의사소통장애의 평가 및 진단에서 인공지능 적용과 성과에 관한 체계적 문헌고찰
Applications and Performances of Artificial Intelligence in Assessment and Diagnosis of Communication Disorders: A Systematic Review of the Literatures
Article information
Abstract
배경 및 목적
본 연구는 최근 5년간 말 · 언어장애 평가 및 진단을 위해 활용된 인공지능의 전반적 연구 동향을 살펴보고 향후 의사소통장애 분야에서의 인공지능 적용에 대한 시사점을 고찰해 보기 위해 시행되었다.
방법
체계적 문헌고찰 방법에 따라 2016년부터 2021년 8월까지 국외 학술지에 게재된 총 18편의 논문의 질적분석을 실시하고 특성 및 수행력을 중심으로 분석하였다.
결과
본 연구에서 선정된 18편의 논문은 전반적으로 낮은 비뚤림을 보고하였고 2018년부터 인공지능을 활용한 평가 및 진단 관련 연구가 증가하는 추세를 보였다. 선정된 문헌의 연구 대상 연령대의 경우 주로 아동을 대상으로 실시되었으며, 분석문헌의 대부분은 실험연구를 통해 그것의 실효성을 검증하였다. 평가 및 진단을 위해 추출된 특성은 음향학적 특성이 주로 사용되었고 말하기 과제 및 음소, 단어 수준에서 분석이 이루어졌으며, 인공지능의 수행력 결과는 목적 및 지표에 따라 상이했다.
논의 및 결론
본 연구에서는 의사소통장애 분야에서 인공지능 기술을 활용하고자 하는 활발한 시도를 확인하였고 실제 임상현장 적용 가능성을 위한 논의가 이루어졌다. 인공지능이 평가 및 진단을 목적으로 활용되기 위해서는 언어병리학 전문가의 적극적 참여를 통해 각 대상군의 말·언어적 특성을 기반으로 하는 평가 과제 적용이 모색되어야 하며 언어병리학 분야 내 축적된 지식이 반영된 양질의 빅데이터 구축이 선행되어야 한다.
Trans Abstract
Objectives
A systematic review of the literature was undertaken (1) to investigate research trends on how artificial intelligence is being used for assessment and diagnosis in the field of communication disorders and (2) to suggest consideration and a directions for the effective use of artificial intelligence in clinical settings.
Methods
A total of 328 articles published in foreign journals between January 2016 and August 2021 were searched using 6 databases and a manual search, and 18 articles were finally selected according to PICO strategy (Population, Intervention, Comparison, Outcome) inclusion and exclusion criteria. Four authors determined the report selection and data extraction. They also independently analyzed the quality of the selected papers using QUADAS-II (Quality Assessment of Diagnostic Accuracy Studies-II).
Results
Firstly, the selected studies had a generally low risk of bias. Secondly, the major subjects of studies were children with communication disorders. Thirdly, most of the studies included in the analysis were experimental studies to verify the effectiveness of using artificial intelligence. Lastly, the extracted features for assessment and diagnosis were biased against acoustic features at the levels of phoneme and word in speaking tasks. The performance of artificial intelligence in the selected studies differed according to the research purpose and evaluation metrics.
Conclusion
This study suggests that in order for artificial intelligence to be used in the assessment and diagnosis system, it is essential to acquire clinically reliable and high-quality big data on the characteristics of speech and language of people with communication disorders.
최근 전 세계는 인공지능(artificial intelligence, AI)의 급속한 발전으로 인해 인간 삶 전반에 걸친 거대한 패러다임의 변화를 맞이하고 있다(Dhilon et al., 2021). 이러한 인공지능 시대가 본격화되면서 언어병리학 분야도 해당 기술을 활용하여 새로운 방향을 모색하고자 학문 간 융합이 강조되고 있다(Song, Chon, & Lee, 2020). 인공지능이란 컴퓨터 공학의 한 분야로서 컴퓨터로 하여금 인간의 학습능력, 추론능력, 지각능력 등의 지적능력을 모방하게 하는 것으로 정의할 수 있다. 이러한 인공지능을 구현하기 위해서는 양적, 질적으로 우수한 데이터의 구축 및 구축된 데이터를 적절한 알고리즘을 통해 학습시키는 과정이 선행되어야 한다. 다시 말해, 인공 지능은 컴퓨터에 지능적 업무를 이행하도록 명령하는 일종의 기술로 알고리즘을 코드화 하여 자동적 수행이 가능하도록 고안된 것이라 할 수 있다(Kang, Kang, Lee, & Sim, 2022).
이러한 인공지능을 구현하기 위해 데이터를 학습하는 방식은 다양하며, 머신러닝(machine learning, ML)과 딥러닝(deep learning, DL)이 인공지능의 대표적인 학습 방식이라 할 수 있다. 머신러닝은 알고리즘을 이용해 대량의 데이터에서 패턴을 찾아내고 예측하며, 오차를 줄여가는 능력을 갖춘 학습 방법을 의미한다. 그리고 각 학습 종류별로 유형에 따라 세부 알고리즘 모델이 존재하는데 Decision Tree (DT), Feed Forward Neural Network (FFNN), K-Means Clustering, K-Nearest Neighbors (KNN), Logistic Regression (LR), Random Forest (RF), Support Vector Machines (SVM) 등이 대표적이라 할 수 있다. 반면, 딥러닝은 머신러닝 중에서 심층신경망(deep neural networks)을 사용하는 학습 방식을 의미하며 딥러닝 알고리즘 종류에는 Artificial Neural Network (ANN), Convolutional Neural Network (CNN), Deep Neural Networks (DNN), Deep Recurrent Neural Network (DRNN), Long Short-Term Memory (LSTM), Recurrent Neural Network (RNN) 등의 모델이 있다(Jung, 2018). 이처럼, 인공지능은 머신러닝과 딥러닝을 포함하는 광범위한 개념이며, 이를 구성하는 다양한 알고리즘을 토대로 데이터의 특성 및 용도에 맞게 활용하여 데이터를 학습해 성과를 높일 수 있는 모든 기계적인 시스템을 통칭하는 것을 의미한다(Jeong, 2017; Park, 2020).
인공지능 기술의 가장 큰 장점은 구조화된 데이터를 사용할 수있는 경우, 방대한 데이터를 신속, 정확하게 수집하고 자동화할 수 있다는 점으로 이에 따라 의료 및 재활 분야에서 인공지능 기술을 도입하여 적용하려는 시도가 현재 활발히 논의 중이다. 해당 분야에서 인공지능 기술을 활용하여 얻을 수 있는 이점으로는 자원의 효율성 측면이라 할 수 있다. 인공지능을 통해 의무기록 자동화 등의 업무가 수행될 경우, 이는 한정적인 의료 및 재활 자원의 효율적인 분배로 이어질 수 있고 양질의 의료 서비스 제공에 긍정적인 효과를 가져올 수 있다. 이러한 인공지능 기술이 언어재활 현장에 적용된다면 대상자의 데이터 정보 수집 및 수동 코딩에 드는 언어재활사의 수고를 덜어주고 대상자 개별 사례 및 관련 문서의 작성에 할애되는 노력과 시간을 줄일 수 있으므로, 대상자에게 양질의 언어재활서비스를 제공하는 데 상당한 도움이 될 수 있다(Law, 2020; Liss, 2020). 또한, 대상자에 입장에서는 인공지능 기술이 적용된 다양한 보조프로그램을 시공간 제약에서 벗어나 이용할 수 있게 될것이다. 이처럼 인공지능 기술의 도입 및 적용은 기존의 언어재활서비스에 혁신적인 변화를 줄 것이라 여겨진다(Law, 2020; Liss, 2020). 뿐만 아니라, 인공지능은 관련 데이터를 분석하여 위험 징후를 조기에 파악하거나 예측할 수 있고 전문가의 진단 및 치료를 보조하는 역할을 수행할 수 있다. 의료 분야에서 인공지능 기술을 활용하여 암 등의 특정 질환을 진단하거나 병변의 조기 발견(Hosny, Parmar, Quackenbush, Schwartz, & Aerts, 2018) 및 인공지능 로봇을 활용한 재활치료(Moon & Cho, 2021) 등이 대표적 예이다.
그러나 인공지능을 활용하는 부분에 있어서 장점만 존재하는 것은 아니다. 데이터에 따른 새로운 학습과정이 매번 선행되어야 하고 이로 인한 결과치가 상이할 수 있기 때문에 지식을 통합하고 일반적 결과를 도출하는 과정이 어려울 수 있다는 문제점이 제기된다(Bhbosale, Pujari, & Multani, 2020; Kim, 2020). 또한, 인공지능은 기본적으로 인간이 원하는 질문과 답을 습득하기 때문에 데이터를 선택하는 과정에서부터 학습 과정까지 비뚤림(bias)의 문제가 존재할 수 있고 이를 통해 얻는 인공지능의 결과물 역시 해당 데이터 특성을 반영할 가능성이 있다. 따라서 공정한 데이터 수집 및 올바른 인공지능 결과의 해석이 무엇보다도 인공지능 기술을 사용하는데 중요한 사안이라고 할 수 있다(Jung, 2020; Kang et al., 2022; Oleson, Brown, & McCreery, 2019).
