, 5세와, 3세는 5세와 유의한 차이를 보임을 확인한 바 있다. 연령이 증가할수록 의존 명사의 유형 수가 증가하나 그 변화는 보통 명사만큼 확연하지 않은데, 이는 의존 명사의 목록이 한정되어 있어 개방 집합인 보통 명사와 그 특성을 달리하기 때문이다. 실제로 고빈도 의존 명사의 구체적 목록(Appendix 3 참조)을 보면 순위 변화는 보이지만 목록 구성 요소에는 큰 변화가 없다. 하지만 사용 빈도 1위인 의존 명사 ‘것’의 연령별 사용 빈도 비율(Appendix 3 참조)을 보면 2세 78.9%, 3세 75.9%, 4세 59.5%, 5세 60.0%로 3세에서 4세로 넘어갈 때 그 비중이 낮아지는데 이는 이 시기에 의존 명사의 유형 수가 늘어난다는 것을 의미한다. 고빈도 의존명사의 출현 순서를 보더라도 2세에 ‘것’이 나타나 3-5세까지 지속되고 3세에는‘데’, 4세에는‘줄’이 고빈도 목록에 새롭게 등장하는데 이는 의존 명사의 유형 수 증가와 관련된다.
대명사는 유형 수에서 2세가 3, 4, 5세 집단 모두와 유의한 차이를 보였고 사용 빈도에서는 유의한 차이를 보이지 않았다. 이는 2-3세에서 대명사의 다양성이 늘어남을 의미한다. 실제로 고빈도 대명사 목록(Appendix 4 참조)을 보면 순위 1위인 대명사 ‘이것’의 연령별 사용 빈도 비율은 2세 43.2%, 3세 29.6%, 4세 24.8%, 5세 24.9% 로 2세에서 3세로 넘어갈 때 비중이 크게 낮아지고 3, 4, 5세는 큰 변화를 보이지 않는데, 이는 2-3세 이 시기에 대명사의 유형 수가 늘어난다는 것을 의미한다. 하지만 고빈도 대명사의 목록 및 사용 비율에서는 연령별 차이가 크게 보이지 않는다. 이는 2세에 이미 주요한 대명사를 습득하여 발화 안에서 사용한다는 것을 뜻한다. 이런 점에서 고빈도 대명사는 언어 발달을 보여주는 지표로 볼 수 있다.
수사는 유형 수에서 2세가 5세 집단과 유의한 차이를 보였다. 실제로 2세에서 출현하는 수사의 총 유형 수는 12개에 불과하다 (Appendix 5 참조). 순위 1위인 수사 ‘하나’의 사용 빈도 비율은 2세 45.2%, 3세 25.9%, 4세 35.6%, 5세 17.4%로 2세에서 3세로 넘어갈 때 비중이 크게 낮아진 후 3세 이후는 증감을 보이는데, 이는 2-3세 시기에 수사의 유형 수가 늘어난다는 것을 의미한다.
수사의 발달에서 눈 여겨 볼 내용은 한자어계 수사 및 서수사의 등장 시기이다. 한국어의 수사는 ‘하나, 둘, 셋…’과 같은 고유어계 수사, ‘일, 이, 삼…’ 등의 한자어계 수사, 수량을 세는 기수사(하나, 둘, 셋.../일, 이, 삼…), 순서를 세는 서수사(첫째, 둘째, 셋째…)로 분류되는데, 계열별 수사의 사용 양상이 연령별로 다르게 나타나는 것이다. 2세에는 고유어계 기수사인 ‘하나, 둘, 셋’이 1, 2, 3순위로서 누적 비율 76.2%이며 한자어계 기수사인 ‘일’도 출현한다. 3세에도 ‘하나, 둘, 셋’이 1, 2, 3순위를 기록하지만 누적 비율은 53.3%로 낮아지고 5보다 큰 고유어계 기수사 ‘여섯, 여덟’ 및 ‘이, 삼, 사’등의 한자어계 기수사도 출현하게 된다. 이 시기부터 더 다양한 유형의 수사를 사용하게 되는 것이다. 4세에는 ‘천, 만’처럼 큰 수가 나타나며 목록에는 제시되지 않았지만, 5세에는 ‘둘째’와 같은 서수사가 출현한다. 대체로 고유어계에서 한자어계, 기수사에서 서수사, 작은 수에서 큰 수로의 수사 발달을 확인할 수 있다.
