


전 세계적으로 청각에 문제를 가지고 있는 사람들은 약 3억 6천만 명으로 전 세계인구의 5% 정도로 추정되며, 성인은 청력이 좋은 쪽 귀의 평균 역치가 40 dB 이상일 때를 기준으로 약 3억 2천 8백만명, 아동은 좋은 쪽 귀의 평균 역치가 30 dB 이상일 때를 기준으로 약 3천 2백만 명이 청각장애를 가지고 있는 것으로 보고되고 있다(World Health Organization, 2017). 또한, 전 세계적으로 65세 이상의 노인들 중에서 약 1/3은 청력에 문제를 갖고 있으며, 청년층(12–35세 사이)에서는 약 11억 명 정도가 소음에 대한 노출과 유희적 요소로 인해 난청의 발병 위험군에 속해있다(World Health Organization, 2017). 국내의 경우, 아직까지 정확한 난청 유병률 통계보고는 없지만 2016년 장애인등록현황을 살펴보면 청각장애는 약 271,843명으로 2006년 182,361명과 비교했을 때, 10년 동안 1.5배 가량(약 49%) 증가한 것을 확인할 수 있다(Ministry of Health and Welfare, 2006, 2016). 우리나라의 청각장애등급을 살펴보면 가장 낮은 등급인 6급의 경우, 한 귀의 손실이 80 dB HL 이상이고 다른 귀의 손실이 40 dB HL 이상이므로, 16 dB HL 이상을 난청으로 규정하는 미국언어청각협회(American Speech-Language-Hearing Association, ASHA)의 기준(Clark, 1981)으로 조사를 한다면 난청 의 인구 비율은 더 높을 것으로 전망된다.
이렇듯 국내뿐만 아니라 전 세계적으로 고령화 및 소음 환경의 증가로 인해 난청의 유병률은 지속적으로 증가하는 추세이다. 이로 인해 보청기의 수요가 점진적으로 증가하고 있으며 보청기를 필요로 하는 사람들 또한 지속적으로 증가할 것으로 추정된다. 2013년을 기준으로 세계 보청기 시장 규모는 약 77.7억 달러로 2006–2013년 연평균 성장률은 5.7%였으며, 2013–2020년의 연평균 성장률은 6.9%로 증가할 것으로 예측하고 있다(Kim & Song, 2015). 또한, 2020년에는 세계 보청기 시장 규모가 약 124억 달러까지 증가할 것으로 전망하고 있다. 국내 보청기 시장 동향을 살펴보면 2014년 기준으로 약 612억으로 집계되며, 2010–2014년 연평균 성장률은 8.4%로 보고된다(Ministry of Food and Drug Safety, 2014). 이를 통해 국내에서도 보청기 시장이 빠른 속도로 증가하고 있는 것을 확인할 수 있다.
보청기 시장 규모가 증가하면서 국제적으로 보청기에 대한 연구도 활발하게 진행되고 있으며 새로운 성능의 보청기들도 많이 개발되고 있다. 또한, 보청기의 성능 분석 및 적합(실이측정, 커플러 측정 등)을 위한 전기음향학적 측정기준도 지속적으로 개선 및 보완되고 있다. 보청기의 전기음향학적 측정 관련 기준은 미국음향학회(Acoustical Society of American, ASA) 내 위원회인 국제전기기술위원회(International Electrotechnical Commission, IEC)의 보청기 관련 기준과 미국표준협회(American National Standards Institute, ANSI)의 보청기 관련 기준이 있다. IEC 60118–0 (IEC, 1983)과 ANSI S3.22 (ANSI, 2003)는 아날로그 보청기의 특징만을 반영한 기준으로 기술되어 있다(Bisgaard, Vlaming, & Dahlquist, 2010). 이 방식은 정현파 시험 신호(sinusoidal test signal)와 같은 고정적인 신호음(stationary signals)을 사용하며, 입력 신호에 대해 산출 신호가 일정한 선형 보청기에서는 적합한 정보를 제공할 수 있었다(Holube, Fredelake, Vlaming, & Kollmeier, 2010).
하지만 1990년대 중반 디지털 보청기가 개발되면서 기존 아날로그 보청기에 적합한 표준안들은 디지털 보청기의 복잡한 처리과정 시스템을 적절하게 반영하기 어려웠다. IEC 60118–0과 ANSI S3.22의 측정 방법을 통해서는 실생활에서의 디지털 보청기 성능을 예측하기 어려웠기 때문에, 입력 신호와 레벨에 따라 이득과 산출값이 변하는 시변적(time-variant)인 디지털 보청기 특성을 반영하는 좀 더 체계화된 방법이 필요하였다(Henning & Bentler, 2005; Holube et al., 2010; Scollie & Seewald, 2002). 결과적으로 최선의 방법은 어음(speech) 혹은 어음과 비슷한 형태의 신호음(speech-shaped signal)을 사용하여 보청기의 이득과 산출값을 구하는 것이었다(Henning & Bentler, 2005; Scollie & Seewald, 2002; Stelmachowicz, Mace, Kopun, & Carney, 1993).
따라서, 재활청각학국제연맹(International Collegium of Reha-bilitative Audiology, ICRA)에 의해 어음과 비슷한 신호음(modu-lated speechlike signal)이 개발되었고(Dreschler, Verschuure, Ludvigson, & Westermann, 1999), 그 이후에 실제 단화자 음성의 억양을 기준으로 한 ICRA-5로 개선되었다(Holube et al., 2010). 이는 실제 어음과 유사한 방식으로 입력 신호를 제공할 수 있다는 장점이 있지만, 영어를 모국어로 사용하는 단화자로 구성되어 타 언어의 특성을 반영할 수 없었기 때문에 국제적 표준 시험 신호로서 적용될 수 없는 한계가 있었다(Holube et al., 2010). 따라서, 2004년 유럽 보청기 제조사 연합(European Hearing Instrument Manufactur-ers Association, EHIMA)은 디지털 보청기에 적합한 새로운 국제적인 표준안을 개발하기로 결정하였다(Bisgaard et al., 2010). 유럽 보청기 제조사 연합은 표준 초안을 개발하는 작업 그룹인 ‘디지털 보청기 측정 개선을 위한 국제 표준 그룹(International Standards for Measuring Advanced Digital Hearing Aids, ISMADHA)’을 설립하여 국제어음시험신호(International Speech Test Signal, ISTS)라는 새로운 측정 신호음을 개발하였고 2012년 IEC 60118–15 (IEC, 2012)와 ANSI S3.42-Part 2 (ANSI, 2012)에 표준안으로 승인되었다.