이러한 한계점이 존재함에도 불구하고, 인공지능은 의료 및 재활 분야를 포함하여 다양한 영역 전반에 활용될 수 있는 보편적 기술이 되어가고 있으며 언어병리학 분야 내에서도 시대적 흐름에 발맞추어 인공지능 기술을 평가 및 진단, 중재, 중재 자극 선정 등을 목적으로 활용하려는 다양한 시도가 국내외에서 나타나고 있다. 이를 구체적으로 살펴보면 우선, 실어증, 자폐스펙트럼, 단순언어 장애 장애군의 말·언어적 특성을 추출하여 평가 및 진단을 목적으로 인공지능 알고리즘을 활용한 연구들(Kanimozhiselvi & Santhiya, 2021; Qin, Lee, Kong, & Law, 2016; Wijesinghe, Samarasinghe, Seneviratne, Yogarajah, & Pulasinghe, 2019)이 있다. 또한 인공지능이 탑재된 웨어러블(wearable) 디바이스를 이용하여 자폐 스펙트럼 아동의 사회적 의사소통 기술 향상(Voss et al., 2019) 및 상호작용 상황에서의 눈 맞춤, 발성빈도 증진(Melo et al., 2019), 청각장애 성인의 말명료도 증진(Zhao, Wang, Johnson, & Healy, 2018), 건청 자녀를 둔 청각장애 부모를 대상으로 인공지능 스피커(카카오 미니)를 활용하여 부모교육을 실시한 후 아동의 이야기 문법, 이야기 이해의 수행력 향상을 보고한(Kim & Yim, 2021) 중재연구들도 있다. 나아가, 신경언어장애군의 동사 중재 자극의 개발을 목적으로 한국어 특징을 빅데이터 기반으로 분석한 연구(Park, Lim, & Sung, 2019) 및 딥러닝-워드 임베딩(word embedding) 기법을 활용하여 비유창성의 위치와 분포 특성을 파악하고 이를 유창성장애 치료에의 활용을 목표로 한 연구(Song et al., 2020)가 있다. 이처럼 언어병리학 분야에서 역시 인공지능 기술을 활용하고자 하는 노력이 활발히 진행중임을 알 수 있다.
융합 연구의 중요성이 강조되고 그 개념 및 범위가 확대되고 있는 현 시점에서, 최근 수행된 언어병리학 분야 인공지능 연구를 종합 분석하는 것은 지속적인 학문적, 임상적 발전을 위해 매우 중요한 의의를 지닌다(de la Fuente Garcia, Ritchie, & Luz, 2020). 특히, 평가 및 진단 과정은 특정 장애의 유무를 판단하는 임상적 행위로서 치료의 방향성 결정 및 중재와 밀접한 연관을 가지고 있기 때문에(Sim et al., 2019), 인공지능 기술이 각 장애에 적합한 특성을 추출, 분석하여 평가 및 진단을 도울 수 있다면, 언어재활사의 의사결정 능력을 지원하고 향상시켜 주는 수단이 될 수 있을 것이다. 더불어, 이러한 인공지능을 기반으로 한 평가 및 진단 시스템은 객관성, 시간적 효율성 및 결과의 모호함에 대한 새로운 기준이나 특성에 대한 지식을 더해줄 수 있을 것으로 사료된다.
그러나, 국내의 경우 의사소통장애 분야에서의 인공지능 연구가 제한적이며, 특히 평가 및 진단과 관련된 연구는 전무하여 인공지능 활용과 관련된 특성 및 수행력에 대한 고찰이 어렵다. 국외의 경우 역시 아직 말·언어장애 평가 및 진단과 관련된 인공지능 활용에 대한 종합적인 고찰이 부족한 실정이다. 따라서 본 연구에서는 체계적 문헌고찰 수행 방법에 따라 국외에서 최근 5년(2016년-2021년 8월까지) 간 의사소통장애 분야 내 평가 및 진단을 목적으로 인공 지능 기술을 활용한 연구를 조사하여, 일반적, 방법론적 특성 및 인공지능 수행력을 분석하고자 하였다. 또한 이를 통해 관련연구 동향의 전반적 흐름을 파악하고, 향후 실제 임상현장에서 인공지능이 활용되기 위해 선행되어야 할 고려사항 및 방향성에 대한 정보를 제공하고자 한다.
연구방법
연구설계
본 연구는 의사소통장애 분야의 평가 및 진단을 위해 활용되는 인공지능 기술을 활용한 연구의 특성 및 수행력을 분석하고자 실시된 체계적 문헌고찰 연구이다. 본 연구에서 다룰 의사소통장애 분야의 평가 및 진단에 포함되는 요소는 선행 연구(Khanagar et al., 2021)의 기준을 참고하여 말 · 언어 문제의 평가, 진단, 예후, 중증도 및 하위 유형 분류로 선정하였다. 연구 수행의 전 과정은 PRISMA(Preferred Reporting Items of Systematic Reviews and Meta Analysis)의 체계적 문헌고찰에 관한 보고 지침에 준거하여 수행되었다(Moher, Liberati, Tetzlaff, Altman, & PRISMA Group, 2009). 본 연구에서는 논문의 객관성 확보를 위해 문헌선택 흐름도(PRISMA flowchart)에 입각하여 문헌검색이 수행되었고 연구자 간 의견이 상이할 경우, 논의를 거쳐 수정 및 보완하였다.
핵심질문
본 연구를 수행하기 위한 핵심 질문 구성요소(Population, Intervention, Comparison, Outcome; PICO)를 살펴보면 다음과 같다(Eriksen & Frandsen, 2018). 연구 대상자(population)는 의사소통장애 대상자, 대상자의 말·언어 정보가 포함된 데이터베이스(database)이고, 중재법(intervention)은 의사소통장애 평가, 진단, 예후, 중증도 및 하위 유형 분류를 위해 사용된 인공지능 기반 알고리즘 모델(AI-based algorithms models), 추출된 특성(feature) 및 분석 파라미터(parameter)이다. 대조군(comparison)은 통상적으로 사용되는 임상학적 진단 도구 및 전문가 데이터(data)이며, 진단에 대한 유효성(outcome)은 인공지능 알고리즘 기반 모델의 수행력(performance)이었다. PICO 전략에 대한 구성 요소 설명은 Table 1에 제시하였다.

Description of the PICO (P=Population, I=Intervention, C=Comparison, O=Outcome) elements (Eriksen & Frandsen, 2018)
자료검색, 수집 및 선별 절차
자료검색
언어병리학 분야의 인공지능 관련 연구는 비교적 새로운 분야로 최근 몇 년 이내 시작된 프로젝트 및 연구들이 많기 때문에, 2021년 8월을 기준으로 최근 5년 이내 발간된 논문으로 게재 연도에 제한을 두었다. 또한, 예비조사 결과, 국내의 경우 관련 연구가 전무하여 본 연구에서는 국외 문헌만을 대상으로 하였다. 검색 전략을 선정하기 위해 2021년 8월 20일 PubMed 데이터베이스에서 언어병리학의 의학주제표목(medical subject headings, MeSH)인 “speech language pathology” AND “AI OR artificial intelligence”를 키워드로 사용하여 간략 검색을 실시하였다. 이후, 검색된 문헌을 토대로 PICO 전략을 확인하고 검색어를 설정하였으며, 검색 데이터베이스 내 고급 검색 기능을 참고하여 “artificial intelligence”, “AI”, “deep learning”, “machine learning”, “big data”, “speech language pathology”의 각 분야 및 의사소통장애 진단명을 중심으로 검색식을 조합하였다. 검색 시, 문헌 누락을 최소화하기 위해 포괄적인 검색식을 사용하였다. 이후 수기로 PICO 전략, 배제 및 선정조건과 관련이 없는 문헌의 경우 분석대상에서 제외하였다. 데이터베이스는 국외데이터 베이스인 CINAHL, Academic Search Complete, Google Scholar, PubMed, Science Direct, Web of Science를 사용하였으며 분석대상 문헌선정을 위한 최종 검색은 2021년 9월2일에 수행하였다.
자료수집 및 선별
문헌의 선정기준은 (1) 의사소통장애를 다루고 있는 연구 (2) 말 · 언어적 특성 및 관련 지표(metrics)를 통해 의사소통장애 평가, 진단, 예후, 중증도 및 하위 유형 분류에 인공지능 기술을 적용한 연구를 포함하였다.
배제기준은 (1) 영어로 출간되지 않은 연구 (2) 전문제공(full-text) 및 peer review가 아닌 연구 (3) 회색문헌(dissertation, proceeding) 및 종설(review) (4) 중재연구 (5) 유전자 특성을 적용한 연구 (6) 인공지능 기반 알고리즘 모델의 성능을 단순 비교하는 연구는 제외하였다.