고빈도 체언의 특징
세부 품사에 따라 다소 차이가 있지만 소수의 어휘가 높은 사용 빈도를 보이고 있는 점이 고빈도 체언에 보이는 분포적 특징이다. 2-5세에서 보통 명사의 경우 1,505 유형 중 상위 빈도 60개가 누적 비율 50.5%를 차지했다. 의존 명사는 편중이 더 심해서 {것}이 누적 빈도 66.1%를 차지하였으며 대명사도 ‘이것, 나, 여기, 내’가 누적 비율 70%를 차지하고 있다. 또 수사도 ‘하나, 둘, 셋’이 누적 비율 46.1%를 나타내고 있다.
전 연령에 걸쳐 보통 명사 중 사용 빈도 1순위는‘엄마’이다. ‘아빠’는 사용 빈도에서 2위이지만 ’엄마’와의 격차가 크다. 아동 자발화에 기반한 Park과 Rhee (2011)에서도 최고빈도 어휘는 ‘엄마’로 나타났다. 반면 아동기 이후 ‘엄마’는 최고빈도 어휘가 되지 못한다. Chang 등(2012)에서 ‘엄마’는 초등 저학년 2위(2.1%), 초등 고학년 4위(1.6%), 중학생 6위(1.6%), 고등학생 12위(1.0%)로 나타났다. 또 성인의 문어 말뭉치를 기반으로 한 현대국어 사용 빈도 조사 결과 (Institute of Korean Language, 2002)에서 ‘엄마’는 813회 출현하는데, 이는 전체 명사 39,856개 중 2.0%에 해당한다. 이는 말뭉치의 종류 및 대화 상황에 따라 어휘 빈도가 영향을 받는다는 것을 보여준다.
Choi 등(2004)에는 3세의 고빈도 명사 목록이, Park과 Rhee (2011)에는 3, 4, 5세의 고빈도 명사 목록이 각 20개씩 제시되어 있다. 따라서 3세 20개 고빈도 명사 목록을 중심으로 본고의 결과와 Choi 등 (2004), Park과 Rhee (2011)를 비교한 결과, 본고는 ‘엄마, 아빠, 선생님, 언니, 집, 애기, 친구, 밥, 물, 아이스크림, 때, 꽃, 아이, 차, 형, 유치원, 불, 소리, 사람, 코’로 나타났고 Choi 등(2004)은 ‘엄마, 때, 집, 할머니, 언니, 동생, 사람, 다음, 애, 오빠, 밥, 이제, 날, 안, 말, 물, 누나, 옷, 속, 아이’로 나타나 20개 중 ‘엄마, 때, 집, 언니, 사람, 밥, 물, 아이’의 8개 단어가 일치하였다. Park과 Rhee (2011)에서는 3세의 고빈도 명사로 ‘엄마, 것, 할머니, 늑대, 나, 여기, 누나, 선생님, 집, 동생, 배, 아빠, 우리, 우리 집, 모자, 아줌마, 빨간모자, 아저씨, 경찰, 눈’을 제시하였는데, 이중 의존 명사 ‘것’, 대명사 ‘나, 우리, 여기’, 명사 구인 ‘우리집’을 제외하면 ‘엄마, 선생님, 집, 아빠’의 네 단어가 일치한다. Park과 Rhee (2011)에서 고빈도 명사로 제시된 ‘늑대’와 ‘빨간모자’는 본 연구 결과에 의하면 상위 20위, 누적 비율 50% 안에도 들지 못하였는데, 이는 Park과 Rhee (2011)에서 수집된 자발화가 동화 읽기와 같은 활동을 포함하고 있기 때문이다. 이는 문맥에 따라 어휘 빈도가 영향을 받는다는 것을 드러내 주는 것으로 말뭉치 구축 과정에서 균형성과 대표성을 고려하는 것이 중요함을 보여준다.