국제어음시험신호는 현재까지 6개 국어의 음성신호(아랍어, 영어, 독일어, 프랑스어, 중국어, 스페인어)로 구성되어 있으며 각 언어를 모국어로 사용하는 여성 화자를 대상으로 녹음을 진행하였다. 남성 및 아동의 음성적 특징(기본주파수 범위, 평균 스펙트럼 모양 등)과 비교하였을 때 여성의 음성적 특징이 중간값을 나타내기 때문에 국제어음시험신호는 여성 화자를 기준으로 제작되었다(Holube et al., 2010). 국제어음시험신호는 방음실에서 녹음이 진행되었고 마이크로부터 45도 각도로 20–30 cm 떨어진 지점에 입술이 위치하게 하였으며, 녹음 시 표본화 주파수와 비트(bit)는 44,100 Hz 와 16비트로 설정하여 녹음되었다. 담화 형태인 ‘바람과 해님(The North Wind and the Sun)’을 자연스럽게 읽도록 하였고 녹음 이후 각 언어를 대표할 수 있는 적절한 모국어 화자의 녹음본을 선별하였다. 21명 중 6명을 선별하였는데, 지역적 방언의 유무, 목소리의 음질, 발음의 자연스러움 등을 선별기준으로 하였다. 녹음파일은 묵음 휴지(silent pauses)가 최대 600 ms를 초과하지 않게 하였으며, 여성 화자의 국제장기평균어음스펙트럼(International Long-Term Average Speech Spectrum, ILTASS) 값을 기준으로 필터링하여 표준편차 1 dB 미만 내로 모사하였다. 국제장기평균어음스펙트럼은 1994년 Byrne 등(1994)이 제안하였고, 이 연구에서는 영어, 독일어, 프랑스어, 일본어, 중국어, 베트남어를 포함한 12개 언어의 장기평균어음스펙트럼(Long-Term Average Speech Spectrum)을 비 교하였다. 그 결과 언어별로 비슷한 주파수별 장기평균어음스펙트럼 값이 확인되었고, 다른 언어에 비해 유의한 차이가 나타나는 언어 집단은 존재하지 않았기 때문에 12개 언어의 평균 장기평균어음스펙트럼 값을 사용하여 국제적으로 통용될 수 있는 국제장기평균어음스펙트럼을 제안하였다.
국제장기평균어음스펙트럼으로 필터링한 녹음본을 음절 단위로 분할(segmentation)하는 과정이 필요했는데, 우선은 대략 한 음절 단위로 나눌 수 있는 자동화 프로그램을 거쳐서 분할하였다. 이후, 100–600 ms 길이 범위로 분할된 조각들을 평활전이과정(smooth transition)을 통해 처음과 끝부분의 강도가 0 dB이 될 수 있도록 조절하였다. 다음으로, 분할된 조각들을 혼합(remixing)하는 과정을 시행하였는데, 주파수 영역에 대하여 일정한 진폭을 가질 수 있도록 의사 무작위 추출방법(pseudo-random order)으로 음절 조각들을 위치하게 하였다. 마지막으로 국제장기평균어음스펙트럼 특징을 갖도록 필터링하였으며, 65 dB SPL로 평균실효값(root-mean square, RMS)을 정규화(normalization)하였다. 위의 과정들을 통하여 1분 길이의 무의미한(non-intelligible) 음성 신호인 국제어음시험신호가 개발되었다(Holube, 2011).
한국의 경우 보청기 적합 소프트웨어뿐만 아니라 성능분석기, 실이측정기 프로그램들은 대부분 미국, 유럽 등에서 수입하고 있기 때문에(Lee & Kim, 2009) 국제장기평균어음스펙트럼에 기초한 국제어음시험신호를 주로 사용하고 있다. 그러나 여러 연구에서는 한국어와 영어의 장기평균어음스펙트럼이 다른 특성을 가지고 있다고 보고하고 있다. Lee, Lee와 Lee (2008)의 연구에서는 한국어를 모국어로 사용하는 남녀 16명(남자 8명, 여자 8명)의 다화자잡음과 영어음(Byrne & Dillion, 1986)의 장기평균어음스펙트럼을 비교하였을 때, 1,250 Hz를 기준으로 저주파수 영역에서는 한국어가 더 높은 장기평균어음스펙트럼 값을 가지고 고주파수 영역에서는 영어가 더 높은 값을 가지는 것을 확인하였다. 또한, Noh와 Lee (2012) 에서도 2,000 Hz를 기준으로 저주파수 영역에서는 한국어가 더 높은 장기평균어음스펙트럼 값을 가지며 고주파수 대역에서는 영어가 더 높은 값을 가지는 것을 볼 수 있다. 선행연구 결과에서 알 수 있듯이 한국어는 영어와 비교하였을 때 명확한 음향학적 차이를 가지고 있다. 또한, 국제어음시험신호는 영어를 비롯한 6개의 언어적 특성을 반영한다고 볼 수 있지만, 한국어가 제외되어 있어 한국어의 독특한 음향적 특성을 반영하고 있는지는 확인할 수 없다.
그러므로 본 연구에서는 한국어 어음 샘플과 국제어음시험신호의 보편적 음향적 요소(global acoustical aspect)의 비교를 통하여 두 어음 신호 간의 차이점을 비교하고자 하였다. 이를 위해 한국어의 어음 신호를 국제어음시험신호의 녹음 환경과 유사하게 제작하 여 어음역동범위와 장기평균어음스펙트럼을 비교하였다.
본 연구에 대한 가설은 다음과 같다. 첫째, Jin, Kates와 Arehart (2014)의 연구에서는 한국어, 영어, 중국어 사이의 어음역동범위를 비교한 결과, 한국어는 영어와 중국어의 어음역동범위와는 다른 특성을 가지고 있는 것으로 나타났다. 따라서 한국어 어음 샘플의 어음역동범위는 국제어음시험신호의 어음역동범위와 다른 특성을 보일 것이라고 예측한다. 둘째, Lee 등(2008)과 Noh와 Lee (2012)의 선행연구 결과에 근거하였을 때, 1,250–2,000 Hz 사이의 주파수 영역을 중심으로 저주파수 영역에서는 한국어가 국제어음시험신호보다 더 높은 장기평균어음스펙트럼 값을 가질 것이며, 고주파수 영역에서는 국제어음시험신호는 한국어 어음 샘플보다 더 높은 값을 가질 것이라고 예측한다.
연구방법
연구대상
본 연구는 한국어를 모국어로 사용하는 20대 여성 50명을 대상으로 하였다(평균 연령 21.8세, 연령 범위: 20–27세). 모든 연구 대상자들은 과거 이과적 병력이 없었으며, 순음청력검사(pure-tone au-diometry) 결과, 250–8,000 Hz에서 20 dB HL 이내의 정상 청력 역치 범위를 보였다. 고막운동성검사(tympanometry) 결과, 모든 대상자들은 A유형으로 정상임을 확인하였다. 또한, 본 연구는 목소리를 녹음하여 분석하는 것이 주요한 요인이므로 조음과 발성에 문제가 없으며 언어적 결함이 없는 피검자들을 대상으로 하였다.