본 연구는 핵심질문과 선정 및 배제기준에 따라 문헌을 선정하였고, PRISMA (Preferred Reporting Items of Systematic Reviews and Meta Analysis) 흐름도를 사용하여 단계별로 문헌선택 과정을 기술하였다(Figure 1). 6개의 데이터 베이스에서 총 319편의 문헌이 검색되었고 수기검색으로 9편의 논문이 추가되어, 총 328편의 문헌이 확인되었다. 이후, 문헌 관리 프로그램(EndNote 20)을 이용하여 검색된 문헌들의 리스트를 만들고 수기와 병행하여 중복 문헌을 배제한 후, 총 175편의 문헌을 제목과 초록을 기반으로 검토하였다. 초록만으로 문헌의 적절성에 대한 여부를 확인할 수 없는 경우 전문(full-text)을 찾아 확인하였다. 기준에 부합하지 않는 총 123편을 제외하고 선정된 52편의 문헌을 원문을 위주로 검토한 결과, 총 34편의 문헌이 제외되어 최종적으로 18편의 문헌이 분석 문헌으로 선택되었다. 전체 연구자가 논의를 통해 검색어, 핵심질문과 선정 및 배제기준을 결정하였고 이를 바탕으로 연구자 1과 2가 문헌검색 및 중복 문헌의 배제 작업을 실시하였다. 이후 연구자 모두 제목 및 초록을 기반으로 검토하였으며 배제된 문헌에 대해 사유를 기술하였고 의견 불일치가 있을 경우 전체 연구자가 함께 논의하여 최종 문헌선택 여부를 결정하였다. 참여한 연구자 중 1인은 언어병리학 박사과정 및 1급 언어재활사 자격증을 소지한 연구자이며 다른 연구자 1인은 언어병리학 박사학위 및 1급 언어재활사 자격증을 소지한 임상경력 15년 이상의 연구자이다. 이 외 연구자 2인은 언어병리학 전공 교수이다.
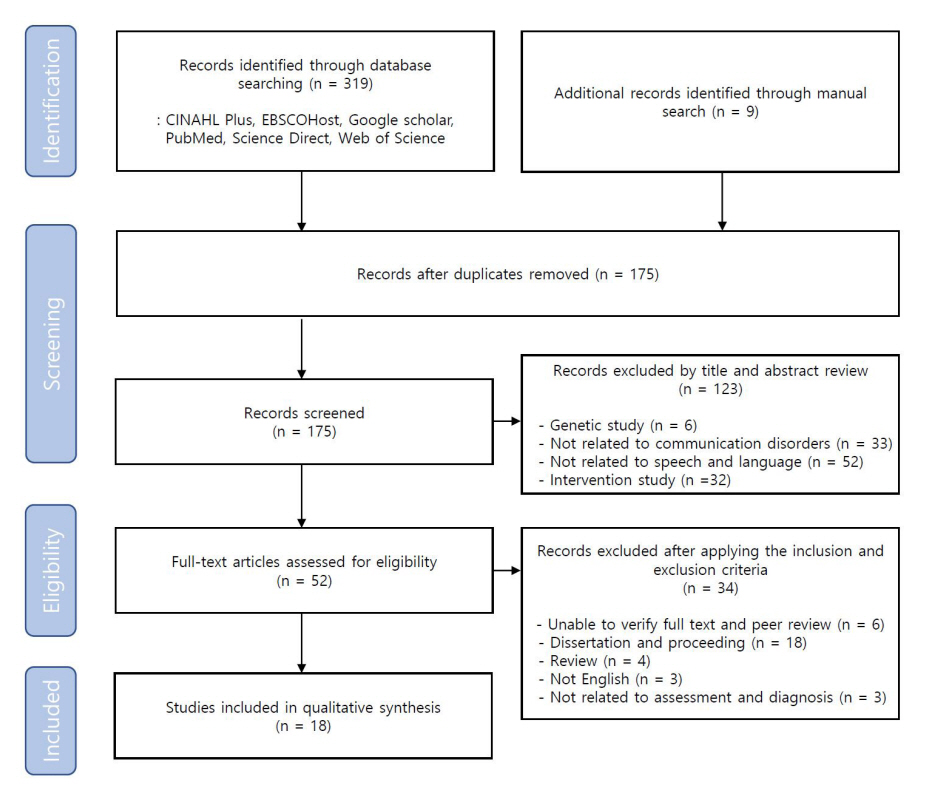
PRISMA flow chart of study selection process.
문헌의 질 평가
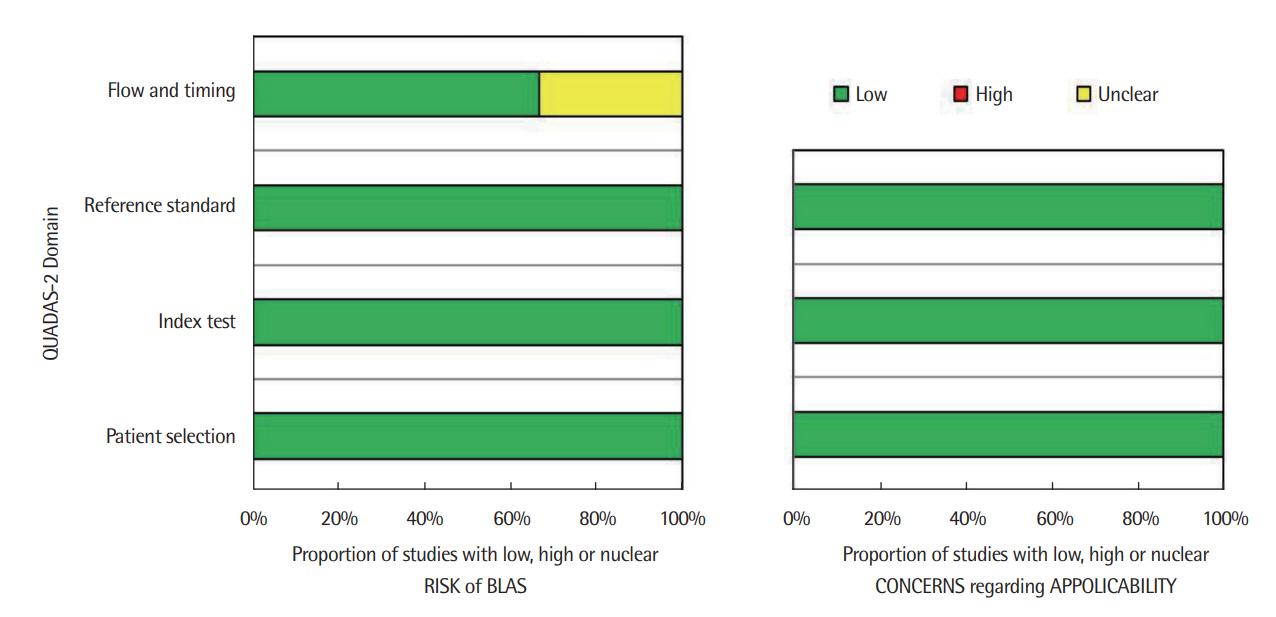
본 연구에서는 선정된 18편의 문헌에 대해 ‘QUADAS-II (Quality Assessment of Diagnostic Accuracy Studies-II)’도구를 사용하여 질 평가를 실시하였다(Whiting et al., 2011). QUADAS-II (www.quadas.org)는 체계적 문헌고찰 연구에서 평가 및 진단 연구에 대한 질 평가 도구로 ‘비뚤림의 위험(risk of bias)’과 ‘적용 가능성(applicability)’을 평가한다. 비뚤림이란 연구설계, 수행, 분석 과정에서 부적절하게 추정된 결과가 참값으로부터 벗어나 왜곡되는 것을 의미하며 연구설계에 따라 비뚤림 위험 평가 도구를 선택하여 최종 선정된 개별 문헌의 비뚤림 위험 정도를 평가할 수 있다(Kim et al., 2011). 본 연구에서 선정한 평가 도구인 QUADAS-II에서의 평가 항목은 연구 대상자 선택(patient selection), 진단검사 (index test), 참조표준검사(reference standard), 연구진행 과정 및 적시성(flow and timing)의 4가지 영역으로 구성되며 평가 항목에 따라 ‘예(yes), 아니요(no), 불확실(unclear)’로 평가하게 되고 최종적으로 비뚤림의 위험 및 적용 가능성의 평가 결과는 위험이 높음(high), 낮음 (low), 불확실(unclear)로 기술된다. 문헌의 질은 저자들에 의해 독립적으로 평가되었고 결과가 상이할 경우 논의를 통해 최종적으로 결정하였다.
신뢰도 확인
The Assessment of Multiple Systematic Reviews (AMSTAR)의 가이드라인에서는 체계적인 자료 추출 및 분석대상 논문 선정 과정에서 연구자의 주관적 판단을 최소화하고 연구결과의 신뢰도를 높이기 위해 저자 2명 이상이 논문 선정 및 코딩에 참여할 것을 권고하고 있다(Lee, Park, & Lee, 2021; Seo & Moon, 2017; Shea et al., 2009). 본 연구에서는 분석 신뢰도를 위해 연구자 1과 연구자 2 총 2명이 문헌에 대한 세부 변수 코딩을 독립적으로 실시하였고 분석 결과에 대한 일치도는 94.74% 였다.
자료분석
본 연구의 자료분석은 정성적 분석(qualitative analysis) 방법을 적용하여 실시하였다. 분석에 포함된 문헌의 인공지능 알고리즘 수행력(performance) 및 출판 비뚤림 정도에 기초한 메타분석을 실시하려 하였으나, 개별 연구에 따른 연구설계, 연구결과 보고 및 관련지표가 상이하여 시행하지 않았다. 그러나 의사소통장애 분야의 평가 및 진단을 위해 활용되는 인공지능기반 알고리즘의 방법론적 특성 및 수행력을 타당하게 고찰하고자 선행 연구(de la Fuente Garcia et al., 2020; Dhillon et al., 2021; Lee et al., 2021)의 분석방법 및 변인을 참고하였고 본 연구에 맞게 추가 및 재구성하여 분석틀을 마련하였다.