고빈도 보통 명사를 의미 범주 측면에서 살펴본 결과, 의미적인 편중을 보여 ‘인간, 물건’의 범주에 속하는 단어들이 고빈도로 나타났다. 인간 범주에 속하는 단어로는 ‘아빠, 엄마, 할머니, 형, 누나, 언니, 오빠, 사람, 아이, 애기, 선생님, 친구’등이 있는데 연령이 어릴수록 가족 관계어의 비중이 높고 연령이 증가하면서 ‘선생님, 친구’와 같은 사회 관계까지 어휘 종류가 늘어났다. 물건 범주에 속하는 단어는 ‘의자, 펜, 약, 책, 계란, 고기, 과자, 김밥, 김치, 당근, 물, 밥, 빵, 아이스크림, 우동, 우유, 팬티, 총, 배, 버스, 차’등이 있는데, 세부적으로는 ‘도구, 문구, 서적, 음식, 의류, 탈것’ 등으로 그 종류가 다양했다. 모든 연령에서 공통적으로 등장하는 의미 범주는 ‘공간, 동물, 물건, 상태, 시간, 식물, 인간, 장소, 척도, 행위’였고 ‘감각’에 해당하는 단어‘맛’, ‘현상’에 해당하는 단어인 ‘불, 비, 소리’는 3세에, ‘정도’에 해당하는 단어인 ‘완전, 조금’은 4세에 나타난다. 이중 ‘완전’과 ‘조금’은 품사는 명사이지만 문장 내에서 실제적으로 부사어로 쓰인다는 점에서 구문 발달과 관련되어 있다. 5세에는 ‘때, 그다음, 한번, 다음, 잠깐, 단계, 끝, 밤, 시간’과 같이 ‘시간’ 범주의 단어가 늘어나고‘ 장소_기관’ 범주인 ‘어린이집, 유치원’ 등의 어휘도 관찰되는데 이 두 부류의 어휘는 5세가 사회 생활이 본격적으로 시작되는 시기라는 것과 관련을 가진다.
2-5세 자료에서 누적 비율 90% 정도에 속하는 의존 명사 중 ‘개, 번, 살, 원, 분’등은 단위성 의존 명사, ‘것, 수, 데’는 각각 ‘사물, 추상, 장소’를 뜻하는 의존 명사로, 아동들이 다양한 부류의 의존 명사를 사용하고 있음을 보여준다. 의존 명사 중 가장 고빈도는 {것}으로 전체의 66.1%를 차지한다. ‘것’은 주로 ‘동사 어간 + 관형형 어미 -ㄹ/-ㄴ’ 뒤에 분포하여 ‘먹을 거, 탈 거, 놀 거’와 같은 구를 생성하거나 불확실한 단정이나 추측을 뜻하는 ‘-ㄹ/-ㄴ 것 같다’류의 양태 표현을 만들어 낸다. ‘것’의 빈도는 2세 318회, 3세 476회, 4세 457회, 5세 599회로 2-3세사이, 3/4-5세 사이에 증가하는데 이것은 양태 표현의 증가와 관련된 것으로 보인다. 의존 명사 ‘수’도 ‘동사 어간 + 관형형 어미 -ㄹ’ 뒤에 분포하여 주로 ‘-ㄹ수 있다/없다’와 같은 양태 표현을 만들어 내는데, ‘수’의 빈도도 2세 5회, 3세 20회, 4세 44회, 5세 51회로 증가하고 있어 3-4세 사이 양태 표현의 증가를 추측할 수 있다. 단, 이 문제는 본고의 연구 주제를 넘어서는 것으로 의존 명사가 포함된 양태 표현을 연령을 변수로 고찰할 필요가 있어 보인다.
2-5세 자료에서 누적 비율 90%에 속하는 대명사 중 ‘나, 내, 우리, 너’는 인칭 대명사이고 ‘이것, 그것’은 지시 대명사이며 ‘여기, 어디’는 장소 대명사, ‘뭐, 누구’는 의문 대명사로서 다양한 대명사가 출현하는 것을 확인할 수 있다. 이중 가장 고빈도로 쓰이는 대명사는 지시 대명사 ‘이것’으로 29.6%의 비중을 가진다. 지시 대명사 중 근칭인 ‘이것’과 ‘그것’이 누적 빈도 90% 내에 있는데 반해 65회 출현한 ‘저것’은 이 범위 안에 들지 못하는데, 이는 가까운 곳에서 먼 곳으로 아동의 행동이나 관찰 반경이 확대되는 과정을 간접적으로 보여준다 하겠다. 고빈도 대명사 순위가, 2, 3세에는 ‘이것 > 나 > 여기’의 순서였다가 4, 5세에는 ‘나 > 이것 > 여기’로 바뀌는 것도 흥미롭다. 1인칭 소유 대명사 ‘내’의 비율이 2세 75회, 4.6%에서 3세 162회, 7.7%로 증가하는 것도 ‘나’의 서열 바꿈과 궤를 같이 하는 변화라 할 것이다.