검사 장비
청력검사 장비
순음청력검사는 GSI-61 (Grason-Stadler Inc., Eden Prairie, MN, USA)과 TDH-50 헤드폰을 사용하여 방음실에서 실시하였고, 고막운동성검사는 GSI TympStar (Grason-Stalder Inc.)를 통하여 진행하였다.
녹음 장비
본 연구의 녹음은 방음실 내에 설치된 음성분석프로그램 Computerized Speech Lab (CSL; KayPENTAX, Montvale, NJ, USA)과 마이크(Sennheiser e-835s, Wedemark, Germany)를 통해 진행하였다.
음성 분석 소프트웨어
본 연구에서는 녹음된 한국어 어음 샘플과 국제어음시험신호를 동일한 조건에서 비교하기 위하여 세 가지의 음성 분석 소프트웨어를 사용하였다. Adobe Audition CS 6 (Adobe Systems Corp., San Jose, CA, USA)을 사용하여 음성 파일들의 휴지기(pauses)를 제거하였고, Praat v6.0.19 (Boersma & Weenink, 2016)를 통해 비교 음성 샘플 간 평균실효값을 정규화하였다. 동일하게 조건을 맞춘 후 MATLAB (version R 2017a; MathWorks Inc., Natick, MA, USA)을 통해 어음역동범위와 장기평균어음스펙트럼 값을 산출하여 비교하였다. 연구절차에 대한 상세한 설명은 다음 단락에 나와 있으며 연구 모식도를 통해서도 확인이 가능하다(Figure 1).
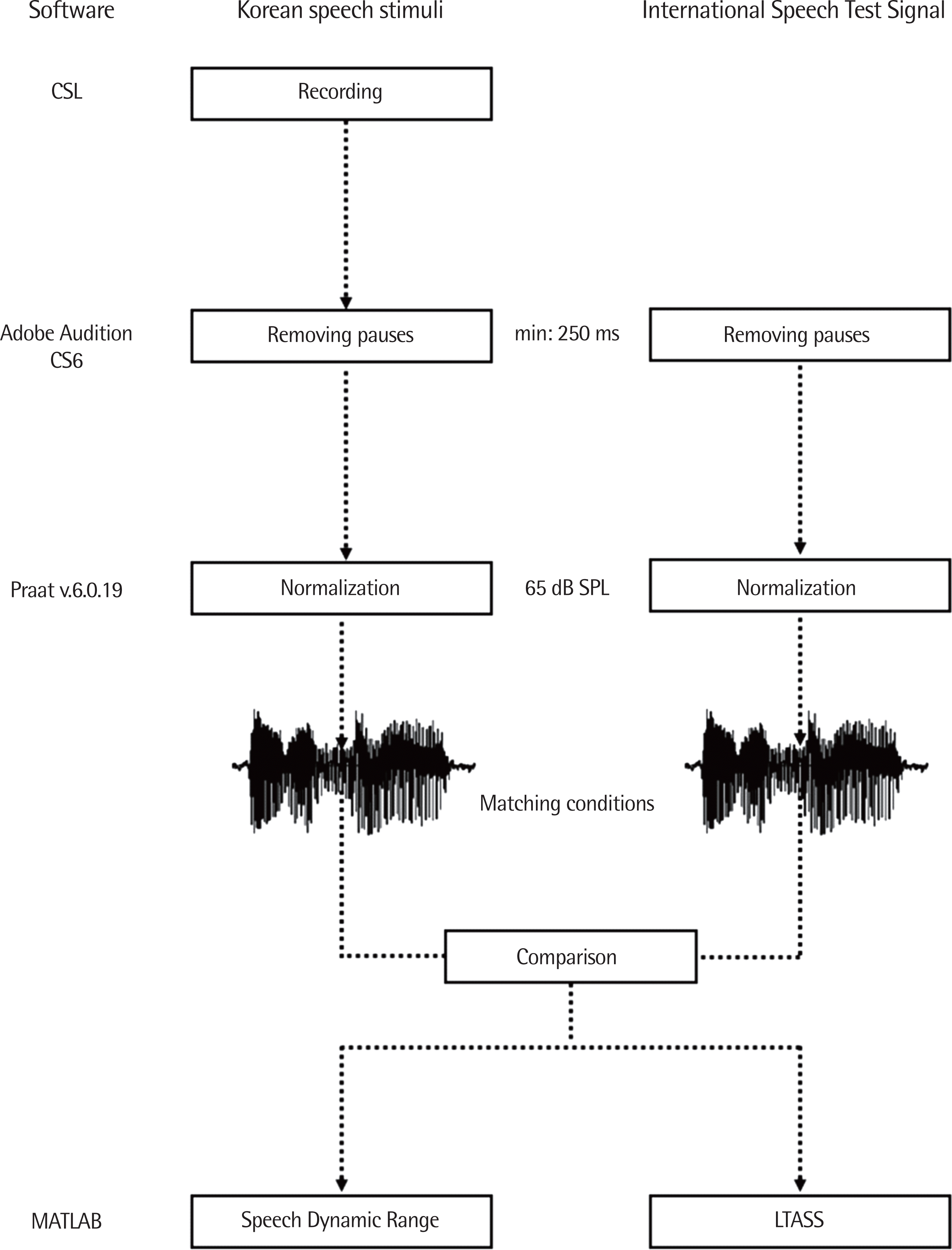
연구 절차
한국어 어음 샘플 녹음과정
본 연구는 방음실에서 음성 분석 프로그램(CSL)과 마이크를 통해 한국어 어음 녹음을 진행하였다. 녹음 시 표본화 주파수와 비트(bit)는 국제어음시험신호와 동일한 조건인 44,100 Hz와 16비트로 설정하였다. 대상자는 의자에 편안한 자세로 앉은 상태에서 입은 마이크로부터 45도 각도로 20–30 cm 거리를 유지하여 녹음을 진행하였다. 국제어음시험신호에서 ‘ The North Wind and the Sun (바람과 해님)’을 어음 자극으로 사용한 것에 기인하여 동일하게 ‘바람과 해님(Borim Press, Paju, Korea)’을 어음 자극으로 사용하였다. 녹음 전에 연구 대상자들에게 음성 샘플을 자연스럽게 읽도록 안내하였고 녹음 과정에서 발음이나 조음이 부자연스러운 경우에는 재녹음을 실시하였다. 참여자들이 녹음 도중 휴식을 원할 경우 수시로 휴식을 제공하였으며 평균 녹음시간은 30분 이내였다. 본 연구에 참여하기 전 연구대상자들에게 연구의 목적, 방법 및 진행 절차에 대한 충분한 설명을 제공하였으며 참여자들은 이에 대해 자발적으로 참여 동의서에 서명을 한 후 녹음을 진행하였다. 모든 연구가 완료된 후 참여자들에게 연구에 대한 수고비를 지급하였고, 모든 연구에 대한 절차 및 내용은 한림대학교 생명윤리위원회(Institutional Review Board)의 승인을 받았다(No. HIRB-2017–104).