선행 연구를 통해 참고한 변인에 대해 구체적으로 살펴보자면, Lee 등(2021)에서는 논문의 저자, 출판 년도, 대상자, 연구설계, Dhillon 등(2021)에서는 활용된 인공지능 알고리즘, de la Fuente Garcia 등(2020)에서는 인공지능 알고리즘 수행력과 관련된 변인들을 참고하였다. 이밖에 저자정보, 추출된 특성(feature) 및 분석 파라미터(parameter)의 변인은 새롭게 추가하여 분석하였다. 이에 따라 본 연구에서는 논문의 저자, 출판 년도, 대상자, 연구설계, 저자정보, 인공지능 알고리즘 모델, 추출된 특성, 분석 파라미터 및 인공지능 알고리즘 수행력을 변인으로 최종적으로 분석하였다.
각 변인들에 대해 구체적으로 살펴보자면, 먼저 대상자의 경우, 의사소통장애 유형 및 연령으로 구분하여 분석하였고, 연구설계의 경우, 실험연구, 개발 및 실험연구로 구분하여 분석하였다. 저자 정보의 경우, 주저자와 공동저자를 구분하여 해당 저자의 전문분야 영역을 분석하였고 인공지능 알고리즘 모델은 머신러닝 알고리즘, 딥러닝 알고리즘, 머신러닝과 딥러닝 알고리즘을 함께 활용하는 경우의 유형을 중심으로 분석하였다. 추출된 특성 및 분석 파라미터의 경우, 의사소통장애의 평가 및 진단을 위해 추출된 변인으로 추출된 특성의 분류 기준은 선행 연구(de la Fuente Garcia et al., 2020; Voleti, Liss, & Berisha, 2019)의 기준을 참고하여 관련 특성, 하위 범주(subcategory) 및 유형(type)별로 분석하였다. 또한, 분석 파라미터의 경우, 과제 유형(task type)별 수준(level)에 따라 분석하였으며 과제 유형의 경우 역시 de la Fuente Garcia 등(2020)의 기준을 참고하여 분류하였다. 마지막으로, 인공지능 알고리즘 수행력은 측정 관련 지표의 수치 및 유의수준을 바탕으로 분석하였다. 분석 내용 및 코딩에 관한 세부 사항은 Table 2에 제시하였다. 자료 추출은 문헌에 기술된 일반적인 특성, 방법론적인 내용 및 수행력 지표와 관련된 자료를 추출하였고, 분류가 명확하지 않은 경우, 연구자 논의를 통하여 최종적인 합의과정을 도출하고 결정하였다.
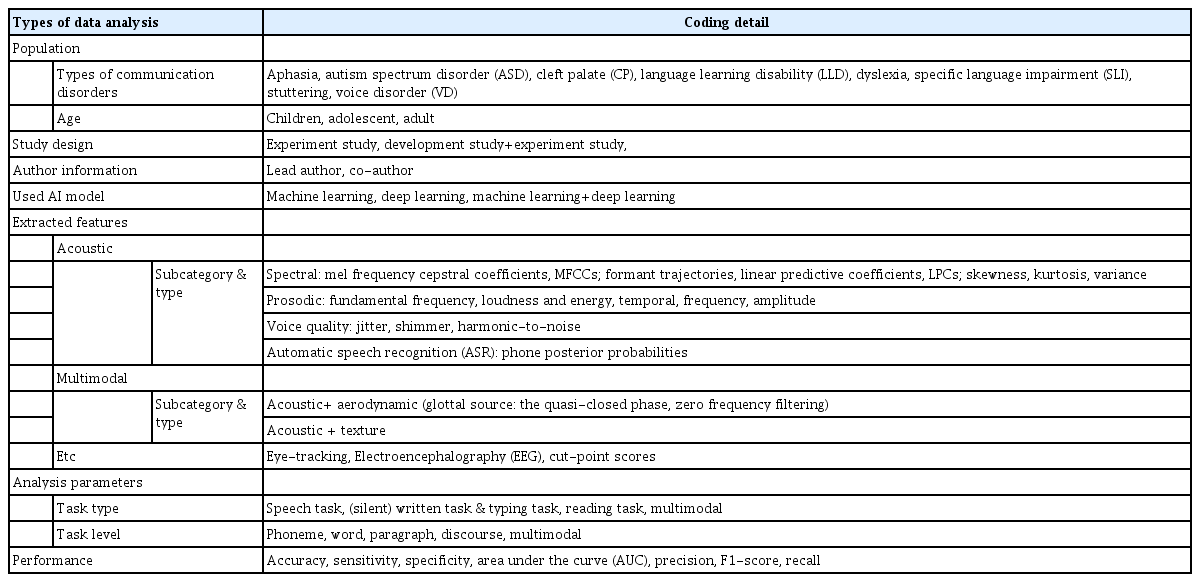
Frame and coding data for analysis
연구결과
분석대상 문헌의 일반적 특성
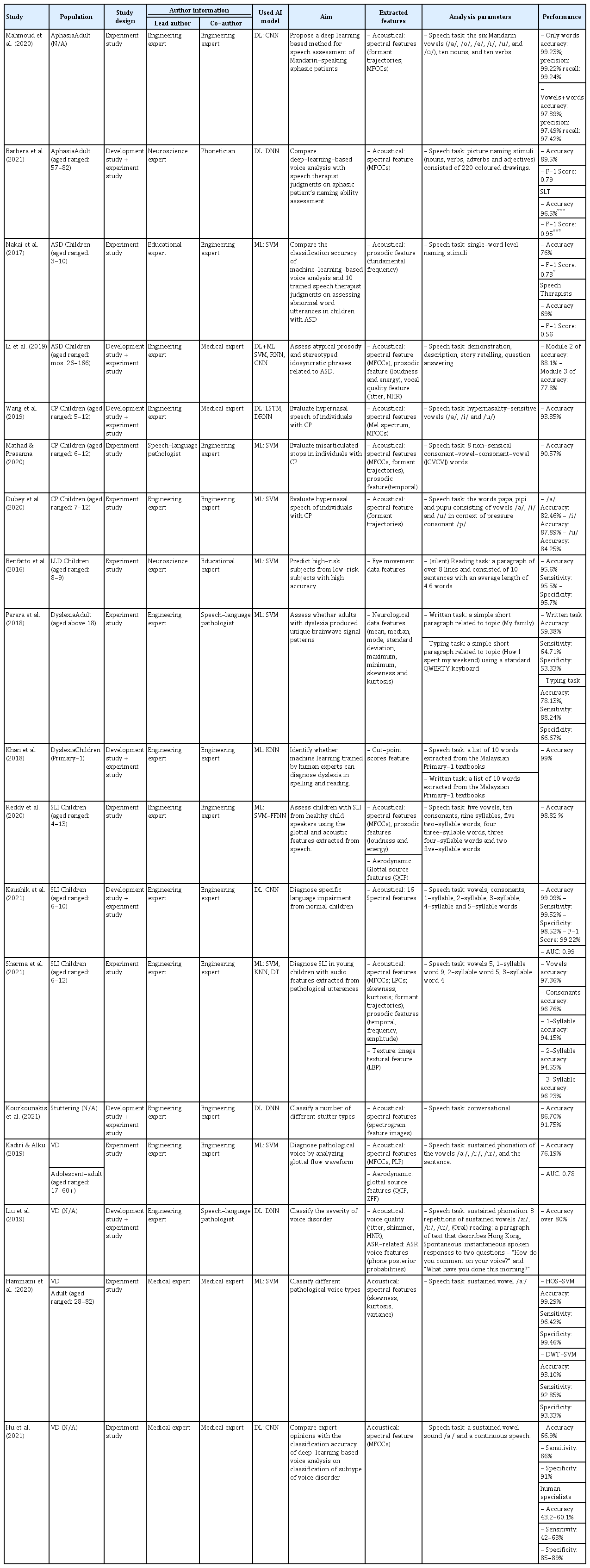
인공지능 기반 알고리즘을 활용하여 의사소통장애 분야의 평가, 진단, 예후, 중증도 및 하위 유형 분류를 위해 최종 선택된 문헌은 총 18편으로, 선정된 문헌에 대한 구체적인 내용은 Appendix 1 에 제시하였다. 연구 현황을 살펴보면 선택된 문헌 중 2016년과 2017년의 경우 각 1편(5.6%), 2018년은 2편(11.1%), 2019년은 4편(22.2%), 2020년은 5편(27.8%)이 게재되었다. 2021년의 경우 1월부터 8월까지 게재된 문헌은 5편(27.8%)으로 최근 5년간 매년 평균 3.6편이 학술지에 출판되었다. 연구대상의 의사소통장애 유형으로는 음성장애를 대상으로 한 문헌이 4편(22.2%), 구개열 대상 3편(16.7%), 언어학습장애 및 난독증 3편(16.7%), 단순언어장애 3편(16.7%), 실어증 2편(11.1%), 자폐스펙트럼장애 2편(11.1%), 유창성 장애 1편(5.6%) 이었다. 연구대상의 연령대를 살펴보면 아동(만 2세-만 13세), 청소년(만 14세-만 17세), 성인(만 18세 이후)을 기준으로 아동 대상 10편(55.6%), 성인 대상 4편(22.2%), 청소년과 성인 대상 1편(5.6%), 정확한 연령대가 기재 되어있지 않는 문헌이 3편(16.7%)이었다. 연구설계별로는 기존의 인공지능 기반 알고리즘을 활용한 실험연구 11편(61.1%), 평가, 진단, 예후, 중증도 및 하위 유형 분류 관련 알고리즘 기술 개발과 이것의 효과성을 입증하는 개발 및 실험연구 7편(38.9%)이었다. 선택된 18편의 저자정보를 추가적으로 분석한 결과 주저자의 경우, 컴퓨터 및 전기 전자 계열 등의 공학 계열 전문가(66.7%)가 연구를 주도하였고 이외 신경과학(11.1%), 의학계열(11.1%), 교육계열(5.6%), 언어병리학 전문가(5.6%)순이었다. 공동저자의 경우 역시, 공학계열의 전문가가 전체 중 가장 많은 비중을 차지하고 있었고(55.6%) 언어병리학 전문가는 각 연구에서 1명 내지는 포함되지 않는 경우가 대부분이었다(Figure 2). AI 알고리즘 모델로는 머신러닝 알고리즘 모델 DT, FFNN, KNN, SVM을 활용한 문헌 10편(55.6%), 딥러닝 알고리즘 모델 CNN, DNN, DRNN, LSTM을 활용한 문헌 7편(38.9%), 머신러닝 알고리즘 모델 SVM과 딥러닝 알고리즘 모델 CNN, RNN을 함께 활용한 문헌 1편(5.6%)이었다(Appendix 1).