누적 빈도 90%에 속하는 수사로는 고유어계 수사 ‘하나, 둘, 셋, 넷, 다섯, 여섯, 일곱, 여덟, 아홉, 열’과 한자어계 수사 ‘일, 이, 삼, 사, 구, 십’이 포함되는데, 이를 통해 2-5세 아동의 산출 어휘에서 큰 자릿수의 수사는 고빈도로 출현하지 않으며 고빈도 수사 목록에는 수량을 세는 기수사만 포함되는 것을 알 수 있다. 서수사는 기수사에 비해 늦게 출현하는 것이다.
이 연구는 2세-5세 일반 아동의 자발화 말뭉치를 기반으로 체언 빈도 정보를 제시하고 이 정보를 아동의 어휘 발달과 국어학적 관점에서 논의하였다.
먼저 체언 내 품사별 유형 수 비율은 ‘보통 명사(73.4%) > 고유 명사(21.3%) > 의존 명사(2.2%) > 대명사(1.6%) > 수사(1.5%)’의 순서이나 사용 빈도 비율은 ‘보통 명사(53.9%) > 대명사(27.9%) >의존 명사(10.4%) >고유 명사(6.1%) > 수사(1.8%)’임을 밝혔다. 이는 보통 명사, 고유 명사가 언어적으로 개방 집합의 특성을, 의존 명사와 대명사가 폐쇄 집합의 특성을 가진다는 것과 관련된다. 연령에 따른 체언의 발달에서는 2세-3세가 중요한 시기임이 드러났다. 보통 명사, 의존명사, 대명사, 수사의 유형 수 및 사용 빈도에서 2세는 3, 4, 5세, 4, 5세, 또는 5세 연령 집단과 뚜렷한 차이를 보였다. 본고와 동일한 자료로 용언을 대상으로 연구한 Oh 등(2014)에서도 2세는 다른 연령 집단과 구분된다고 보고되었다. 이렇게 보면 아동 어휘의 양적 발달에서 가장 중요한 시기는 2-3세라고 일반화할 수 있다. 2-5세 아동이 산출한 고빈도 보통 명사는 ‘가족, 물건, 동물, 식물, 장소’ 등 실체성을 가진 어휘들이 대다수였고 ‘공간, 시간, 지각, 정도’ 등 비실체적이고 추상적인 의미를 가진 어휘는 상대적으로 적었다. 의존 명사는 소수의 예가 고빈도로 사용되었고 ‘것, 수’등의 의존 명사가 연령이 높아질수록 증가하는 것은 양태 표현과 관계된 것으로 보인다. 대명사는 의미적으로 ‘인칭, 지시, 의문’의 대명사가 다양하게 사용되었으며 수사는 고유어계 기수사가 한자어계 기수사보다 높은 빈도로 출현하였다.
이상 본 연구에 제시된, 학령 전기 일반 아동의 연령별 체언 발달 특성은 언어장애 아동의 체언 발달을 평가하는 기초 자료로 활용할 수 있을 것이다. 또 체언의 품사별 고빈도 어휘 목록은 언어장애 아동의 평가와 중재 목표 어휘 선정에서 주요한 근거 자료가 될 것이다.
본 연구의 제한점은 다음 두 가지이다. 첫 번째로, 대상아동들의 연령이 낮을수록 아동들이 사용한 동일한 어휘가 맥락에 따라 다른 의미로 사용되었을 수가 있었으나 자료 정련에서 이를 구별하지 못하였다. 두 번째로, 이 시기의 아동들은 언어발달에 있어서 성별의 차이가 있으며 특히 고유 명사는 성별에 따른 어휘 차이가 많이 날 것으로 예상되나 지면상 이 논문에서 다루지 못하였다. 향후 학령 전기 아동의 언어 발달에 대한 깊이있는 이해를 위해서는 의존 명사가 포함된 양태 표현을 연령별로 살펴볼 필요성이 있고 중의성 해소 말뭉치를 기반으로 명시적인 명사 분류 체계를 적용하여 의미 분류를 수행할 필요가 있다.