한국어 어음 샘플과 국제어음시험신호의 정규화 과정
한국어 어음 샘플과 국제어음시험신호의 어음역동범위와 장기평균어음스펙트럼을 동일한 평균 레벨하에서 비교하기 위하여 다음의 절차에 따라 분석을 실시하였다. 우선, Adobe Audition을 통해 한국어 어음 샘플과 국제어음시험신호의 묵음을 제거하였다. 묵음 시간이 200 ms 이상이면 어음 발성 시 나타나는 묵음의 범위에서 벗어나기 때문에 묵음 휴지(silent pause)의 최소 시간을 250 ms로 설정하여 제거하였다(Kendall, 2013). 또한, 국제어음시험신호 기준과 동일하게 묵음 휴지가 최대 600 ms를 초과하지 않게 설정하였다(Holube et al., 2010). 마지막으로, 음향 분석 도구인 Praat v6.0.19를 통해 각 녹음파일들을 65 dB SPL로 정규화하였다.
어음역동범위 및 장기평균어음스펙트럼 산출 과정
동일한 조건으로 묵음을 제거하고 평균실효값을 정규화한 한국어 어음 샘플과 국제어음시험신호를 대상으로 어음역동범위를 산출하기 위해서 누적 히스토그램 레벨을 사용하였으며, 이 방법은 선행연구(Jin et al., 2014)에서 사용된 어음역동범위 산출 과정과 동일한 방법을 적용하였다. 누적 히스토그램 레벨은 주파수 대역 내에서 어음의 누적 신호 포락선의 분포를 보여준다. 예를 들어, 99% 누적히스토그램 레벨(L99)은 측정된 어음 신호에서 최고치 레벨(peak level)을 포함하거나 그 이하의 99% 부분을 나타내며, 30% 누적히스토그램 레벨(L30)은 측정된 어음 신호에서 최소 레벨을 포함하거나 그 이상의 30% 부분을 나타낸다. 즉, 본 연구에서 L99는 어음의 최대 레벨로 설정하였으며, L30은 어음의 최소 레벨 로 설정하였다. 어음역동범위는 최대 레벨에서 최소 레벨을 뺀 값(L99-L30)을 나타내며, 이 범위는 국제어음시험신호 연구에서 효과적인 어음역동범위로 제안되었다(Holube et al., 2010). 따라서 본 연구에서는 국제어음시험신호에서 적용한 동일한 범위를 사용하여 어음역동범위를 산출하였다.
장기평균어음스펙트럼의 경우 동일한 조건의 한국어 어음 샘플과 국제어음시험신호를 대상으로 MATLAB을 통하여 값을 도출하였다. 디지털 필터링은 ANSI S1.11 (ANSI, 1986) 기준에 맞게 설계되었으며 통과 대역에서 리플(ripple)의 발생 가능성이 가장 적으며 크기 응답 곡선이 필터의 동고대역 내에서 가능한 한 평탄하도록 음성 스펙트럼을 산출할 수 있는 버터워스 필터(Butterworth filter)를 사용하였다(Noh & Lee, 2012).
연구결과
어음역동범위 비교
한국어 어음 샘플과 국제어음시험신호의 어음역동범위를 Figure 2에 제시하였다. 한국어 어음 샘플의 어음역동범위는 전주파수 영역에서 국제어음시험신호보다 좁은 역동범위를 보였다. 한국어 어음 샘플의 어음역동범위의 경우, 11.9 dB (중심주파수: 250 Hz)에서 23.73 dB (중심주파수: 8,500 Hz)을 보인 반면, 국제어음시험신호는 19.75 dB (중심주파수: 250 Hz)에서 34 dB (중심주파수: 7,000 Hz) 사이의 역동범위를 보였다. 또한, 한국어 어음 샘플과 국제어음시험신호의 어음역동범위의 차이값이 9 dB 이상인 주파수 대역은 11개였으며(중심주파수: 150, 1,000, 1,600, 1,850, 2,150, 2,900, 3,400, 4,000, 4,800, 5,800, 7,000 Hz), 9 dB 이내인 주파수 대역은 10개였다(중심주파수: 250, 350, 450, 570, 700, 840, 1,170, 1,370, 2,500, 8,500 Hz).

중심주파수에 따른 최소어음레벨(L30)과 최대어음레벨(L99)
Figure 3에서는 한국어 어음 샘플과 국제어음시험신호의 어음최소레벨(L30)과 어음최대레벨(L99)을 나누어 비교하였다. 어음최소레벨(L30)의 경우, 한 개의 주파수 대역(중심주파수: 2,500 Hz)을 제외하고 20개의 주파수 대역에서 한국어 어음 샘플이 국제어음시험신호보다 더 높은 어음최소레벨(L30)을 보였으며, 그 차이는 1.12 dB (중심주파수: 570 Hz)에서 14.72 dB (중심주파수: 150 Hz) 사이였다. 2,500 Hz (중심주파수) 대역에서는 한국어 어음 샘플이 국제어음시험신호보다 0.22 dB만큼 더 낮은 어음최소레벨(L30)을 보였다. 어음최대레벨(L99)의 경우 16개의 주파수 대역(중심주파수: 350, 450, 570, 700, 1,170, 1,370, 1,600, 1,850, 2,150, 2,500, 2,900, 3,400, 4,000, 4,800, 5,800, 7,000 Hz)에서 한국어 어음 샘플이 국제어음시험신호보다 더 낮은 어음최대레벨(L99)을 보였으며, 그 차이는 0.32 dB (중심주파수: 350 Hz)에서 8.98 dB (중심주파수: 2,150 Hz) 사이였다. 반면에, 5개 주파수 대역(중심주파수: 150, 250, 840, 1,000, 8,500 Hz)에서는 한국어 어음 샘플이 국제어음시험신호보다 더 높은 어음최대레벨(L99)을 보였으며, 그 차이는 0.18 dB (중심 주파수: 1,000 Hz)에서 5.26 dB (중심주파수: 150 Hz) 사이였다.