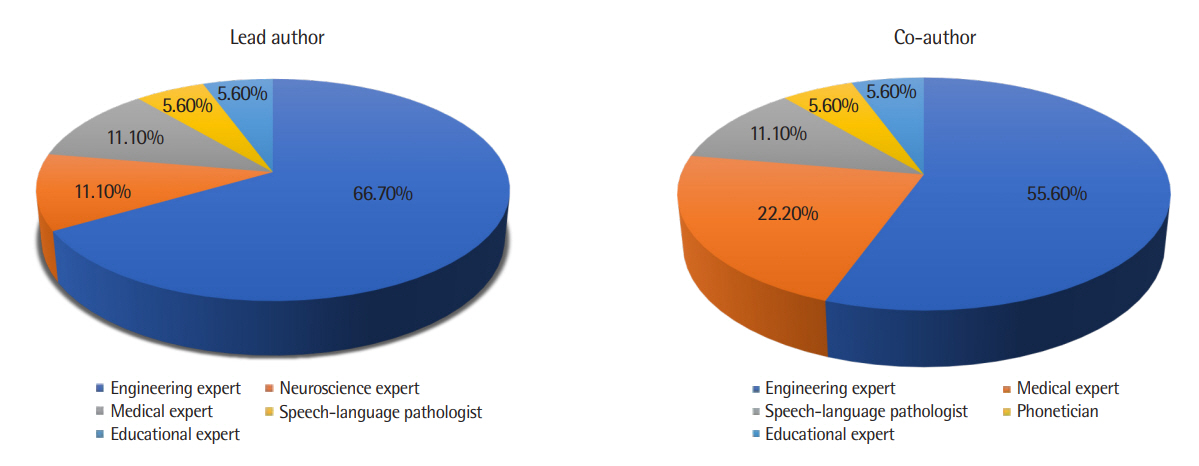
Comparison of specialties by author.
문헌의 질에 관한 평가 결과
본 연구에서 최종 선택된 분석대상 문헌의 질을 평가한 결과, 18편 모두 연구 대상자 선택, 진단검사, 참조표준검사 영역에 대한 비뚤림의 위험 및 적용 가능성에 대한 문제가 낮은 것으로 평가되었다. 분석대상 문헌 모두 대상자의 말·언어 관련 샘플이 분석대상에 포함된 경우, 연구 대상자 선택 영역에서 낮은 비뚤림을 보고하였고 표본집단을 선정한 경우, 전향적, 무작위 선정 및 부적절하게 배제되는 경우가 없었기 때문에, 연구 대상자 선택 영역에서의 비뚤림의 위험이 낮은 것으로 평가되었다. 또한, 전문가에 의해 구축된 기준 및 규준에 따라 참조표준기준이 설정되고 인공지능 기반 알고리즘의 새로운 방법으로 진단검사 기준을 설정하였기 때문에, 선택된 18편 문헌 모두 해당 검사나 참조표준 기준에 따른 비뚤림의 위험이나 적용 가능성의 문제도 낮았다. 18편 중에서 모든 대상군을 분석대상으로 포함하고 동일한 참조표준 기준을 적용하여 진단검사와 참조표준검사 간 시행간격의 적절성을 보고한 문헌은 12편 (Barbera et al., 2021; Benfatto et al., 2016; Dubey, Prasanna, & Dandapat, 2020; Khan, Cheng, & Bee, 2018; Li et al., 2019; Liu, Lee, Law, & Lee, 2019; Mahmoud et al., 2020; Mathad & Prasanna, 2020; Nakai, Takiguchi, Matsui, Yamaoka, & Takada, 2017; Perera, Shiratuddin, Wong, & Fullarton, 2018; Sharma, Zhang, Umapathy, & Krishnan, 2021; Wang et al., 2019)이였으나, 참조표준 기준을 적용한 검사와 진단검사 시행이 독립적으로 이루어졌는지, 두 검사 간 시행 간격에 대한 기술이 명확하지 않은 문헌이 6편(Hammami, Salhi, & Labidi, 2020; Hu, Chang, Wang, Li, & Cho, 2021; Kadiri & Alku, 2019; Kaushik, Baghel, Burget, Travieso, & Dutta, 2021; Kourkounakis, Hajavi , & Etemad, 2021; Reddy, Alku, & Rao, 2020)으로 해당 문헌의 연구진행 과정 및 적시성 영역에 대한 비뚤림의 위험이 불확실한 것으로 평가되었다(Figure 3).
Cumulative bar plot of bias risk and applicability concerns across all studies.
인공지능 기반 알고리즘 활용의 방법론적 특성
인공지능 기반 알고리즘 활용에 대한 방법론적 특성은 의사소통장애 분야의 평가, 진단, 예후, 중증도 및 하위 유형 분류를 위해 추출된 특성 및 분석 파라미터를 중심으로 살펴보았다. 추출된 특성 중 음향학적(acoustic), 공기역학적(aerodynamic) 특성의 경우는 하위 범주 및 유형으로 나누어 살펴보았으며, 2개 이상의 하위 범주 및 유형에 해당될 경우 독립된 논문으로 분석하였다. 분석 파라미터의 경우 과제 유형 및 수준에 따라 살펴보았다.
추출된 특성을 중심으로 살펴본 결과, 평가 및 진단에 음향학적 특성을 활용한 문헌이 12편(66.7%), 복합적(multimodal) 특성을 활용한 문헌이 3편(16.7%)이었다. 복합적 특성 중 음향학적 특성과 공기역학적 특성을 활용한 문헌이 2편(예: Kadiri & Alku, 2019; Reddy et al., 2020), 음향학적 특성과 이미지(image) 데이터의 질감 (texture) 특성(local binary pattern, LBP)을 활용한 문헌이 1편(예: Sharma et al., 2021)이었다. 기타 특성으로 시선추적(eye-tracking), 뇌전도(electroencephalography, EEG), cut-point scores 데이터 특성을 활용한 문헌이 각 1편(예: Benfatto et al., 2016; Perera et al., 2018; Khan et al., 2018)으로 총 3편(16.7%)이었다. 이중 추출된 음향학적 특성, 공기역학적 특성을 하위 범주 및 유형으로 나누어 살펴본 결과, 음향학적 특성의 경우, 스펙트럼(spectral) 특성(mel frequency cepstral coefficients, MFCCs; formant trajectories, linear predictive coefficients, LPCs; skewness, kurtosis, variance)을 활용한 문헌은 13편(예: Barbera et al., 2021; Dubey et al., 2020; Hammami et al., 2020; Hu et al., 2021; Kadiri & Alku, 2019; Kaushik et al., 2021; Kourkounakis et al., 2021; Li et al., 2019; Mathad & Prasanna, 2020; Reddy et al., 2020; Sharma et al., 2021; Mahmoud et al., 2020; Wang et al., 2019), 운율적(prosodic) 특성(fundamental frequency, loudness and energy, temporal, frequency, amplitude)을 활용한 문헌은 5편(예: Li et al., 2019; Mathad & Prasanna, 2020; Nakai et al., 2017; Reddy et al., 2020; Sharma et al., 2021), 음성의 질(voice quality) 특성(jitter, shimmer, harmonic-to-noise)을 활용한 문헌은 1편(예: Liu et al., 2019), 자동 음성 인식(automatic speech recognition, ASR) 기술 내 음성특징(phone posterior probabilities)을 활용한 문헌은 1편(예: Liu et al., 2019)이었다. 공기역학적 특성의 경우, 성문(glottal source) 특성(the quasi-closed phase, zero frequency filtering)을 활용한 문헌은 2편(예: Kadiri & Alku, 2019; Reddy et al., 2020)이었다(Figure 4, Appendix 1).