주파수에 따른 장기평균어음스펙트럼
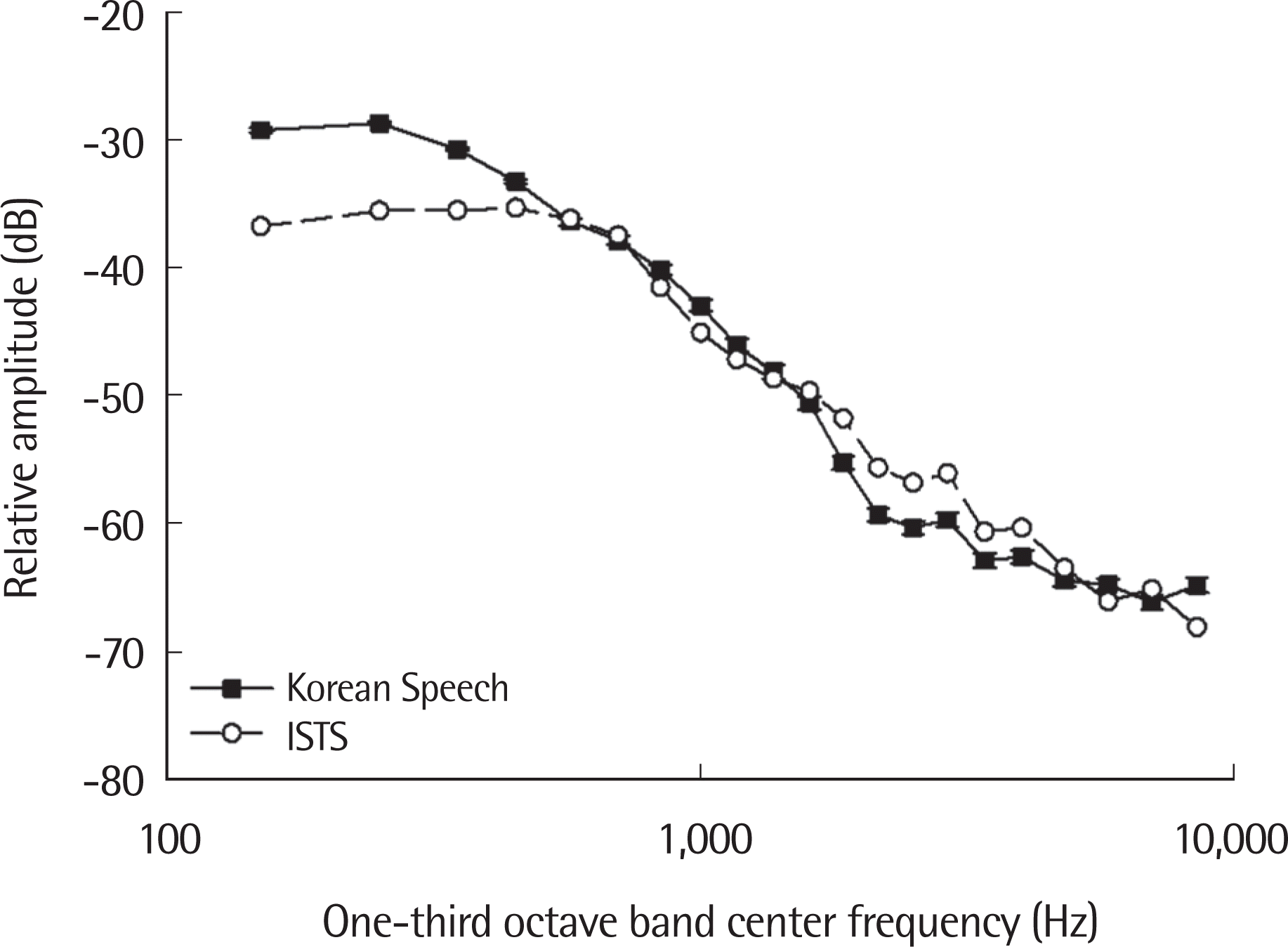
한국어 어음 샘플과 국제어음시험신호의 장기평균어음스펙트럼 값은 Figure 4에 제시하였다. 1,600 Hz를 기준으로 저주파수 영역에서는 2개 주파수 대역(중심주파수: 570, 700 Hz)을 제외하고 한국어 어음 샘플의 장기평균어음스펙트럼 값이 높았으며, 고주파수 영역에서는 2개 주파수 대역(중심주파수: 5,800, 8,500 Hz)을 제외하고 국제어음시험신호의 장기평균어음스펙트럼 값이 더 높게 나타났다. 저주파수 영역(1,600 Hz 기준)의 경우 한국어 어음 샘플의 장기평균어음스펙트럼 값은 국제어음시험신호에 비해 0.53 dB (중심주파수: 1,370 Hz)에서 7.52 dB (중심주파수: 150 Hz)만큼 높게 나타났으며, 고주파수 영역(1,600 Hz 기준)의 경우 국제어음시험신호의 장기평균어음스펙트럼 값은 한국어 어음 샘플에 비해 0.92 dB (중심주파수: 1,600 Hz)에서 3.69 dB (중심주파수: 2,150 Hz)만큼 높게 나타났다.
논의 및 결론
본 연구에서는 한국어를 모국어로 사용하는 여성 화자 50명을 대상으로 담화 샘플을 녹음하여 국제어음시험신호와 어음의 역동범위 및 장기평균어음스펙트럼을 동일한 음향적 조건하에서 비교하였다. 어음역동범위의 경우, 국제어음시험신호의 역동범위가 한국어 어음 샘플의 역동범위보다 전 주파수 영역에 걸쳐 더 넓은 것으로 나타났다. 한국어 어음 샘플의 최대어음레벨(L99)은 국제어음시험신호보다 낮은 것으로 나타났고, 최소어음레벨(L30)은 국제 어음신호보다 높은 것으로 나타났다. 장기평균어음스펙트럼의 경우, 저주파수의 경우에는 한국어 어음 샘플의 스펙트럼 레벨이 높은 것으로 나타났고, 고주파수의 경우에는 국제어음시험신호의 스펙트럼 레벨이 높은 것으로 나타났다.
어음역동범위 결과 분석
본 연구의 결과는 한국어 어음 샘플과 국제어음시험신호 간의 명백한 어음역동범위의 차이를 보여주고 있다. 또한, 국제어음시험신호가 한국어 어음 샘플보다 전 주파수 대역에서 대체적으로 더 낮은 최소어음레벨(L30)과 더 높은 최대어음레벨(L99)을 가지는 것을 확인하였다. 특히, 최대어음레벨(L99)의 경우에는 5개의 주파수 대역을 제외하고 16개의 주파수 대역에서 한국어가 국제어음시험신호에 비해 최소 0.32 dB에서 최대 8.98 dB만큼 낮은 역동범위를 보였다. 이러한 최대어음레벨(L99)의 차이는 보청기 적합의 예후를 예측하는 모델인 어음인지지수의 관점에서 어음인지도 수행력의 차이를 야기할 수 있다.
어음인지지수는 주파수별 중요도(band-importance function)와 가청영역(band-audibility function)의 상관관계를 통해 전이함수(transfer function)를 도출하여 어음인지도 수행력을 예측하는 모델이다(ANSI 1997/R2012). 최대어음레벨(L99)이 다른 두 어음신호를 비교할 때, 더 높은 최대어음레벨(L99)을 가진 어음신호가 더 높은 평균실효값 레벨을 포함하기 때문에 신호대잡음비(signal-to-noise ratio, SNR)가 높아져, 어음인지지수의 전이함수(transfer function)상에서 더 높은 어음인지도를 도출하게 된다. 예를 들어, Jin, Kates와 Arehart (2017)는 한국어의 어음역동범위의 변화에 따른 전이함수를 도출하였는데 어음인지지수(Speech Intelligibility Index, SII) 값이 0.3 SII인 경우 어음역동범위가 30 dB에서 40 dB로 증가할 때, 예측되는 어음인지도 점수는 50%에서 70%로 증가하는 것으로 보고하였다. 어음역동범위가 30 dB일 때는 평균실효값 레벨을 기준으로 ±15 dB을 나타내고, 어음역동범위가 40 dB일 때는 평균실효값 레벨을 기준으로 +25 dB에서 −15 dB 사이를 나타낸다. 즉, 최대어음레벨(L99)이 30 dB에서 40 dB로 증가할 때 어음인지도가 약 20%가 증가하게 되므로 최대어음레벨(L99)이 1 dB 증가할 때, 어음인지도 수행력은 약 2% 정도 증가한다고 볼 수 있다. 본 연구의 결과에서는 최대어음레벨(L99)은 주파수별로 상이하지만 주파수별 최대어음레벨(L99) 값을 평균하였을 때 국제어음시험신호는 51.27 dB이었고, 한국어 어음 샘플의 경우에는 48.42 dB로 그 차이는 약 2.85 dB이었다. 한국어 기반 어음인지지수의 관점에서 2.85 dB의 최대어음레벨(L99)값의 차이는 약 5.7%의 어음인지도 수행력의 차이를 의미한다. 이러한 차이는 한국어를 모국어로 사용하 는 대상자가 보통 말소리(65 dB SPL) 수준에서 국제어음시험신호를 사용하여 보청기 예후를 예측할 경우 한국어 어음 샘플을 사용했을 때보다 약 5.7% 정도 더 높은 어음인지도로 산출될 수 있음을 예측할 수 있다. 따라서 본 연구의 결과는 국제어음시험신호가 한국어 어음 샘플과는 다른 최대어음레벨(L99)을 가지고 있기 때문에 한국어를 모국어로 사용하는 사람들에게 보청기 적합 시, 한국어 어음 특성을 정확하게 반영하기 위해서는 한국어 기반의 시험 신호의 사용이 더 적절할 수 있음을 시사한다.
장기평균어음스펙트럼 결과 분석
본 연구 결과 한국어 어음 샘플과 국제어음시험신호는 각기 다른 장기평균어음스펙트럼 특성을 가지고 있음을 확인할 수 있었다. 특히, 저주파수 영역에서는 한국어 어음 샘플의 장기평균어음스펙트럼 값이 국제어음시험신호보다 높았으며, 고주파수 영역에서는 국제어음시험신호의 장기평균어음스펙트럼 값이 더 높았다. 이러한 특징은 한국어와 국제어음시험신호의 구성 언어 중 하나인 영어와의 장기평균어음스펙트럼 값을 비교한 선행연구의 결과와 일치한다. Lee 등(2008)은 한국어(다화자잡음)와 영어(다화자잡음)의 장기평균어음스펙트럼을 비교하였는데, 중심주파수 1,250 Hz를 기준으로 저주파수 영역(250–1,250 Hz)에서는 한국어가 영어보다 더 큰 장기평균어음스펙트럼 값을 가지며, 고주파수 영역 (1,250–6,000 Hz)에서는 영어가 한국어보다 더 큰 장기평균어음스펙트럼 값을 가진다고 보고하였다. 또 다른 선행연구인 Noh와 Lee (2012)의 연구에서도 한국어와 영어의 장기평균어음스펙트럼을 비교하였는데, 중심주파수 2,000 Hz를 기준으로 하여 저주파수 영역(100–2,000 Hz)에서는 한국어가 영어보다 더 큰 장기평균어음스펙트럼 값을 가지며, 고주파수 영역(2,000–10,000 Hz)에서는 중심주파수가 4,000 Hz 일 때를 제외하고 영어가 한국어보다 더 큰 장기평균어음스펙트럼 값을 가지는 것으로 나타났다.
본 연구에서는 중심주파수 1,600 Hz를 기준으로 저주파수 영역(100–1,600 Hz)에서는 중심주파수가 570과 700 Hz 일 때를 제외하고 한국어가 국제어음시험신호보다 장기평균어음스펙트럼 값이 높았고, 고주파수 영역(2,000–10,000 Hz)에서는 중심주파수가 5,800과 8,500 Hz 일 때를 제외하고 국제어음시험신호가 한국어보다 장기평균어음스펙트럼 값이 높았다. 비록 위에서 언급한 선행연구들에서 사용한 언어(영어)는 국제어음시험신호에서 사용된 6개의 언어 중 하나에 불과하기 때문에 직접적인 비교에는 한계가 있을 수 있으나 한국어의 장기평균어음스펙트럼의 특성은 영어뿐만 아니라 영어의 음향적 특성이 포함되어 있는 국제어음시험신호와 다르다는 것을 알 수 있다.