Types of extracted features.
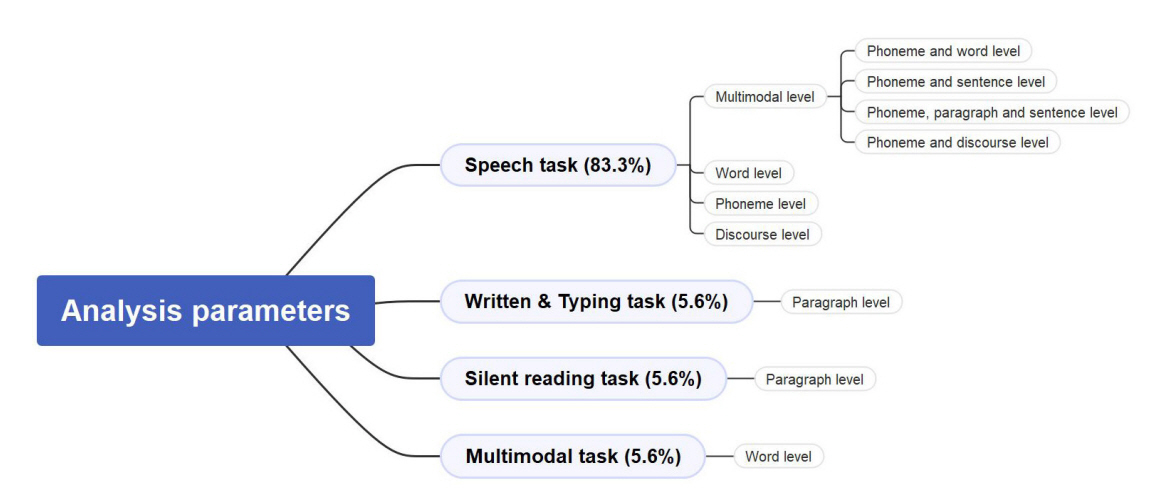
분석 파라미터를 중심으로 살펴본 결과, 말하기(speech) 과제는 15편(83.3%)으로 복합적 수준에서 분석이 이루어진 문헌이 7편(예: Hu et al., 2021; Kadiri & Alku, 2019; Kaushik et al., 2021; Liu et al., 2019; Mahmoud et al., 2020; Reddy et al., 2020; Sharma et al., 2021), 단어(word) 수준 4편(예: Barbera et al., 2021; Dubey et al., 2020; Khan et al., 2018; Nakai et al., 2017), 음소(phoneme) 수준 2편(예: Hammami et al., 2020; Wang et al., 2019), 담화(discourse) 수준이 2편(예: Kourkounakis et al., 2021; Li et al., 2019)으로 나타났다. 복합적 수준을 구체적으로 살펴보면, 음소 및 단어 수준에서의 분석은 4편(예: Kaushik et al., 2021; Mahmoud et al., 2020; Reddy et al., 2020; Sharma et al., 2021), 음소 및 문장(sentence) 수준 1편(예: Kadiri & Alku, 2019), 음소, 단락(paragraph) 및 담화 수준 1편(예: Liu et al., 2019), 음소 및 담화 수준이 1편(예: Hu et al., 2021)이었다. 쓰기(written) 과제 및 타이핑(typing) 과제, 읽기(silent reading) 과제의 경우 각 1편(5.6%)으로 모두 단락 수준에서 분석이 이루어졌으며 쓰기 과제와 말하기 과제를 동시에 살펴본 복합 과제의 경우는 1편(5.6%)으로 단어 수준에서 분석이 이루어졌다(Figure 5, Appendix 1).
Task types and levels used as analysis parameters.
인공지능 기반 알고리즘의 수행력(performance) 결과
의사소통장애 분야의 인공지능 기반 알고리즘에 대한 수행력은그 목적에 따라 평가 및 진단, 예후, 중증도 및 하위 유형 분류, 전문가와의 비교로 구분하여 분석하였다. 수행력 지표는 정확도(accuracy), 민감도(sensitivity), 특이도(specificity), 곡선하면적(area under the curve, AUC), 정밀도(precision), F1-score, 재현율(recall)이었다.
평가 및 진단을 목적으로 인공지능 기반 알고리즘의 수행력을 보고한 문헌은 11편(61.1%; 예: Dubey et al., 2020; Kadiri & Alku, 2019; Kaushik et al., 2021; Khan et al., 2018; Li et al., 2019; Mahmoud et al., 2020; Mathad & Prasanna, 2020; Perera et al., 2018; Reddy et al., 2020; Sharma et al., 2021; Wang et al., 2019)으로 개별 연구의 정확도 범위는 59.38%-99.23%이었다. 11편 중 2편에서 보고하였던 민감도 범위는 64.71%-99.52%(예: Perera et al., 2018; Kaushik et al., 2021), 특이도 범위는 53.33%-98.52%(예: Kaushik et al., 2021; Perera et al., 2018), 곡선하면적 범위는 .78-.99(예: Kadiri & Alku, 2019; Kaushik et al., 2021)이었다. 또한, 11편 중 1편에서 보고하였던 정밀도 범위는 97.49%-99.22%(예: Mahmoud et al., 2020), F1-score는 99.22%(예: Kaushik et al., 2021), 재현율 범위는 97.42%-99.24%(예: Mahmoud et al., 2020)이었다. 예후를 목적으로 한 문헌은 1편(5.6%; 예: Benfatto et al., 2016)으로 정확도는 95.6%, 민감도는 95.5%, 특이도는 95.7%이었다. 중증도 및 하위 유형 분류를 목적으로 한 문헌은 3편(16.7%; 예: Hammami et al., 2020; Kourkounakis et al., 2021; Liu et al., 2019)으로 개별연구의 정확도 범위는 80%-99.29%이었다. 3편 중 1편(예: Hammami et al., 2020)에서 보고한 민감도 범위는 92.85%-96.42%, 특이도 범위는 93.33%-99.46%이었다. 전문가와의 비교를 통해 인공지능 기반 알고리즘의 수행력을 보고한 문헌은 3편(16.7%; 예: Barbera et al., 2021; Hu et al., 2021; Nakai et al., 2017)이었다. 세부적으로 보면 평가 및 진단에 대해 전문가와의 수행력 비교를 목적으로 한 문헌 2편(예: Barbera et al., 2021; Nakai et al., 2017), 하위 유형 분류에 대해 전문가와의 수행력 비교를 목적으로 한 문헌 1편(예: Hu et al., 2021)이었다. 개별연구 수행력을 살펴보면, 평가 및 진단에 대해 전문가와의 수행력 비교를 목적으로 한 문헌 2편의 경우, Nakai 등(2017)에서는 인공지능 기반 알고리즘과 전문가의 수행력의 정확도는 각각 76%, 69%, F1-score는 .73, .56으로 정확도에서는 인공지능 기반 알고리즘의 수행력과 전문가의 수행력 간 유의한 차이가 나타나지 않았으나(p=3.16), F1-score는 인공지능 기반 알고리즘의 수행력이 전문가의 수행력 보다 유의하게 높았다(p>.05). Barbera 등(2021)에서는 인공지능 기반 알고리즘과 전문가의 수행력은 각각 정확도는 89.5%, 96.5%, F1-score는 .79, .95로 전문가의 수행력이 인공지능 기반 알고리즘 수행력 보다 유의하게 더 높았다(p<.001). 하위 유형 분류에 대해 전문가와의 수행력 비교를 목적으로 한 문헌(예: Hu et al., 2021)의 경우, 인공지능 기반 알고리즘과 전문가 수행력은 각각 정확도 범위는 66.9%, 43.2%-60.1%, 민감도 범위는 66%, 42%-63%, 특이도 범위는 91%, 85%-89%이었다(Appendix 1).
논의 및 결론
본 연구는 의사소통장애 분야에서 평가 및 진단에 활용되고 있는 인공지능 기반 알고리즘의 방법론적 특성과 수행력을 확인하기 위해 체계적 문헌고찰을 수행하였다. 최근 5년간 국외 학술지에 출판된 인공지능 알고리즘을 통해 말·언어 장애의 평가, 진단, 예후 및 중증도 및 하위 유형 분류 수행력을 보고한 문헌 18편의 데이터를 추출하여 인공지능 활용 문헌의 일반적 특성, 문헌의 질 평가, 방법론적 특성 및 수행력을 분석하였다. 본 연구의 결과를 바탕으로 한 논의 및 결론은 다음과 같다.