제한점 및 후속연구
본 연구는 몇 가지 제한점을 가지고 있다. 첫째, 본 연구에 사용된 한국어 어음 샘플은 20대 초, 중반 여성들의 목소리로 구성되어있다. 실제로 국제어음시험신호를 녹음한 화자들은 각각 25, 25, 26, 29, 33, 37세(평균 29.1세)의 여성 화자 6명이다. 국제어음시험신호와 최대한 유사한 조건으로 진행하기 위해 여성 화자만을 녹음하였지만, 본 연구에서는 여성 화자 50명의 나이 평균이 21.8세로 국제어음시험신호 여성 화자의 나이 평균보다 7세가 더 어리다. 물론 나이 연령대가 같은 20대이고 신체 기능을 검사하는 것이 아닌 목소리를 녹음하는 것이기 때문에 연구 결과에 크게 영향을 미칠 가능성은 적지만, 후속연구에서는 연령대를 조금 더 넓혀서 진행한다면 더 정확한 조건하에서 비교할 수 있을 것이다. 둘째, 여성 화자 50명을 대상으로 어음의 역동범위와 장기평균어음스펙트럼의 평균값을 기준으로 국제어음시험신호와 비교를 하였지만 개인에 따른 변이성(variability)이 존재할 수 있는 가능성이 있다. 이 부분을 확인해 보기 위해 한국어 어음 샘플의 그룹을 무작위 5그룹(각 그룹당 10명)으로 나누어 평균을 구하고 통계적으로 비교해보았다(Tables 1, 2, Figures 5, 6). 이러한 방법은 Healy, Yoho와 Apoux (2013)의 연구에서도 사용된 방법으로 55명의 여성 화자를 대상으로 주파수 별 주파수중요도함수(band-importance function)를 구하는 과정에서 무작위 4그룹으로 나누어서 개인에 따른 변이성을 확인하였다.
Table 1.
Values of minimum level (L30) for each of the five groups
Table 2.
Values of maximum level (L99) for each of the five groups
Figure 5에서는 각 그룹별 최소어음레벨(L30)과 최대어음레벨(L99)의 평균을 나타내고 있다. 각 중심주파수에서(150, 250, 350, 450, 570, 700, 840, 1,000, 1,170, 1,370, 1,600, 1,850, 2,150, 2,500, 2,900, 3,400, 4,000, 4,800, 5,800, 7,000, 8,500 Hz) 일원배치분산분석(one-way ANOVA)을 통해 각 그룹별로 최소어음레벨(L30)과 최대어음레벨(L99)이 통계적으로 유의미한 차이가 있는지 분석하였다. 결과적으로, 전 주파수 대역에서 최소어음레벨(L30)과 최대어음레벨(L99)은 그룹별로 유의미한 차이가 없는 것으로 나타났다(p>.05). Figure 5에서 볼 수 있듯이 최소어음레벨(L30)에서 가장 큰 평균값의 차이를 보인 중심주파수는 150 Hz (범위: 46.98–52.58 dB)였고, 최대어음레벨(L99)에서 가장 큰 평균값의 차이를 보인 중심주파수는 3,400 Hz (범위: 36.55–42.4 dB)였다. Bonferroni 사후분석 결과, 최소어음레벨(L30)은 150 Hz에서 Group 2와 Group 5가 유의확률 p =.284로 제일 작은 수치를 보였고, 최대어음레벨(L99)은 3,400 Hz에서 Group 2와 Group 3이 유의확률 p =.061로 제일 작은 수치를 보였다. 