선택된 18편 문헌의 일반적 특성을 살펴보면, 연구현황의 경우, 2016년과 2017년도에는 각 1편씩 게재되었으나 2018년부터 매년 증가하는 추세를 보이고 있었다. 최근 5년 간 매년 평균 3.6편이 출판되고 있음을 고려하면, 의사소통장애 분야에 있어서 평가 및 진단을 위해 인공지능 알고리즘을 활용한 시도가 지속적으로 논의되고 있음을 알 수 있다. 연구대상의 의사소통장애 유형을 살펴보면, 다양한 장애군이 포함되어 있었으나 이중 음성장애가 22.2%로 많은 비중을 차지하고 있었다. 이는 의사소통장애 분야에서 인공지능 알고리즘을 활용하여 평가, 진단 및 하위 유형 분류 시, 음향학적 특성(예: 스펙트럼, 운율, 음성의 질 등)을 활용하려는 시도가 활발히 이루어지고 있음을 내포하는 결과라 할 수 있다. 실제 분석대상 문헌 18편에서 추출된 특성은 상당수(66.7%)가 음향학적 특성이 었으며 음성장애 대상군 역시 해당 특성을 토대로 평가, 진단 및 하위 유형 분류에 활용하고자 하는 결과가 반영된 것이라 할 수 있다. 연구대상의 연령대의 경우, 아동 대상 10편(55.6%)으로 전체 연구의 과반수를 차지하고 있었는데 이는 평가 및 진단 시기와 관련한 중요성을 반영하는 결과라 할 수 있겠다. 다수의 선행 연구(Kaur et al., 2006; Preston & Edwards, 2010; Ward, 1999)에서 언급되었듯이, 전생애적 발달에 지대한 영향을 미치는 시기의 조기 발견(early detection)은 조기 중재(early intervention)로 이어질 수 있고 개입이 빠를수록 아동의 이후 언어, 정서, 행동 및 학업 발달 등에 있어 긍정적 예후를 예측할 수 있기 때문에 이는 조기 진단의 필요성이 반영된 결과라 할 수 있다. 연구설계를 살펴보면, 개발보고를 비롯한 개발된 기술의 효과성을 입증하는 실험연구가 분석대상 문헌의 다수를 차지하고 있었다. 실제로 문헌 18편의 저자 정보를 추가적으로 분석한 결과, 주저자 및 공동저자의 경우, 컴퓨터 및 전기 전자 계열 등의 공학 계열 전문가가 연구를 주도하였으며 언어병리학 전문가는 각 연구에서 1명 내지는 포함되지 않는 경우가 대부분이었다. 즉, 언어병리학 전문가의 저조한 참여 및 부재로 인해 특정 장애군을 평가 및 진단하는 과정에 있어 구체적이고 보다 적합한 진단법인지에 대해 밝혀 내기 위한 증거기반 자료로 활용하는 부분에 있어서는 주의를 기울여야 할 필요성이 있다고 보여 진다. 그러나 향후 의사소통장애분야의 인공지능 관련 연구에서 언어병리학 전문가의 적극적이고 주도적인 참여가 이루어진다면 각 장애군에게 적합한 말·언어 평가 및 진단법을 통해 얻은 데이터 결과에 대한 신뢰성이 보장될 수 있을 것이다. 실례로 본 연구의 분석 문헌 중 언어 병리학 전문가가 공동저자로 참여한 문헌(Liu et al., 2019)에서 대상자 중증도 분류를 위해 활용된 과제 유형 및 수준, 추출된 특성 등의 적절성이 이를 방증 하는 것이라 할 수 있다. 그러므로 추후 임상현장 적용을 고려했을 시 언어병리학 전문가가 개발과정에서부터 적용까지 참여하여 임상 검증을 활성화하고 안정성과 유효성을 확보해야 할 필요성이 제기된다. 활용된 AI 알고리즘 모델의 경우, 머신러닝, 딥러닝의 하위 알고리즘이 개별 데이터의 특성 및 목적에 따라 사용되고 있었고, 적용방법이 다양하였으며 2개 이상의 모델을 복합적으로 적용하기도 하였다. 이는 평가 및 진단과 관련하여 최적의 방법을 찾아내기 위한 노력이라고 보여 진다.
문헌의 질 평가 결과, 본 연구에서 선정된 문헌 18편 모두 분석 대상자의 말·언어 샘플 데이터가 분석대상에 모두 포함되고 표본집단을 선정한 경우 자료수집이 전향적, 무작위 선정 및 부적절하게 배제되는 경우가 없었기 때문에 연구 대상자 선택 영역에서의 비뚤림의 위험 및 적용 가능성에 대한 문제가 낮았다. 또한, 해당 분야의 전문가 및 타당한 규준 및 기준에 따라 참조표준이 설정되고 인공 지능 기반 알고리즘을 활용하여 새로운 진단검사 기준을 설정하였기 때문에, 참조표준 기준과 진단검사 기준 영역에 대한 비뚤림의 위험 및 적용 가능성에 대한 문제도 낮게 보고되었다. 하지만, 전체 문헌 중 6편(33.3%)이 참조표준검사와 진단검사 시행의 독립성 및 두 검사 간 시행간격의 적절성이 보고되지 않아 연구진행 과정 및적시성 영역에 대한 비뚤림의 위험이 불확실한 것으로 평가되었다. 참조표준과 진단 기준을 적용하는 방법과 시기 및 범위의 문제가 진단 정확도 결과에 영향을 미칠 수 있기 때문에, 본 연구의 분석 대상 문헌에 나타난 평가대상검사와 참조표준검사가 서로 독립적으로 시행되지 않아 서로의 결과에 영향을 주는 오류(test review bias and diagnostic review bias)등을 범하지 않기 위해서는 반드시 독립성 및 시행간격에 관한 정보를 명시해야 할 필요성이 요구된다(Lee & Lee, 2011).
문헌의 대부분(83.3%)은 말하기 과제를 분석하여 음성신호(speech signal)로부터 특성들을 추출한 후, 유용한 특성들을 선택하고, 이후 선택된 특성들을 각 연구에서 제안된 알고리즘 형태에 적용하여 학습을 통해 각 장애군의 평가 및 진단을 시도하였다. 이때 추출된 특성은 상당수(66.7%)가 음향학적 특성을 활용하고 있었으며, 음향학적 특성 중 하위 범주 내 유형(기본주파수, 강도 및에너지, 시간적 측면 등) 및 하위 범주 간 특성(스펙트럼, 운율적, 음성의 질 등)을 혼합하여 사용하였다. 또한, 음향학적 특성 외 공기 역학 및 이미지 데이터의 질감 특성, 즉 국소 이진패턴(local binary pattern, LBP)을 함께 사용하는 등의 단일 특성만이 아닌 2가지 이상의 특성을 함께 활용하는 경우(16.7%)도 있었고, 이 밖에 시선추적, 뇌전도, 절단점(cut-point)과 같은 데이터 특성이 포함되었다. 종래에는 음향학적 분석을 위한 특성 값 중 하나인 멜 주파수 켑스트럼 계수, 주파수 변동률(jitter), 진폭 변동률(shimmer) 등이 주로 분석의 대상이 되었다면, 해당 특성 외 자동 음성 인식(Automatic Speech Recognition, ASR)의 음성 특징(voice features), 왜도(skewness), 첨도(kurtosis), 분산(variance) 등의 새로운 특성 값을 추가하여 평가 및 진단에 활용하였으며 컴퓨터 비전 및 영상처리의 분야에서 빈번히 사용되는 특성인 국소 이진패턴과 음향학적 특성을 함께 사용하여 활용된 경우도 있었다. 이는, 인공지능 기반 알고리즘을 활용하여 특정 장애군의 평가 및 진단을 목적으로 학제 간 기술 융합을 통한 다각적 접근 통해 최적의 방안을 찾고자 하는 활발한 시도로 보여 진다(Kang et al., 2022). 하지만, 대체적으로 특성들이 음성신호로부터 추출되었기 때문에 각 장애군의 평가, 진단, 예후, 중증도 및 하위 유형 분류에 있어서 음향학적 특성에 기반한 분석에 편중되어 있었다. 각 장애군의 말 · 언어 특성에 근거한 평가 및 진단 방식이 중요한 이유는 중재와 직접적인 연관성을 지니고 있기 때문이다(Aram & Hall, 1989). 그러므로 인공지능 알고리즘을 기반으로 평가 및 진단 시 활용되는 특성 추출 역시 각 장애군에 적합한 접근 방식이 요구된다고 할 수 있다. 즉, 음성신호 처리(speech signal processing)를 통한 음향학적 특성 외에도 자연어 처리(natural language processing, NLP) 과정을 기반으로 어휘적(lexical) 특성을 활용한 어휘다양도(lexical diversity), 통사적(syntactical) 특성을 활용한 구성/의존구문분석(constituency/constituency parsing), 의미적(semantic) 특성을 활용한 단어/문장 임베딩(word/sentence embeddings) 등과 같은 텍스트 기반(text-based)의 방식을 활용하여 각 장애군에 적합한 평가 및 진단이 이루어져야 할 것이다(Voleti et al., 2019). 본 연구에서 확인한 과제 영역은 말하기 과제를 통한 분석이 83.3%로, 이는 발화 내 변인을 분석하여 발화 정보를 통해 평가 및 진단을 시도하고자 하였으나 과제 수준은 상당 수가 음소 및 단어 수준(61.1%)에서 이루어지고 있는 것으로 나타났다. 실제 임상현장에서의 평가 및 진단은 단선적으로 이루어지지 않기 때문에 인공지능을 활용한 평가 및 진단 결과에 신뢰성을 확보하고 임상현장에서의 적용 가능성을 고려해 봤을 때, 다양한 언어학적 수준에서의 평가가 요구된다. 더불어, 다양한 언어학적 수준은 언어학적 맥락의 수준에 따라 서로 다른 수행결과를 보이게 할 수 있으므로(Ertmer, 2011) 음소 및 단어 수준의 과제와 더불어 문장, 단락 및 담화 수준을 포함하는 과제를 다양하게 사용하여 보다 통합적인 관점에서의 말·언어 능력을 평가해야 할 필요성이 있다.
인공지능의 수행력을 판별하는 지표에는 여러 종류가 존재하고, 알고리즘 모델 및 목적에 맞는 적합한 지표를 사용하게 된다(Shen et al., 2019). 그 중 정확도는 가장 빈번하게 사용되는 지표로 전체 결과 중 정답을 정확하게 예측한 비율을 의미한다. 민감도와 특이도는 분류 능력이 어느 정도 되는지 성능을 측정할 때 쓰는 지표이다. 질환을 가지고 있는 사람 중에 특정 진단검사가 양성(positive)이 나올 확률을 민감도, 특정 질환을 가지고 있지 않은 사람 중에 특정 진단검사가 음성(negative)이 나올 확률을 특이도라 한다 (Davidson, 2002). 곡선하 면적 지표의 경우, 1에 가까우면 민감도와 특이도가 거의 100%에 가깝다는 것을 의미하며 일반적으로 .7 이상 되어야 의미 있는 수치라고 판단한다(Zhang & Mueller, 2005). 이 밖에도 실제 데이터에서 올바르게 판별된 수치를 의미하는 재현율, 예측의 정확성을 판단하는 정밀도, 재현율과 정밀도의 조화 평균을 의미하는 F1-score 등의 지표가 있다(Davidson, 2002). 본 연구에서 확인한 인공지능 기반 알고리즘에 수행력 결과는 목적 및 지표에 따라 범위가 다양했다. 평가 및 진단을 목적으로 하는 11편의 문헌 중에서 알고리즘 수행력 지표 내 정확도는 59.38%-99.23%로 다른 지표에 비해 편차가 크게 나타났다. 이중 2편에서 보고한 민감도(64.71%-99.52%), 특이도(53.33%-98.52%) 역시 다른 지표에 비해 편차가 크게 나타났다. 이는 개별연구의 데이터 특성 부분으로 사료되며 데이터기반 AI의 성능은 학습할 수 있는 데이터의 양과 질에 좌우되기 때문에(Song et al., 2020), 해당 부분을 고려한 개선이 이루어져야 할 것으로 생각된다. 또한, 인공지능 기반 모델의 정확성은 출력 값과 알려진 정답을 비교함으로써 측정되는데, 모델은 데이터에 포함된 중요하지 않은 특징이나 패턴까지 기억하여 정확성을 높일 수 있다. 이때, 편의 표본 추출법으로 샘플링 된 입력 데이터가 모델에 영향을 끼치기 때문에, 학습 데이터만 잘 맞히는 과적합(overfitting)오류 등의 문제가 생길 수 있음을 배제할 수 없다. 또한, 학습 데이터가 실제로 사용될 환경의 데이터를 대표하지 못하게 될 경우 실제 임상현장에서 적용 시 정확도를 보장할 수 없다. 따라서 특정 학습 데이터로 도출한 정확성에만 의존할 수는 없기 때문에, 인공지능 모델에 대한 이해를 높이고, 투명성과 설명가능성을 향상시켜 신뢰성(trustworthy)을 높일 수 있도록 해야 할 것이다. 또한, 전문가와의 비교를 통한 인공지능 기반 알고리즘의 수행력 결과 역시 상이하였다. 인공지능의 수행력이 전문가의 수행력에 버금가거나 능가하는 경우도 있었고(Hu et al., 2021) 성능 지표에 따라 다른 결과가 도출되는 경우도 있었으며(Nakai et al., 2017), 전문가의 수행력이 더 뛰어난 경우도 있었다(Barbera et al., 2021). Nakai 등(2017)의 연구에서는 단단어 수준 이름대기 과제에서의 F1-score 지표 수행력은 인공지능이 우수했지만, 실제 임상현장에서는 단선적인 평가 지표만 가지고 진단을 내리기 않기 때문에, 다양한 과제 수준에서의 인공지능의 수행력을 살펴보는 후속 연구를 제언하기도 하였다. Barbera 등(2021)은 실어증 대상군의 중증도가 인공지능의 수행력에 영향을 미치는 것을 제한점으로 두기도 하였다. 실제 임상현장에서의 평가 및 진단은 대상자에 대한 정보 및 다차원적 측면으로 접근한 평가를 토대로 이루어지나(Dockrell, 2001), 인공지능 알고리즘을 활용한 경우, 상이한 데이터가 입력되면 알고리즘 성능이 저하되는 문제가 발생해 결과에 대한 불확실성이 존재할 수 있는 위험이 있다(Kunze et al., 2021). 이러한 단점은 그동안 언어병리학 분야에서 축적된 말 · 언어 문제의 평가 및 진단에 대한 신뢰도와 타당도를 적극적으로 수용하고 활용함으로써 다차원적 접근을 통한 양질의 빅데이터를 구축하는 것으로 보완해 나가야 할 것이다.
이상의 논의를 토대로 종합하면 다음과 같다. 의사소통장애 분야 내 평가 및 진단을 위해 인공지능 알고리즘을 활용한 시도가 매년 지속적으로 논의되고 있었으며 다양한 장애 영역 중 음성장애가 다수의 비중을 차지하고 있었다. 한편, 평가 및 진단 대상군의 연령대는 아동이 과반수(55.6%)로 조기 발견의 중요성을 시사하고 있었다. 그러나 공학 계열 전문가 및 신경과학, 의학계열 등의 전문가가 연구의 핵심적 역할을 주도하고 있기에 말·언어 장애군을 평가및 진단하는 과정의 적합성을 고려했을 때 해석에 주의를 기울여야 할 필요성이 있는 것으로 보인다. 그러므로 향후에는 개발 과정에서부터 언어병리학 전문가의 적극적 참여를 통해 적합한 평가 과제 및 맥락을 적용한 인공지능 활용 방안을 마련해야 할 것이다. 또한, 학제 간 활발한 기술 융합을 통한 새로운 접근의 시도를 살펴볼 수 있었으나, 평가 및 진단에 활용되는 특성이 음향학적 특성에 기반한 분석에 편중되어 있어 텍스트 기반 등의 포함 및 각 장애군의 특성에 적합한 방식이 요구된다. 더불어 대상자의 중증도 및 과제의 수준 역시 고려하여 다각적으로 살펴보아야 할 필요성이 제기된다. 이 밖에도 실제 임상현장에서 적용 시 학습된 데이터의 수행력 편차를 극복하고 신뢰성을 보장하기 위해, 언어병리학 분야 내 축적된 지식과 해당 관점의 빅데이터 구축을 토대로 인공지능 알고리즘과 접목하는 방식이 필요할 것으로 보인다.
본 연구의 제한점으로는 언어병리학 외 각 장애 영역에서의 세부 질환명을 검색어에 반영하지 않았기에 양적으로 충분히 확보되지 못하여 분석에 포함된 문헌의 수(18편)가 적었고, 문헌의 질 평가에서 연구진행 과정 및 적시성 영역에 대한 비뚤림의 위험이 불확실한 것으로 평가되어 본 문헌의 결과를 일반화하기에는 어려움이 있다는 것이다. 또한, 본 연구에서는 인공지능 알고리즘을 활용하여 의사소통장애 분야의 평가 및 진단을 주제로 시행된 국내 연구가 전무하여 국외 연구만을 분석의 대상으로 삼았기 때문에 국내 연구와 국외 연구결과를 비교 분석하기 어려웠다. 이 밖에도 체계적 문헌고찰에서 선정된 일차 연구를 토대로 양적 합성이 가능한 경우 메타분석을 실시하여 진단 정확도와 관련한 정보를 탐색하고자 하였으나, 연구설계, 종속변수 수치 등의 이질성으로 인하여 실시하지 못한 점이 아쉬움으로 남아있다.
본 연구는 의사소통장애 분야에서 평가, 진단, 예후, 중증도 및 하위 유형 분류를 목적으로 인공지능 알고리즘 활용이 어떻게 이루어지고 있는지 전반적인 동향을 파악하고자 하였다. 인공지능은 시대적 흐름으로 언어병리학 분야 내에서도 해당 알고리즘을 활용한 학문적 탐구 및 중재를 포함한 임상 적용 가능성에 대해 활발한 논의가 이루어지고 있는 만큼(Kang et al., 2022; Liss, 2020; Park et al., 2019; Song et al., 2020), 이를 실제 임상현장에서 사용하기까지 전술하였던 논의 사항에 대한 고려가 선행되어야 할 것이다. 본 연구는 최근 의사소통장애 분야의 평가 및 진단을 중심으로 인공지능 활용 연구에 대한 동향을 체계적 문헌고찰을 통하여 살펴봄으로써, 향후 실제 임상현장에서 인공지능이 활용되기 위해 선행되어야 할 고려사항 및 방향성에 대한 기초자료를 제시하였다는 데 의의가 있다.
Notes
*indicates studies included for the analysis)