즉, 무작위로 그룹을 나누어 최소어음레벨(L30)과 최대어음레벨(L99) 값들을 통계적으로 비교해 본 결과, 전 주파수 대역에서 유의미한 차이를 보이는 주파수는 존재하지 않았으므로, 한국어 어음 샘플의 최소어음레벨(L30) 평균값과 최대어음레벨(L99) 평균값은 변이성이 적은 것으로 해석할 수 있다.
Figure 5.
Maximum and minimum levels of dynamic range for Korean speech stimuli for each of the five groups as a function of 21 band frequencies.
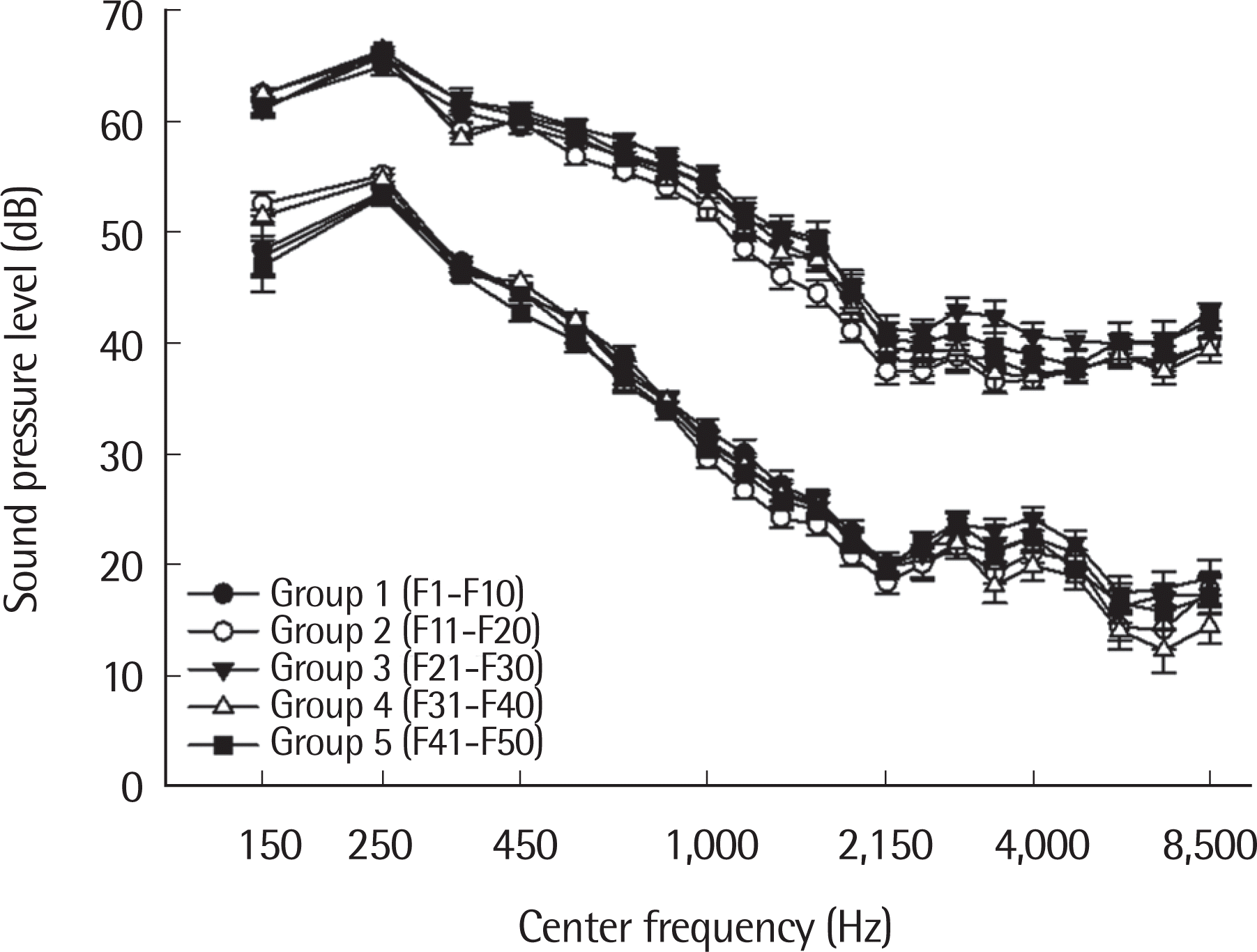
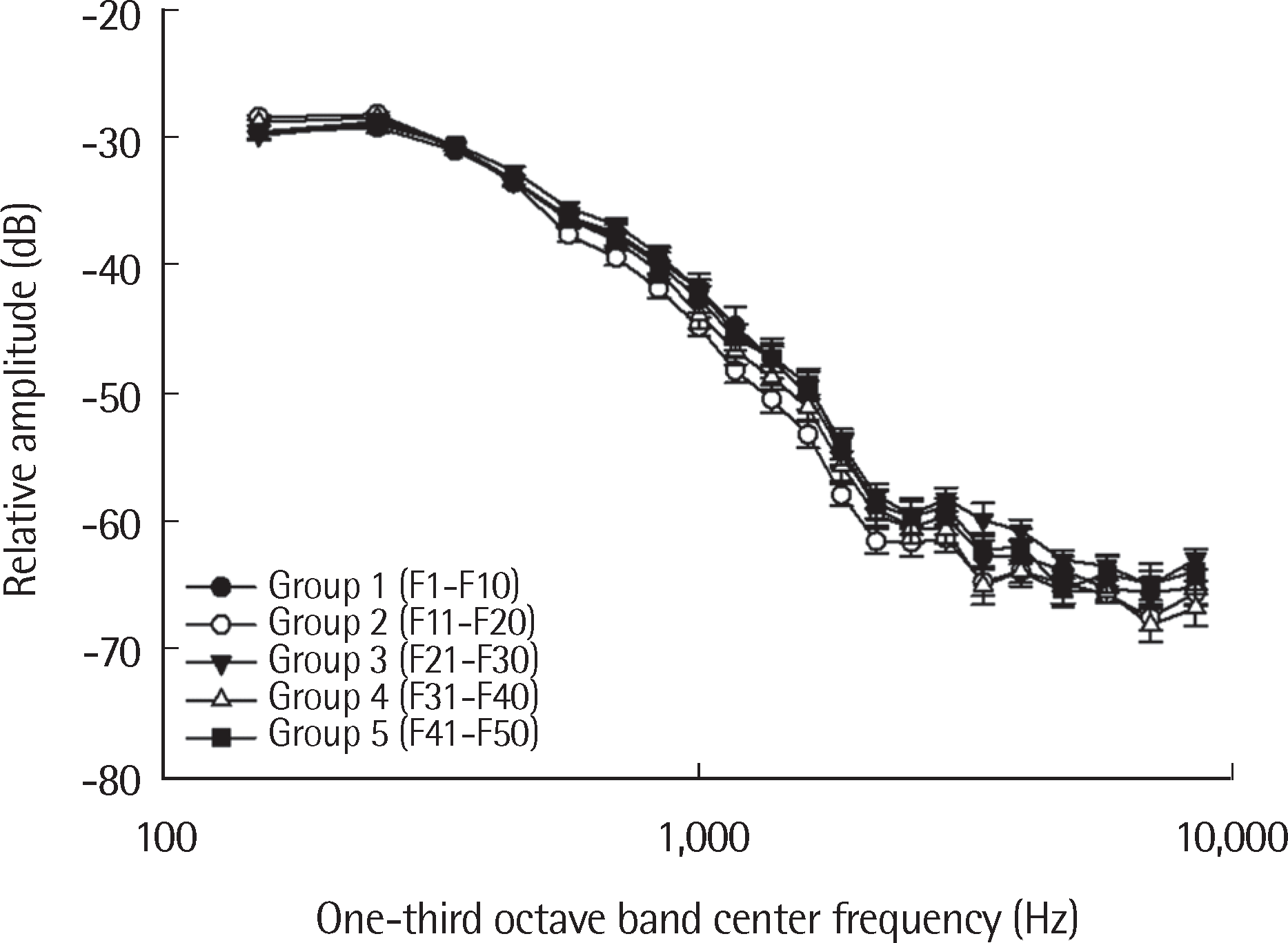
Figure 6에서는 각 그룹별 장기평균어음스펙트럼 평균을 나타내고 있다. 각 중심주파수에서(150, 250, 350, 450, 570, 700, 840, 1,000, 1,170, 1,370, 1,600, 1,850, 2,150, 2,500, 2,900, 3,400, 4,000, 4,800, 5,800, 7,000, 8,500 Hz) 일원배치분산분석(one-way ANOVA)을 통해 각 그룹별로 장기평균어음스펙트럼이 통계적으로 차이가 있는지 분석하였다. 결과적으로, 전 주파수 대역에서 장기평균어음스펙트럼은 그룹별로 유의미한 차이가 없었다(p>.05). Figure 6에서 볼 수 있듯이 장기평균어음스펙트럼에서 가장 큰 평균값의 차이를 보인 중심주파수는 3,400 Hz (범위: −64.99 to −59.87 dB)였다. Bonferroni 사후분석 결과, 3,400 Hz에서 Group 2와 Group 3이 유의확률 p =.104로 제일 작은 수치를 보였다. 즉, 무작위로 그룹을 나누어 장기평균어음스펙트럼값을 통계적으로 비교해 본 결과, 전 주파수 대역에서 유의미한 차이를 보이는 주파수는 존재하지 않았으므로, 한국어 어음 샘플의 장기평균어음스펙트럼 평균값 또한 변이성이 적은 것으로 해석할 수 있다.
결론
한국어 어음 샘플과 국제어음시험신호의 어음역동범위를 비교한 결과 전 주파수 대역에서 한국어 어음 샘플이 국제어음시험신호보다 더 좁은 어음역동범위를 가지고 있었다. 또한, 장기평균어음스펙트럼을 비교한 결과 1,600 Hz를 기준으로 저주파수 대역에서는 한국어 어음 샘플이 국제어음시험신호보다 더 높은 레벨을 보였으며 고주파수 대역에서는 국제어음시험신호가 한국어 어음 샘플보다 더 높은 레벨을 보이는 것으로 나타났다. 즉, 본 연구의 결과는 국제어음시험신호가 한국어 어음 자극의 음향학적 특징을 반영하지 못하는 것을 보여준다. 그러므로, 한국인을 대상으로 보청기의 평가 및 적합을 시행할 때에는 국제어음시험신호보다 추후 한국어 기반의 신호음이 적용되었을 때, 더욱 정확한 평가 및 적합 결과를 산출할 수 있을 것이다.


